JSP简介 JSP是为了简化Servlet的工作出现的替代品,Servlet输出HTML非常困难,JSP就是替代Servlet输出HTML的。
JSP的响应
浏览器第一次请求1.jsp时,Tomcat会将1.jsp转化成1_jsp.java这么一个类,并将该文件编译成class文件。编译完毕后再运行class文件来响应浏览器的请求。
以后访问1.jsp就不再重新编译jsp文件了,直接调用class文件来响应浏览器。当然了,如果Tomcat检测到JSP页面改动了的话,会重新编译的。
既然JSP是一个Servlet,那JSP页面中的HTML排版标签是怎么样被发送到浏览器的?用write()出去的。说到底,JSP就是封装了Servlet的java程序罢了。
JSP比Servlet更方便更简单的一个重要原因就是:内置了9个对象! 内置对象有:out、session、response、request、config、page、application、pageContext、exception
生命周期 JSP也是Servlet,运行时只有一个实例,JSP初始化和销毁时也会调用Servlet的init()和destroy()方法 。另外,JSP还有自己初始化和销毁的方法
1 2 3 4 5 6 7 public void _jspInit () { _el_expressionfactory = _jspxFactory.getJspApplicationContext(getServletConfig().getServletContext()).getExpressionFactory(); _jsp_instancemanager = org.apache.jasper.runtime.InstanceManagerFactory.getInstanceManager(getServletConfig()); } public void _jspDestroy () {}
语法 JSP代码分为两个部分:
模板数据:HTML代码
元素:JSP页面中的java代码、JSP指令和JSP标签
脚本
JSP的脚本就是JSP页面中的java代码 ,也叫做scriptlet。JSP的脚本必须使用<%%>括起来,不然会被当成是模板数据的! JSP脚本有三种方式:
<%%>【定义局部变量,编写语句】
<%!%>【定义类或方法,但是没人这样用! 】
<%=%>(也称之为表达式输出 )【输出各种类型的变量,int、double、String、Object等】
表达式和变量后面不能有分号(;)
在<% %>中可以定义变量、编写语句,不能定义方法。
如果过多地使用<%%>会导致代码混乱,JSP还提供了一种scriptlet标签,使用此标签和<%%>有相同的功能,只不过它更美观了一些
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <jsp:scriptlet> String s = "HelloWorld" ; out.println(s); </jsp:scriptlet> <%--这是JSP注释--%> <%--%> <% int sum=0 ; for (int i=1 ;i<=100 ;i++){ sum+=i; } out.println("<h1>Sum=" +sum+"</h1>" ); %>
指令 JSP指令用来声明JSP页面的相关属性,例如编码方式、文档类型等等
page指令 page指令可以帮助跳到提示页面或是错误页面上。为了保持程序的可读性和遵循良好的编程习惯,page指令最好是放在整个JSP页面的起始位置。
1 <%@ page contentType ="text/html;charset=UTF-8" language ="java" %>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <%@ page [ language="java" ] [ extends="package.class" ] [ import ="{package.class | package.*}, ..." ] [ session="true | false" ] [ buffer="none | 8kb | sizekb" ] [ autoFlush="true | false" ] [ isThreadSafe="true | false" ] [ info="text" ] [ errorPage="relative_url" ]【通过page指令的errorPage属性跳转到relative_url页面】 [ isErrorPage="true | false" ]【设置页面是否是错误页面】 [ contentType="mimeType [ ;charset=characterSet ]" | "text/html ; charset=ISO-8859-1" ] [ pageEncoding="characterSet | ISO-8859-1" ] [ isELIgnored="true | false" ] %>
一般地,在eclipse或idea这些高级开发工具上开发,我们只需要在page指令中指定contentType=”text/html;charset=UTF-8”,就不会出现中文乱码问题! 当然了contentType 不仅仅可以指定以text/html的方式显示,还可以使用其他的形式显示出来。在conf/web.xml文件中可以查询出来
import属性
可以在一条page指令的import属性中引入多个类或包,其中的每个包或类之间使用逗号(,)分隔
