基于emp表指定列,创建视图emp_view_2,该视图包含编号/姓名/工资/年薪/年收入(查询中使用列别名) createview emp_view_2 as select empno "编号",ename "姓名",sal "工资",sal*12 "年薪",sal*12+NVL(comm,0) "年收入" from emp;
基于emp表指定列,创建视图emp_view_3(a,b,c,d,e),包含编号/姓名/工资/年薪/年收入(视图中使用列名) createview emp_view_3(a,b,c,d,e) as select empno "编号",ename "姓名",sal "工资",sal*12 "年薪",sal*12+NVL(comm,0) "年收入" from emp;
查询emp_view_3创建视图的结构 desc emp_view_3;
修改emp_view_3(id,name,salary,annual,income)视图,createor replace view 视图名 as 子查询 createor replace view emp_view_3(id,name,salary,annual,income) as select empno "编号",ename "姓名",sal "工资",sal*12 "年薪",sal*12+NVL(comm,0) "年收入" from emp;
查询emp表,求出各部门的最低工资,最高工资,平均工资 selectmin(sal),max(sal),round(avg(sal),0),deptno from emp groupby deptno;
创建视图emp_view_4,视图中包含各部门的最低工资,最高工资,平均工资 createor replace view emp_view_4 as select deptno "部门号",min(sal) "最低工资",max(sal) "最高工资",round(avg(sal),0) "平均工资" from emp groupby deptno;
