POM文件简介
pom 全称:Project Object Model,即项目对象模型。
Maven 把一个项目的结构和内容抽象成一个模型,在 pom.xml 文件中进行声明和描述。所以说 pom.xml 是 Maven 的核心。
pom文件定于了一个maven项目的maven配置,一般pom文件的放在项目或者模块的根目录下。
maven的遵循约定大于配置,约定了如下的目录结构:
| 目录 | 目的 |
|---|---|
| ${basedir} | 存放pom.xml和所有的子目录 |
| ${basedir}/src/main/java | 项目的java源代码 |
| ${basedir}/src/main/resources | 项目的资源,比如说property文件,springmvc.xml |
| ${basedir}/src/test/java | 项目的测试类,比如说Junit代码 |
| ${basedir}/src/test/resources | 测试用的资源 |
| ${basedir}/src/main/scripts | 项目脚本源码的目录 |
| ${basedir}/src/main/webapp/WEB-INF | web应用文件目录,web项目的信息,比如存放web.xml、本地图片、jsp视图页面 |
| ${basedir}/target | 打包输出目录 |
| ${basedir}/target/classes | 编译输出目录 |
| ${basedir}/target/site | 生成文档的目录,可以通过index.html查看项目的文档 |
| ${basedir}/target/test-classes | 测试编译输出目录 |
| Test.java | Maven只会自动运行符合该命名规则的测试类 |
| ~/.m2/repository | Maven默认的本地仓库目录位置 |
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
完整的 pom.xml 文件:
请注意,modelVersion 为 4.0.0 这是目前唯一支持Maven 2和3的POM版本,且是必填项
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
基础配置
一、根元素和必要配置
1 | <project xmlns = "http://maven.apache.org/POM/4.0.0" |
project是pom文件的根元素,project下有modelVersion、groupId、artifactId、version、packaging等重要的元素。其中,groupId、artifactId、version三个元素用来定义一个项目的坐标,也就是说,一个maven仓库中,完全相同的一组groupId、artifactId、version,只能有一个项目。
- project:整个pom配置文件的根元素,所有的配置都是写在project元素里面的;
- modelVersion:指定了当前POM模型的版本,对于Maven2及Maven 3来说,它只能是4.0.0;
- groupId:这是项目组的标识。它在一个组织或者项目中通常是唯一的。
- artifactId:这是项目的标识,通常是工程的名称。它在一个项目组(group)下是唯一的。
- version:这是项目的版本号,用来区分同一个artifact的不同版本。
- packaging:这是项目产生的构件类型,即项目通过maven打包的输出文件的后缀名,包括jar、war、ear、pom等。
二、父项目和parent元素
maven 支持继承功能。子 POM 可以使用 parent 指定父 POM ,然后继承其配置。
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
- relativePath - 注意
relativePath元素。在搜索本地和远程存储库之前,它不是必需的,但可以用作 maven 的指示符,以首先搜索给定该项目父级的路径。