```jsp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 ### errorPage属性 - rrorPage属性的设置值必须使用相对路径,如果以“/”开头,表示相对于当前Web应用程序的根目录(注意不是站点根目录),否则,表示相对于当前页面 - 可以在web.xml文件中使用\<error-page\>元素为整个Web应用程序设置错误处理页面。 - \<error-page\>元素有3个子元素,\<error-code\>、\<exception-type\>、\<location\> - \<error-code\>子元素指定错误的状态码,例如:\<error-code\>404\</error-code\> - \<exception-type\>子元素指定异常类的完全限定名,例如:\<exception-type\>java.lang.ArithmeticException\</exception-type\> - \<location > 子元素指定以“/”开头的错误处理页面的路径,例如:\<location\>/ErrorPage/404Error.jsp\</location\> - 如果设置了某个JSP页面的errorPage属性,那么在web.xml文件中设置的错误处理将不对该页面起作用。 web.xml的代码下: ```xml <?xml version="1.0" encoding="UTF-8" ?> <web-app version ="3.0" xmlns ="http://java.sun.com/xml/ns/javaee" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd" > <display-name > </display-name > <welcome-file-list > <welcome-file > index.jsp</welcome-file > </welcome-file-list > <error-page > <error-code > 404</error-code > <location > /ErrorPage/404Error.jsp</location > </error-page > </web-app >
404Error.jsp代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 <%@ page language="java" import ="java.util.*" pageEncoding="UTF-8" %> <html> <head> <title>404 错误友好提示页面</title> <!-- 3 秒钟后自动跳转回首页 --> <meta http-equiv="refresh" content="3;url=${pageContext.request.contextPath}/index.jsp" > </head> <body> <img alt="对不起,你要访问的页面没有找到,请联系管理员处理!" src="${pageContext.request.contextPath}/img/404Error.png" /><br/> 3 秒钟后自动跳转回首页,如果没有跳转,请点击<a href="${pageContext.request.contextPath}/index.jsp" >这里</a> </body> </html>
include指令 在JSP中对于包含有两种语句形式:
@include指令
jsp:include 指令
include指令是静态包含 。静态包含的意思就是:把文件的代码内容都包含进来,再编译!
include指令细节注意问题:
被引入的文件必须遵循JSP语法。 被引入的文件可以使用任意的扩展名,即使其扩展名是html,JSP引擎也会按照处理jsp页面的方式处理它里面的内容,为了见明知意,JSP规范建议使用.jspf(JSP fragments(片段))作为静态引入文件的扩展名。 由于使用include指令将会涉及到2个JSP页面,并会把2个JSP翻译成一个servlet,所以这2个JSP页面的指令不能冲突(除了pageEncoding和导包除外)。
在1.jsp中把页头和页尾包含进来:
1 2 3 4 5 6 7 8 9 10 <%@ page contentType="text/html;charset=UTF-8" language="java" %> <html> <head> <title>包含页头和页尾进来</title> </head> <body> <%@include file="head.jsp" %> <%@include file="foot.jsp" %> </body> </html>
taglib指令 用来说明JSP页面内使用的标签库
行为(内置标签)
JSP行为(JSP Actions)是一组JSP内置的标签 ,只书写少量的标记代码就能够使用JSP提供丰富的功能,JSP行为是对常用的JSP功能的抽象和封装 。
jsp的常用标签有以下三个
include标签
1 2 3 <jsp:include page="relativeURL | <%=expression%>" flush="true|false" /> page属性用于指定被引入资源的相对路径,它也可以通过执行一个表达式来获得。 flush属性指定在插入其他资源的输出内容时,是否先将当前JSP页面的已输出的内容刷新到客户端。
jsp标签包含文件就是先编译被包含的页面,再将页面的结果写入到包含的页面中 ————属于动态包含
include标签和include指令的区别 <jsp:include>标签是动态引入, <jsp:include>标签涉及到的2个JSP页面会被翻译成2个servlet,这2个servlet的内容在执行时进行合并。
param标签
当使用<jsp:include>和<jsp:forward>标签引入或将请求转发给其它资源时,可以使用<jsp:param>标签向这个资源传递参数。
forward标签 <jsp:forward>标签用于把请求转发给另外一个资源。
directive标签
directive的中文意思就是指令 。该行为就是替代指令<%@%>的语法的
<jsp:directive.include file=””/> 相当于<%@include file=”” %>
<jsp:directive.page/> 相当于<%@page %>
<jsp:directive.taglib/> 相当于<%@taglib %>
内置对象 每个JSP 页面在第一次被访问时,WEB容器都会把请求交给JSP引擎(即一个Java程序)去处理。JSP引擎先将JSP翻译成一个_jspServlet(实质上也是一个servlet) ,然后按照servlet的调用方式进行调用。
九个内置对象:
NO.