创建视图emp_view_5,视图中包含员工编号,姓名,工资,部门名,工资等级 createor replace view emp_view_5 as select e.empno "编号",e.ename "姓名",e.sal "工资",d.dname "部门名",s.grade "工资等级" from emp e,dept d,salgrade s where (e.deptno=d.deptno) and (e.sal between s.losal and s.hisal);
删除视图emp_view_1中的7788号员工的记录,使用delete操作,会影响基表吗 deletefrom emp_view_1 where empno=7788;写法正确,会影响基表
修改emp_view_1为只读视图【with read only】,再执行上述delete操作,还行吗? createor replace view emp_view_1 as select*from emp with read only; 不能进行delete操作了
为emp表的empno单个字段,创建索引emp_empno_idx,叫单列索引,create index 索引名 on 表名(字段,...) create index emp_empno_idx on emp(empno);
为emp表的ename,job多个字段,创建索引emp_ename_job_idx,多列索引/联合索引 create index emp_ename_job_idx on emp(ename,job); 如果在where中只出现job不使用索引 如果在where中只出现ename使用索引 我们提倡同时出现ename和job
》用sys登录,查询当前Oracle数据库服务器中已有用户的名字和状态 username表示登录名 expired&locked表示帐号过期和锁定 open表示帐号现在可用 sqlplus /as sysdba; col username for a30; col account_status for a30; set pagesize 100; select username,account_status from dba_users; 查询Oracle中有哪些用户 select*from all_users;
》用sys登录,查询c##tiger所拥有的对象权限 sqlplus /as sysdba; col grantee for a10; col table_name for a10; col privilege for a20; select grantee,table_name,privilege from dba_tab_privs wherelower(grantee) ='c##tiger';
SELECT* INTO new_table_name [IN externaldatabase] FROM old_tablename
1 2 3 4 5
/*从 "Persons" 表中提取居住在 "Beijing" 的人的信息,创建了一个带有两个列的名为 "Persons_backup" 的表*/ SELECT LastName,Firstname INTO Persons_backup FROM Persons WHERE City='Beijing'
My SQL / SQL Server / Oracle / MS Access: CREATE TABLE Persons ( Id_P int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255) DEFAULT ‘Sandnes’ ) 通过使用类似 GETDATE() 这样的函数,DEFAULT 约束也可以用于插入系统值:
CREATE TABLE Orders ( Id_O int NOT NULL, OrderNo int NOT NULL, Id_P int, OrderDate date DEFAULT GETDATE() ) SQL DEFAULT Constraint on ALTER TABLE /在表已存在的情况下为 “City” 列创建 DEFAULT 约束/ ALTER TABLE Persons ALTER City SET DEFAULT ‘SANDNES’ /需撤销 DEFAULT 约束/ ALTER TABLE Persons ALTER City DROP DEFAULT
publicclassStudent { public String name; publicStudent(String name) { this.name=name; } publicvoidsayName(){ System.out.println("student is name is "+name); } }
初始化其实就是执行类构造器方法的<clinit>()的过程,而且要保证执行前父类的<clinit>()方法执行完毕。这个方法由编译器收集,顺序执行所有类变量(static修饰的成员变量)显式初始化和静态代码块中语句。此时准备阶段时的那个 static int a 由默认初始化的0变成了显式初始化的3. 由于执行顺序缘故,初始化阶段类变量如果在静态代码块中又进行了更改,会覆盖类变量的显式初始化,最终值会为静态代码块中的赋值。
当Eden空间满了之后,会触发一个叫做Minor GC(就是一个发生在年轻代的GC)的操作,存活下来的对象移动到Survivor0区。Survivor0区满后触发 Minor GC,就会将存活对象移动到Survivor1区,此时还会把from和to两个指针交换,这样保证了一段时间内总有一个survivor区为空且to所指向的survivor区为空。经过多次的 Minor GC后仍然存活的对象(这里的存活判断是15次,对应到虚拟机参数为 -XX:MaxTenuringThreshold 。