所有的pom都继承自一个父pom(Super POM)。父pom包含了一些可以被继承的默认设置,如果项目的pom中没有设置这些元素,就会使用父pom中设置。例如,Super POM中配置了默认仓库repo1.maven.org/maven2,这样哪怕… pom文件约定大于配置的原则,就是通过在Super POM中预定义了一些配置信息来实现的。
Maven使用effective pom(Super pom加上工程自己的配置)来执行相关的目标,它帮助开发者在pom.xml中做尽可能少的配置。当然,这些配置也可以被重写。
parent元素可以指定父pom。用户可以通过增加parent元素来自定义一个父pom,从而继承该pom的配置。parent元素中包含一些子元素,用来定位父项目和父项目的pom文件位置。
- parent:用于指定父项目;
- groupId:parent的子元素,父项目的groupId,用于定位父项目;
- artifactId:parent的子元素,父项目的artifactId,用于定位父项目;
- version:parent的子元素,父项目的version,用于定位父项目;
- relativePath:parent的子元素,用于定位父项目pom文件的位置。
三、modules——子模块列表
此标签在父工程的pom.xml中表示子模块的位置,标签内元素为
如果是父工程的子工程,则直接填写其文件夹名即可
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
四、dependencyManagement——子项目的默认依赖信息
pom文件中:
- 通过dependencyManagement来声明依赖
- 通过dependencies元素来管理依赖。
dependencyManagement下的子元素:
- 一个直接的子元素dependencies,其配置和dependencies子元素是完全一致的;
dependencies下的子元素:
- 一类直接的子元素:dependency。一个dependency子元素表示一个依赖项目。
dependencyManagement 是表示依赖 jar 包的声明。即你在项目中的 dependencyManagement 下声明了依赖,maven 不会加载该依赖,dependencyManagement 声明可以被子 POM 继承。
dependencyManagement 的一个使用案例是当有父子项目的时候,父项目中可以利用 dependencyManagement 声明子项目中需要用到的依赖 jar 包,之后,当某个或者某几个子项目需要加载该依赖的时候,就可以在子项目中 dependencies 节点只配置 groupId 和 artifactId 就可以完成依赖的引用。
dependencyManagement 主要是为了统一管理依赖包的版本,确保所有子项目使用的版本一致,类似的还有plugins和pluginManagement。
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
五、项目依赖相关信息
1、依赖的配置
① maven解析依赖信息时会到本地仓库中取查找被依赖的jar包
- 对于本地仓库中没有的会去中央仓库去查找maven坐标来获取jar包,获取到jar之后会下载到本地仓库
- 对于中央仓库也找不到依赖的jar包的时候,就会编译失败了
② 如果依赖的是自己或者团队开发的maven工程,需要先使用install命令把被依赖的maven工程的jar包导入到本地仓库中
举例:现在我再创建第二个maven工程HelloFriend,其中用到了第一个Hello工程里类的sayHello(String name)方法。我们在给HelloFriend项目使用 mvn compile命令进行编译的时候,会提示缺少依赖Hello的jar包。怎么办呢?
到第一个maven工程中执行 mvn install后,你再去看一下本地仓库,你会发现有了Hello项目的jar包。一旦本地仓库有了依赖的maven工程的jar包后,你再到HelloFriend项目中使用 mvn compile命令的时候,可以成功编译
1 | <project> |