内置对象
类型
1
pageContext javax.servlet.jsp.PageContext
2
request javax.servlet.http.HttpServletRequest
3
response javax.servlet.http.HttpServletResponse
4
session javax.servlet.http.HttpSession
5
application javax.servlet.ServletContext
6
config javax.servlet.ServletConfig
7
out
javax.servlet.jsp.JspWriter
8
page
java.lang.Object
9
exception
java.lang.Throwable
————无需定义,即可直接使用
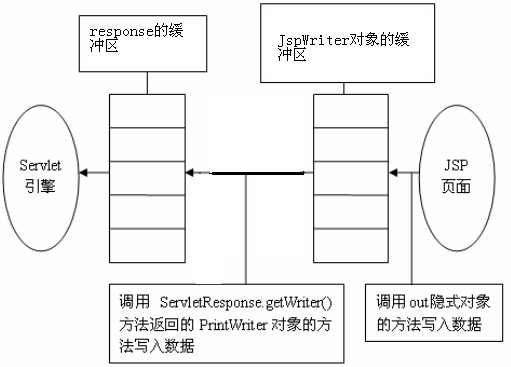
out对象 out对象的API
1 2 3 4 5 6 7 8 int getBufferSize () 【得到缓存大小】int getRemaining () 【得到未使用缓存的大小】boolean isAutoFlush () void println () void flush () void close () void clearBuffer () void clear ()
out对象用于向客户端发送文本数据。
out对象是通过调用pageContext对象的getOut方法返回的,其作用和用法与ServletResponse.getWriter方法返回的PrintWriter对象非常相似。
JSP页面中的out对象的类型为JspWriter,JspWriter相当于一种带缓存功能的PrintWriter,设置JSP页面的page指令的buffer属性可以调整它的缓存大小,甚至关闭它的缓存。
只有向out对象中写入了内容,且满足如下任何一个条件时,out对象才去调用ServletResponse.getWriter方法,并通过该方法返回的PrintWriter对象将out对象的缓冲区中的内容真正写入到Servlet引擎提供的缓冲区中:
设置page指令的buffer属性关闭了out对象的缓存功能
out对象的缓冲区已满
整个JSP页面结束
out对象的原理如下:
只有向out对象中写入了内容,且满足如下任何一个条件时,out对象才去调用ServletResponse.getWriter方法 ,并通过该方法返回的PrintWriter对象将out对象的缓冲区中的内容真正写入到Servlet引擎提供的缓冲区中 :
设置page指令的buffer属性关闭了out对象的缓存功能 out对象的缓冲区已满 整个JSP页面结束
一般我们在JSP页面输出都是用表达式(<%=%>),所以out对象用得并不是很多 !
page对象 内置对象page是HttpJasPage对象,其实page对象代表的就是当前JSP页面,是当前JSP编译后的Servlet类的对象 。也就是说:page对象相当于普通java类的this
在开发中几乎不用
exception对象
内置对象exception是java.lang.Exception类的对象,exception封装了JSP页面抛出的异常信息。 exception经常被用来处理错误页面
pageContext对象 pageContext是内置对象中最重要的一个对象,它代表着JSP页面编译后的内容(也就是JSP页面的运行环境)!