为什么是15,因为HotSpot会在对象投中的标记字段里记录年龄,分配到的空间仅有4位,所以最多只能记录到15)会移动到老年代。老年代是存储长期存活的对象的,占满时就会触发我们最常听说的Full GC,期间会停止所有线程等待GC的完成。所以对于响应要求高的应用应该尽量去减少发生Full GC从而避免响应超时的问题。
现在的商业虚拟机都采用这种收集算法回收新生代,但是并不是划分为大小相等的两块,而是一块较大的 Eden 空间和两块较小的 Survivor 空间,每次使用 Eden 和其中一块 Survivor。在回收时,将 Eden 和 Survivor 中还存活着的对象全部复制到另一块 Survivor 上,最后清理 Eden 和使用过的那一块 Survivor。
在发生 Minor GC 之前,虚拟机先检查老年代最大可用的连续空间是否大于新生代所有对象总空间,如果条件成立的话,那么 Minor GC 可以确认是安全的。
如果不成立的话虚拟机会查看 HandlePromotionFailure 的值是否允许担保失败,如果允许那么就会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试着进行一次 Minor GC;如果小于,或者 HandlePromotionFailure 的值不允许冒险,那么就要进行一次 Full GC。
5.3 Full GC 的触发条件
对于 Minor GC,其触发条件非常简单,当 Eden 空间满时,就将触发一次 Minor GC。而 Full GC 则相对复杂,有以下条件:
1. 调用 System.gc()
只是建议虚拟机执行 Full GC,但是虚拟机不一定真正去执行。不建议使用这种方式,而是让虚拟机管理内存。
2. 老年代空间不足
老年代空间不足的常见场景为前文所讲的大对象直接进入老年代、长期存活的对象进入老年代等。