根元素project下的dependencies可以包含一个或者多个dependency元素,以声明一个或者多个项目依赖。每个依赖可以包含的元素有:
- grounpId、artifactId和version:以来的基本坐标,对于任何一个依赖来说,基本坐标是最重要的,Maven根据坐标才能找到需要的依赖。
- type:依赖的类型,对于项目坐标定义的packaging。大部分情况下,该元素不必声明,其默认值为jar
- scope:依赖的范围
- optional:标记依赖是否可选
- exclusions:用来排除传递性依赖
2、依赖范围
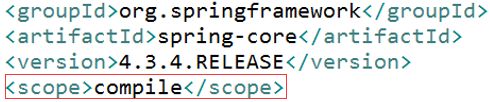
依赖范围就是用来控制依赖和三种classpath(编译classpath,测试classpath、运行classpath)的关系,Maven有如下几种依赖范围:
- **compile:**编译依赖范围。默认值,适用于所有阶段(开发、测试、部署、运行),本jar会一直存在所有阶段。典型的例子是spring-code,在编译、测试和运行的时候都需要使用该依赖。
- test: 测试依赖范围只在测试时使用,用于编译和运行测试代码。不会随项目发布。典型的例子是Jnuit,它只有在编译测试代码及运行测试的时候才需要。
- **provided:**已提供依赖范围。只在开发、测试阶段使用。典型的例子是servlet-api,编译和测试项目的时候需要该依赖,但在运行项目的时候,由于容器以及提供,就不需要Maven重复地引入一遍。
- **runtime:**运行时依赖范围。只在运行、测试时使用。典型的例子是JDBC驱动实现,项目主代码的编译只需要JDK提供的JDBC接口,只有在执行测试或者运行项目的时候才需要实现上述接口的具体JDBC驱动。
- system:系统依赖范围。该依赖与三种classpath的关系,和provided依赖范围完全一致,但是,使用system范围的依赖时必须通过systemPath元素显示地指定依赖文件的路径。由于此类依赖不是通过Maven仓库解析的,而且往往与本机系统绑定,可能构成构建的不可移植,因此应该谨慎使用。systemPath元素可以引用环境变量,如:
1 | <dependency> |
- **import:**导入依赖范围。该依赖范围不会对三种classpath产生实际的影响。
上述除import以外的各种依赖范围与三种classpath的关系如下:

3、依赖的传递性
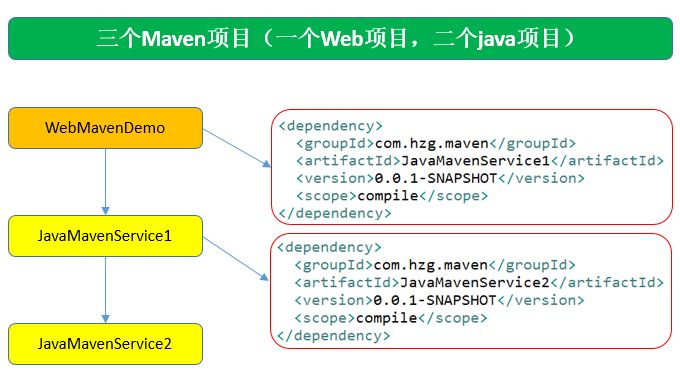
WebMavenDemo项目依赖JavaMavenService1 JavaMavenService1项目依赖JavaMavenService2
pom.xml文件配置好依赖关系后,必须首先mvn install后,依赖的jar包才能使用。
- WebMavenDemo的pom.xml文件想能编译通过,JavaMavenService1必须mvn install
- JavaMavenService的pom.xml文件想能编译通过,JavaMavenService2必须mvn install
传递性:

注意:非compile范围的依赖是不能传递的。
依赖传递范围:
假设A依赖于B,B依赖于C,我们说A对于B是第一直接依赖,B对于C是第二直接依赖,A对于C是传递性依赖。第一直接依赖和第二直接依赖的范围决定了传递性依赖的范围,如下图所示,最左边一行表示第一直接依赖范围,最上面一行表示第二直接依赖范围,中间的交叉单元格则表示传递依赖范围。
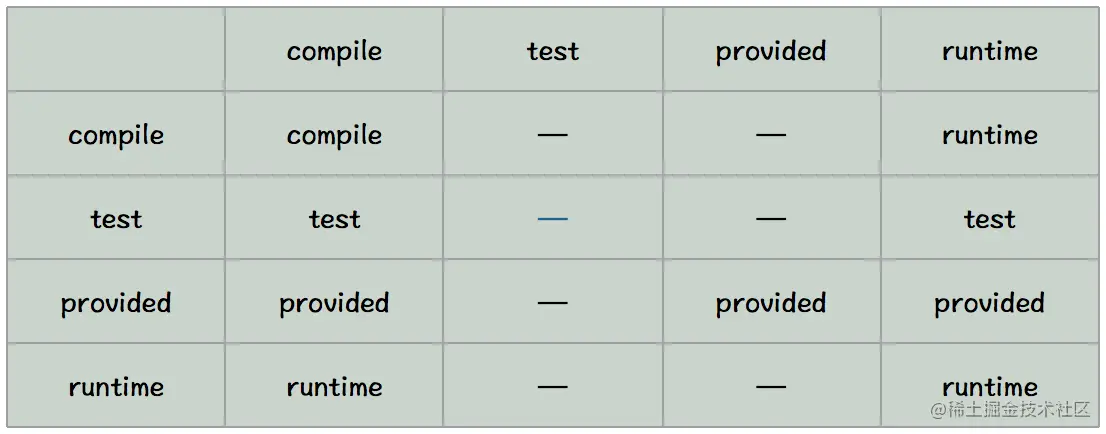
从上图中,我们可以发现这样的规律:
- 当第二直接依赖的范围是compile的时候,传递性依赖的范围与第一直接依赖的范围一致;
- 当第二直接依赖的范围是test的时候,依赖不会得以传递;
- 当第二直接依赖的范围是provided的时候,只传递第一直接依赖范围也为provided的依赖,切传递依赖的范围同样为provided;
- 当第二直接依赖的范围是runtime的时候,传递性依赖的范围与第一直接依赖的范围一致,但compile列外,此时传递性依赖范围为runtime.