pageContext获取8个内置对象 既然它代表了JSP页面编译后的内容,理所当然的:它封装了对其他8大内置对象的引用! ,也就是说,通过pageContext可以获取到其他的8个内置对象!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 <%@ page contentType="text/html;charset=UTF-8" language="java" %> <html> <head> <title>获取八大内置对象</title> </head> <body> <% System.out.println(pageContext.getSession()); System.out.println(pageContext.getRequest()); System.out.println(pageContext.getResponse()); System.out.println(pageContext.getException()); System.out.println(pageContext.getPage()); System.out.println(pageContext.getServletConfig()); System.out.println(pageContext.getServletContext()); System.out.println(pageContext.getOut()); %> </body> </html>
pageContext作为域对象 类似于request,session,ServletContext作为域对象而言都有以下三个方法 :
1 2 3 4 1 、setAttribute(String name,Objcet o)2 、getAttribute(String name)3 、removeAttribute(String name)
当然了,pageContext也不例外,pageContext也有这三个方法 !
pageContext本质上代表的是当前JSP页面编译后的内容,作为域对象而言,它就代表着当前JSP页面(也就是page) !也就是说:pageContext域对象只在page范围内有效,超出了page范围就无效了 !
findAttribute(String name)方法介绍:
该方法是用于查找各个域中的属性的。当要查找某个属性时,findAttribute方法按照查找顺序”page→request→session→application”在这四个对象中去查找,只要找到了就返回属性值,如果四个对象都没有找到要查找的属性,则返回一个null。
pageContext对象中封装了访问其它域的方法:
1 2 3 1 public java.lang.Object getAttribute (java.lang.String name,int scope) 2 public void setAttribute (java.lang.String name, java.lang.Object value,int scope) 3 public void removeAttribute (java.lang.String name,int scope)
代表各个域的常量
1 2 3 4 1 PageContext.APPLICATION_SCOPE2 PageContext.SESSION_SCOPE3 PageContext.REQUEST_SCOPE4 PageContext.PAGE_SCOPE
PageContext引入和跳转到其他资源 PageContext类中定义了一个forward方法(用来跳转页面)和两个include方法(用来引入页面)来分别简化和替代RequestDispatcher.forward方法和include方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 <%@page contentType="text/html;charset=UTF-8" %> <%@page import ="java.util.*" %> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" > <head> <title>使用pageContext的forward方法跳转页面</title> </head> <% pageContext.forward("/pageContextDemo05.jsp" ); %>
使用include方法引入资源:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <%@ page language="java" import ="java.util.*" pageEncoding="UTF-8" %> <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" > <head> <title>使用pageContext的include方法引入资源</title> </head> <% pageContext.include("/jspfragments/head.jsp" ); %> 使用pageContext的include方法引入资源 <% pageContext.include("/jspfragments/foot.jsp" ); %> <hr/> <%-- <jsp:include page="/jspfragments/head.jsp" /> 使用jsp:include标签引入资源 <jsp:include page="/jspfragments/foot.jsp" /> --%>
其他对象 request对象
内置对象request其实就是HttpServletRequest
response对象
内置对象response其实就是HttpServletResponse
config对象
内置对象config其实就是ServletConfig
session对象
内置对象session其实就是HttpSession。
注意:在page指令配置如下信息,session将不可使用
1 <%@page session="false" %>
application对象
内置对象application其实就是ServletContext对象
四种属性范围
page【只在一个页面中保存属性,跳转页面无效】 request【只在一次请求中保存属性,服务器跳转有效,浏览器跳转无效】 session【在一个会话范围中保存属性,无论何种跳转均有效,关闭浏览器后无效】 application【在整个服务器中保存,所有用户都可以使用】
4个内置对象都支持以下的方法:
No.