为了避免以上原因引起的 Full GC,应当尽量不要创建过大的对象以及数组。除此之外,可以通过 -Xmn 虚拟机参数调大新生代的大小,让对象尽量在新生代被回收掉,不进入老年代。还可以通过 -XX:MaxTenuringThreshold 调大对象进入老年代的年龄,让对象在新生代多存活一段时间。
3. 空间分配担保失败
使用复制算法的 Minor GC 需要老年代的内存空间作担保,如果担保失败会执行一次 Full GC。具体内容请参考上面的第 5 小节。
4. JDK 1.7 及以前的永久代空间不足
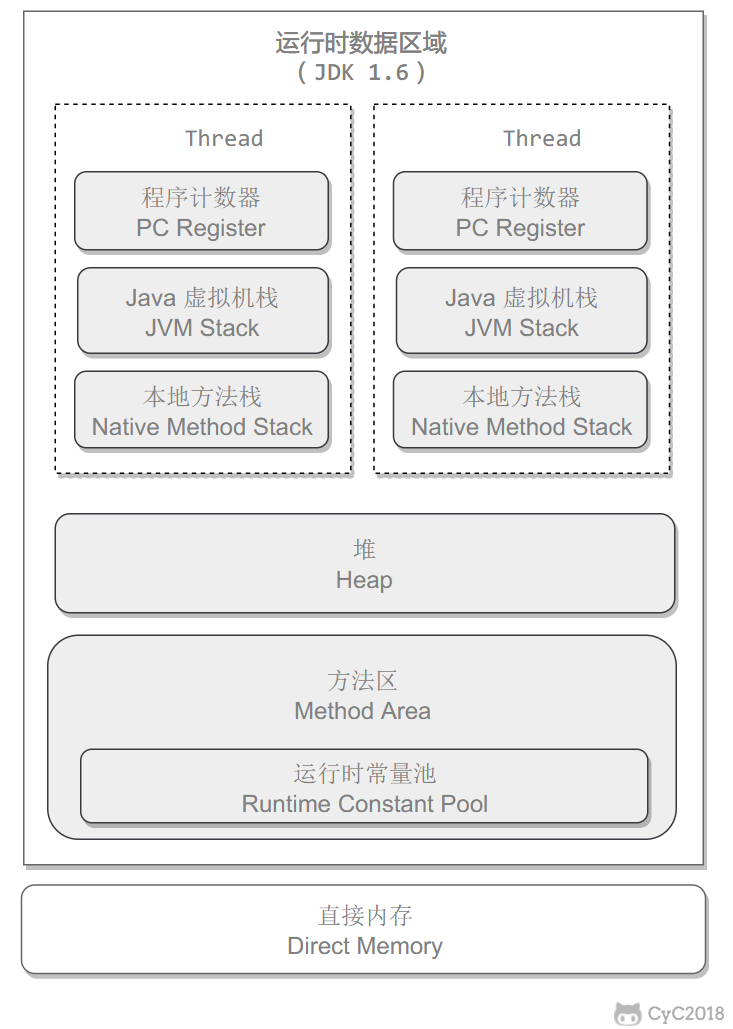
在 JDK 1.7 及以前,HotSpot 虚拟机中的方法区是用永久代实现的,永久代中存放的为一些 Class 的信息、常量、静态变量等数据。
当系统中要加载的类、反射的类和调用的方法较多时,永久代可能会被占满,在未配置为采用 CMS GC 的情况下也会执行 Full GC。如果经过 Full GC 仍然回收不了,那么虚拟机会抛出 java.lang.OutOfMemoryError。
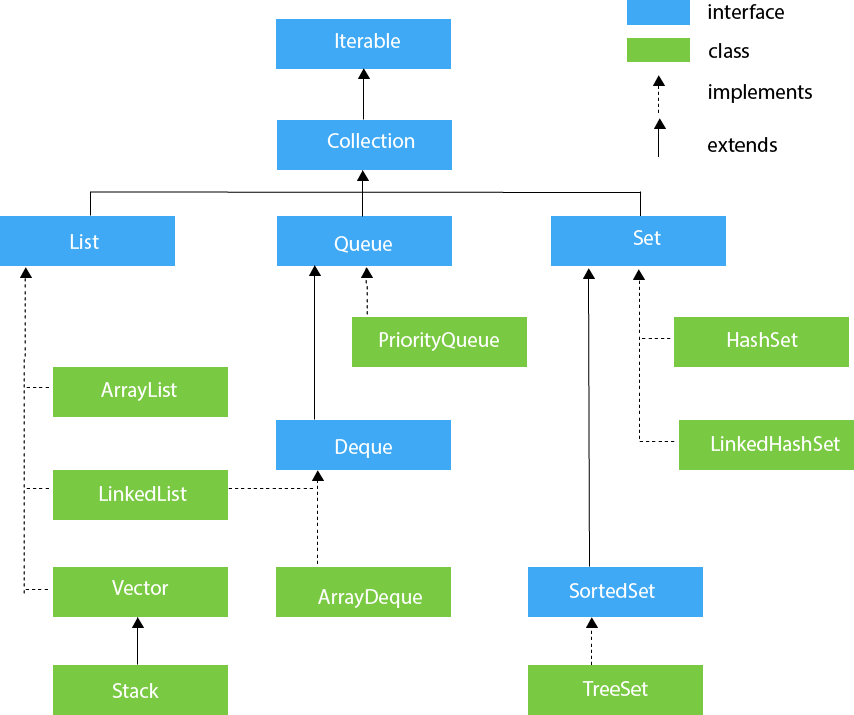
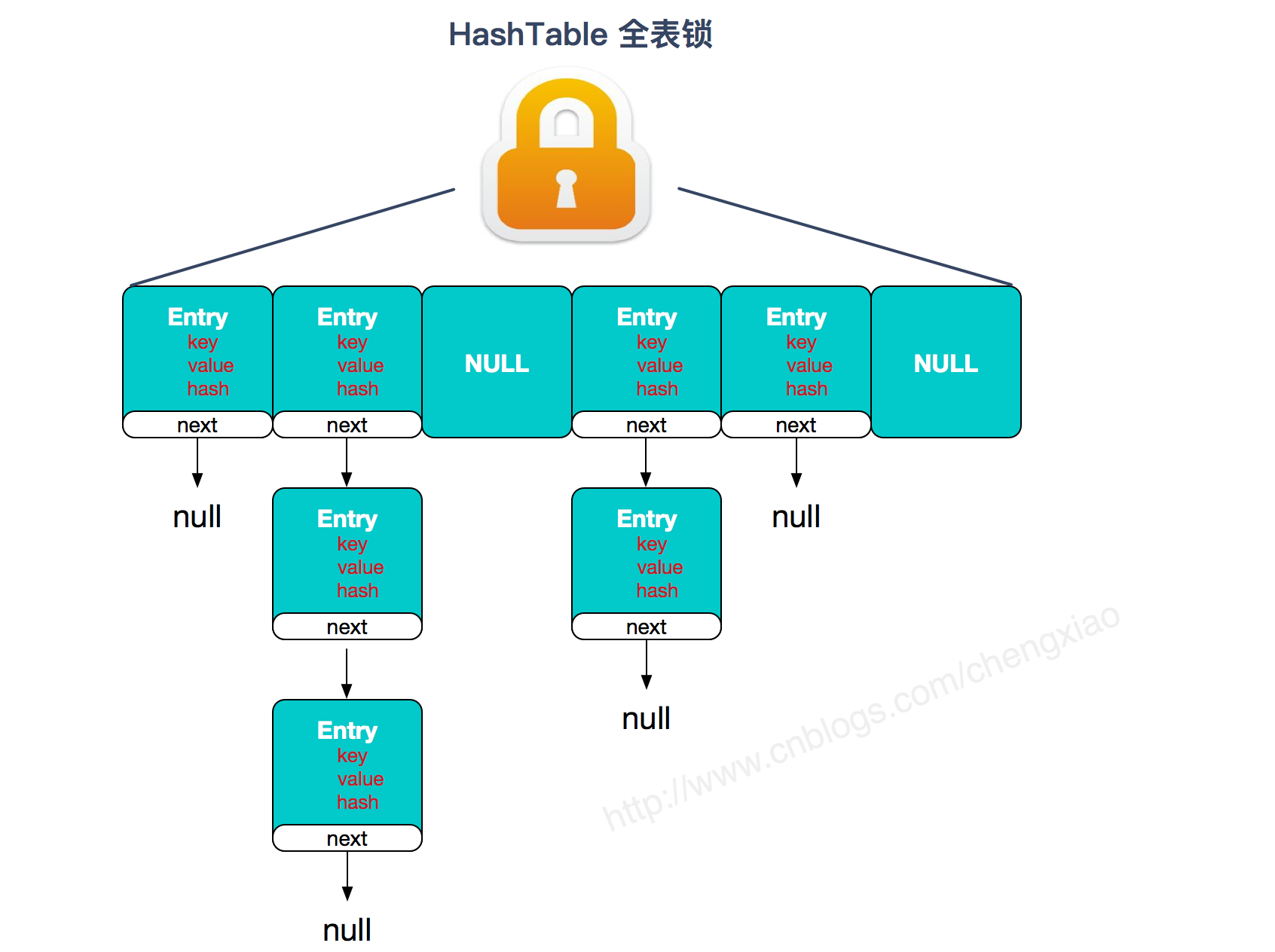
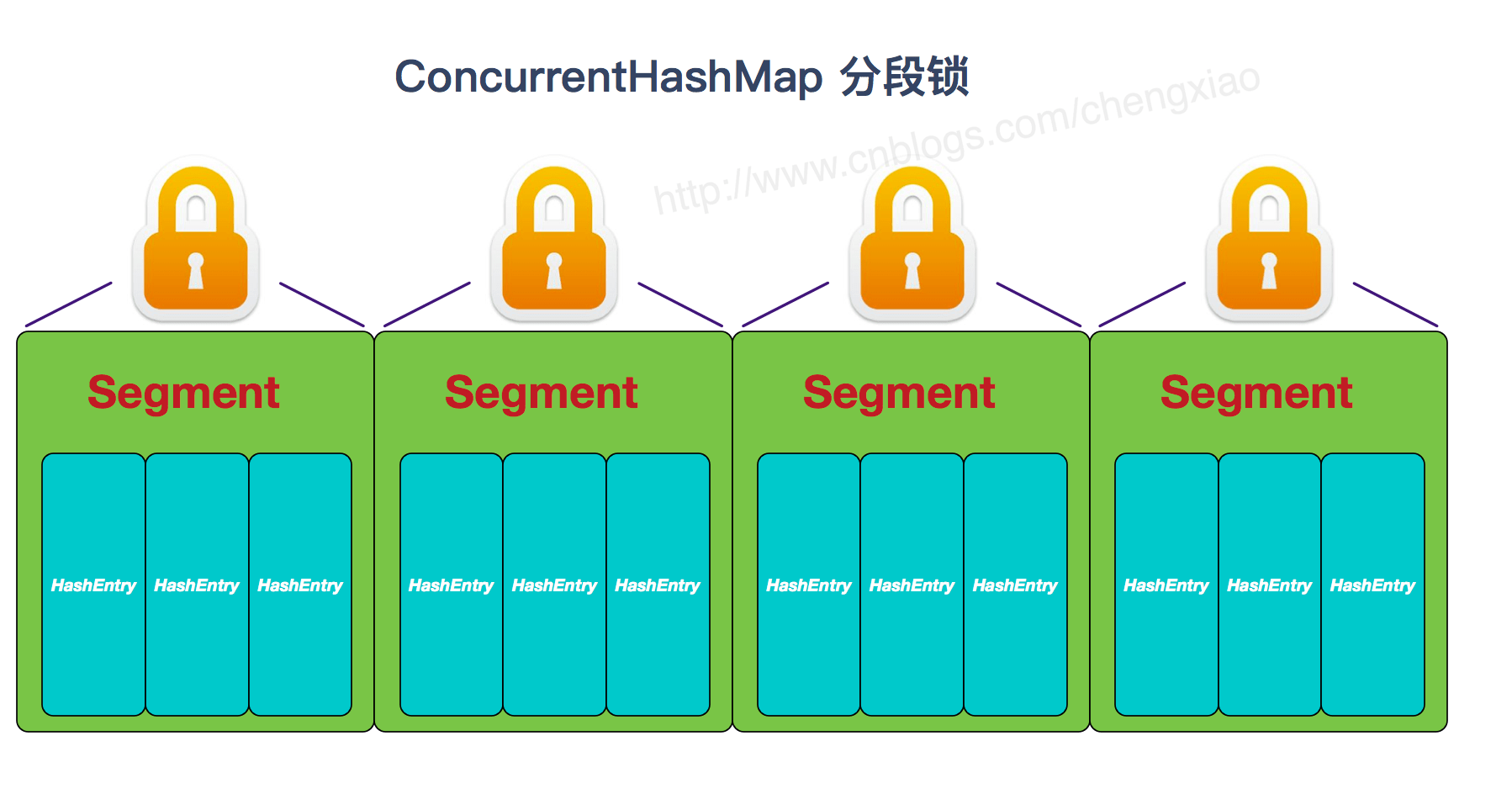
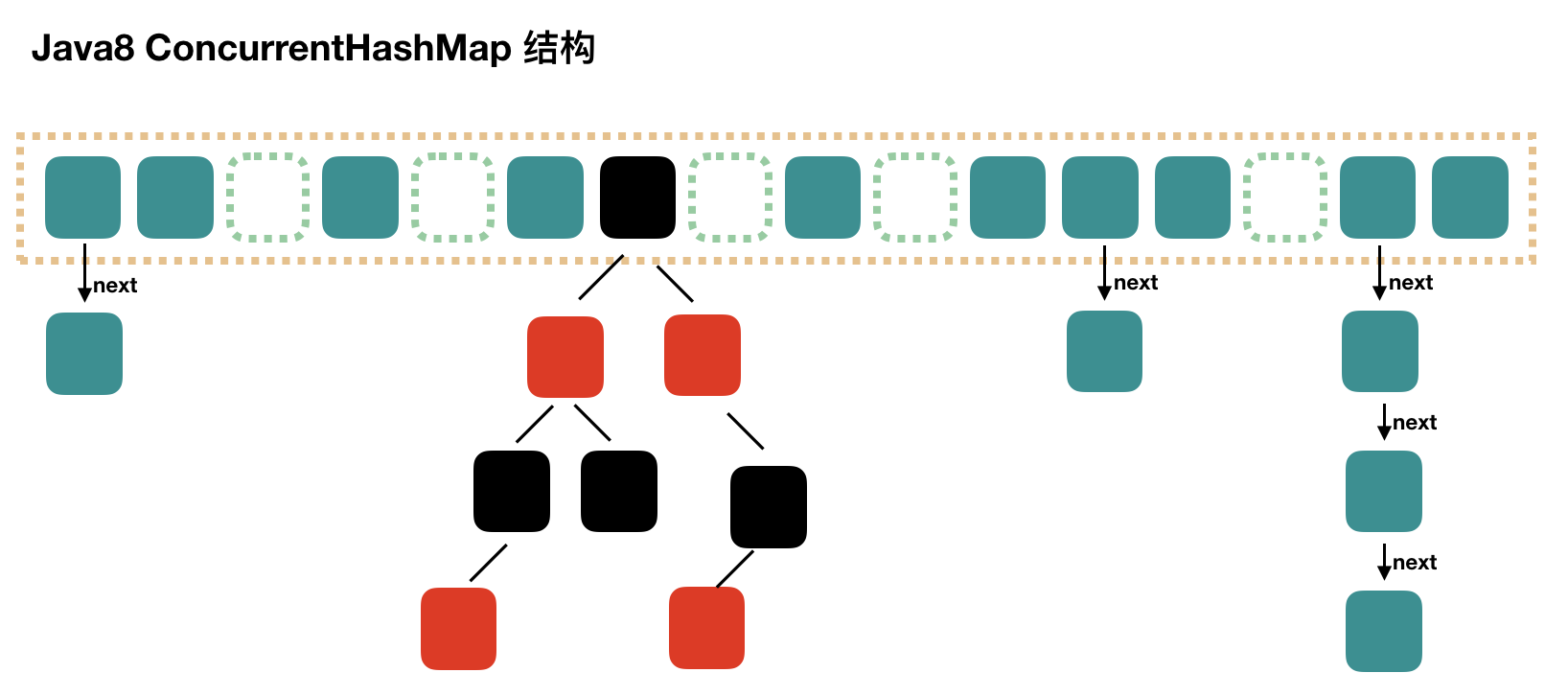
synchronizedCollection(Collection<T> c) //返回指定 collection 支持的同步(线程安全的)collection。 synchronizedList(List<T> list)//返回指定列表支持的同步(线程安全的)List。 synchronizedMap(Map<K,V> m) //返回由指定映射支持的同步(线程安全的)Map。 synchronizedSet(Set<T> s) //返回指定 set 支持的同步(线程安全的)set。