依赖版本的原则:
1、路径最短者优先原则

Service2的log4j的版本是1.2.7版本,Service1排除了此包的依赖,自己加了一个Log4j的1.2.9的版本,那么WebMavenDemo项目遵守路径最短优先原则,Log4j的版本和Sercive1的版本一致。
2、路径相同先声明优先原则
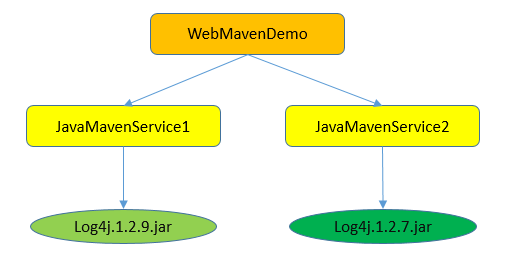
这种场景依赖关系发生了变化,WebMavenDemo项目依赖Sercive1和Service2,它俩是同一个路径,那么谁在WebMavenDemo的pom.xml中先声明的依赖就用谁的版本。
可选依赖
如图,项目中A依赖B,B依赖于X和Y,如果所有这三个的范围都是compile的话,那么X和Y就是A的compile范围的传递性依赖,但是如果我想X,Y不作为A的传递性依赖,不给他用的话。就需要下面提到的配置可选依赖。
1 | <project> |
配置也简单,在依赖里面添加
1 | <optional>true</optional> |
就表示可选依赖了,这样A如果想用X,Y就要直接显示的添加依赖了。
排除依赖
有时候你引入的依赖中包含你不想要的依赖包,你想引入自己想要的,这时候就要用到排除依赖了,比如下图中spring-boot-starter-web自带了logback这个日志包,我想引入log4j2的,所以我先排除掉logback的依赖包,再引入想要的包就行了

排除依赖代码结构:
1 | <exclusions> |
这里注意:声明exclustion的时候只需要groupId和artifactId,而不需要version元素,这是因为只需要groupId和artifactId就能唯一定位依赖图中的某个依赖。
4、归类依赖
有时候我们引入的很多依赖包,他们都来自同一个项目的不同模块,所以他们的版本号都一样,这时候我们可以用属性来统一管理版本号
1 | <project> |
如图所示,先通过
1 | </properties> |
来定义,然后在下面依赖使用${}来引入你的属性。
六、properties——属性列表
properties里面可以定义用户自己的属性值,这些属性值可以在POM文件的任何地方同通过${x}的方式来引用,例如可以通过如下方式管理jar包版本:
1 | <project> |
${X}方式除了可以应用自定义的propertes属性值,还可以引用一下属性:
| 路径 | 说明 | 示例 |
|---|---|---|
| ${env.X} | 平台系统环境变量 | windows、或者linux系统的环境变量,例如:${env.JAVA_HOME}可以获取JAVA_HOME的路径。命令行运行:mvn help:system查看所有可用平台系统环境变量 |
| ${project.X} | pom文件中project根标签下的变量 | 按照官方文档的解释:当前POM文件中project根标签下的标签值都可以通过${project.X}的方式来获取。例如:${project.version}。具体哪些标签可参考官方文档:maven-model |
| ${settings.X} | maven安装目录:conf->settings配置文件里面的属性 | 例如:通过${settings.localRepository}可以获取settings配置文件中的本地仓库路径 |
| ${X} | Java系统属性 | 例如:通过${java.runtime.version}可以获取java运行版本。命令行运行:mvn help:system查看所有可用Java系统属性 |