方法
描述
1
public void setAttribute(String name,Object value)
设置属性
2
public object getAttribute(String name)
取得属性
3
public void removeAttribute(String name)
删除属性
使用场景 1、request:如果客户向服务器发请求,产生的数据,用户看完就没用了,像这样的数据就存在request域,像新闻数据,属于用户看完就没用的。
JavaBean JavaBean遵循着特定的写法,通常有以下的规则:
有无参的构造函数 成员属性私有化 封装的属性如果需要被外所操作,必须编写public类型的setter、getter方法
————就是普通的java类。
在jsp中使用javabean
<jsp:useBean>【在JSP页面中查找javaBean对象或者实例化javaBean对象】
<jsp:setProperty>【设置javaBean的属性】
<jsp:getProperty>【获取javaBean的属性】
jsp:useBean
1 2 3 4 <jsp:useBean id="beanName" class="package.class" scope="page|request|session|application" /> "id" 属性用于指定JavaBean实例对象的引用名称和其存储在域范围中的名称。 "class" 属性用于指定JavaBean的完整类名(即必须带有包名)。 "scope" 属性用于指定JavaBean实例对象所存储的域范围,其取值只能是page、request、session和application等四个值中的一个,其默认值是page。
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 如果JSP不支持`<jsp:useBean>`这个行为,我们要使用Person类是这样使用的: <%--这里需要导入Person类--%> <%@ page import ="domain.Person" %> <%@ page contentType="text/html;charset=UTF-8" language="java" %> <html> <head> <title></title> </head> <body> <% Person person = new Person (); person.setName("zhongfucheng" ); System.out.println(person.getName()); %> </body> </html> 使用<jsp:useBean>: <%@ page contentType="text/html;charset=UTF-8" language="java" %> <html> <head> <title></title> </head> <body> <jsp:useBean id="person" class="domain.Person" scope="page" /> <% person.setName("zhongfucheng" ); System.out.println(person.getName()); %> </body> </html>
jsp:setProperty
1 <jsp:setProerty name="对象名称" property="属性名" param="参数名" value="值" >
jsp:getProperty <jsp:getProperty>标签用于读取JavaBean对象的属性,也就是调用JavaBean对象的getter方法,然后将读取的属性值转换成字符串后插入进输出的响应正文中。
语法:
1 <jsp:getProperty name="对象名" property="属性名" />
EL表法式 主要用于读取数据,进行内容的显示。
语法:
EL表达式如果找不到相应的对象属性,返回的的空白字符串“”,而不是null,这是EL表达式最大的特点 。
获取数据 EL表达式语句在执行时,会调用pageContext.findAttribute方法,用标识符为关键字,分别从page、request、session、application四个域中查找相应的对象,找到则返回相应对象,找不到则返回”” (注意,不是null,而是空字符串)。
EL表达式可以很轻松获取JavaBean的属性,或获取数组、Collection、Map类型集合的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 <%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%> <%@taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %> <%@page import="me.gacl.domain.Person"%> <%@page import="me.gacl.domain.Address"%> <!DOCTYPE HTML > <html > <head > <title > el表达式获取数据</title > </head > <body > <% request.setAttribute("name","孤傲苍狼"); %> <%--${name}等同于pageContext.findAttribute("name") --%> 使用EL表达式获取数据:${name} <hr > <% Person p = new Person(); p.setAge(12); request.setAttribute("person",p); %> 使用el表达式可以获取bean的属性:${person.age} <hr > <% Person person = new Person(); Address address = new Address(); person.setAddress(address); request.setAttribute("person",person); %> ${person.address.name} <hr > <% Person p1 = new Person(); p1.setName("孤傲苍狼"); Person p2 = new Person(); p2.setName("白虎神皇"); List<Person > list = new ArrayList<Person > (); list.add(p1); list.add(p2); request.setAttribute("list",list); %> ${list[1].name} <c:forEach var ="person" items ="${list}" > ${person.name} </c:forEach > <hr > <% Map<String,String> map = new LinkedHashMap<String,String>(); map.put("a","aaaaxxx"); map.put("b","bbbb"); map.put("c","cccc"); map.put("1","aaaa1111"); request.setAttribute("map",map); %> ${map.c} ${map["1"]} <hr > <c:forEach var ="me" items ="${map}" > ${me.key}=${me.value}<br /> </c:forEach > <hr > </body > </html >
执行运算 支持关系运算符和逻辑运算符。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 <%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%> <%@taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %> <%@page import="me.gacl.domain.User"%> <!DOCTYPE HTML > <html > <head > <title > el表达式运算符</title > </head > <body > <h3 > el表达式进行四则运算:</h3 > 加法运算:${365+24}<br /> 减法运算:${365-24}<br /> 乘法运算:${365*24}<br /> 除法运算:${365/24}<br /> <h3 > el表达式进行关系运算:</h3 > <%--${user == null}和 ${user eq null}两种写法等价--%> ${user == null}<br /> ${user eq null}<br /> <h3 > el表达式使用empty运算符检查对象是否为null(空)</h3 > <% List<String > list = new ArrayList<String > (); list.add("gacl"); list.add("xdp"); request.setAttribute("list",list); %> <%--使用empty运算符检查对象是否为null(空) --%> <c:if test ="${!empty(list)}" > <c:forEach var ="str" items ="${list}" > ${str}<br /> </c:forEach > </c:if > <br /> <% List<String > emptyList = null; %> <%--使用empty运算符检查对象是否为null(空) --%> <c:if test ="${empty(emptyList)}" > 对不起,没有您想看的数据 </c:if > <br /> <h3 > EL表达式中使用二元表达式</h3 > <% session.setAttribute("user",new User("孤傲苍狼")); %> ${user==null? "对不起,您没有登陆 " : user.username} <br /> <h3 > EL表达式数据回显</h3 > <% User user = new User(); user.setGender("male"); //数据回显 request.setAttribute("user",user); %> <input type ="radio" name ="gender" value ="male" ${user.gender =='male' ?'checked ': ''}> 男 <input type ="radio" name ="gender" value ="female" ${user.gender =='female' ?'checked ': ''}> 女 <br /> 65 </body > </html >
EL表达式11个内置对象 EL表达式主要是来对内容的显示,为了显示的方便,EL表达式提供了11个内置对象。
pageContext 对应于JSP页面中的pageContext对象(注意:取的是pageContext对象)
pageScope 代表page域中用于保存属性的Map对象
requestScope 代表request域中用于保存属性的Map对象
sessionScope 代表session域中用于保存属性的Map对象
applicationScope 代表application域中用于保存属性的Map对象
param 表示一个保存了所有请求参数的Map对象
paramValues表示一个保存了所有请求参数的Map对象,它对于某个请求参数,返回的是一个string[]
header 表示一个保存了所有http请求头字段的Map对象
headerValues同上,返回string[]数组。
cookie 表示一个保存了所有cookie的Map对象
initParam 表示一个保存了所有web应用初始化参数的map对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 <%--pageContext内置对象--%> <% pageContext.setAttribute("pageContext1" , "pageContext" ); %> pageContext内置对象:${pageContext.getAttribute("pageContext1" )} <br> <%--pageScope内置对象--%> <% pageContext.setAttribute("pageScope1" ,"pageScope" ); %> pageScope内置对象:${pageScope.pageScope1} <br> <%--requestScope内置对象--%> <% request.setAttribute("request1" ,"reqeust" ); %> requestScope内置对象:${requestScope.request1} <br> <%--sessionScope内置对象--%> <% session.setAttribute("session1" , "session" ); %> sessionScope内置对象:${sessionScope.session1} <br> <%--applicationScope内置对象--%> <% application.setAttribute("application1" ,"application" ); %> applicationScopt内置对象:${applicationScope.application1} <br> <%--header内置对象--%> header内置对象:${header.Host} <br> <%--headerValues内置对象,取出第一个Cookie--%> headerValues内置对象:${headerValues.Cookie[0 ]} <br> <%--Cookie内置对象--%> <% Cookie cookie = new Cookie ("Cookie1" , "cookie" ); %> Cookie内置对象:${cookie.JSESSIONID.value} <br> <%--initParam内置对象,需要为该Context配置参数才能看出效果【jsp配置的无效!亲测】--%> initParam内置对象:${initParam.name} <br>
自定义标签