akka(一)——PRC框架
javaSpring学习(三)——SpringBean
Spring Bean简介
简单来说,Bean 代指的就是那些被 IoC 容器所管理的对象。
我们需要告诉 IoC 容器帮助我们管理哪些对象,这个是通过配置元数据来定义的。配置元数据可以是 XML 文件、注解或者 Java 配置类。
1 | <!-- Constructor-arg with 'value' attribute --> |
下图简单地展示了 IoC 容器如何使用配置元数据来管理对象。

org.springframework.beans和 org.springframework.context 这两个包是 IoC 实现的基础。
一、bean与spring容器的关系

Bean配置信息定义了Bean的实现及依赖关系,Spring容器根据各种形式的Bean配置信息在容器内部建立Bean定义注册表,然后根据注册表加载、实例化Bean,并建立Bean和Bean的依赖关系,最后将这些准备就绪的Bean放到Bean缓存池中,以供外层的应用程序进行调用。
二、Spring注解
从广义上Spring注解可以分为两类:
一类注解是用于注册Bean:即是把已经在xml文件中配置好的Bean拿来用,完成属性、方法的组装;比如@Autowired , @Resource,可以通过byTYPE(@Autowired)、byNAME(@Resource)的方式获取Bean;
假如IOC容器就是一间空屋子,首先这间空屋子啥都没有,我们要吃大餐,我们就要从外部搬运食材和餐具进来。这里把某一样食材或者某一样餐具搬进空屋子的操作就相当于每个注册Bean的注解作用类似。注册Bean的注解作用就是往IOC容器中放(注册)东西! 用于注册Bean的注解: 比如@Component , @Repository , @ Controller , @Service , @Configration这些注解就是用于注册Bean,放进IOC容器中,一来交给spring管理方便解耦,二来还可以进行二次使用,啥是二次使用呢?这里的二次使用可以理解为:在你开始从外部搬运食材和餐具进空屋子的时候,一次性搬运了猪肉、羊肉、铁勺、筷子四样东西,这个时候你要开始吃大餐,首先你吃东西的时候肯定要用筷子或者铁勺,别说你手抓,只要你需要,你就会去找,这个时候发现你已经把筷子或者铁勺放进了屋子,你就不用再去外部拿筷子进屋子了,意思就是IOC容器中已经存在,就可以只要拿去用,而不必再去注册!而拿屋子里已有的东西的操作就是下面要讲的用于使用Bean的注解!
一类注解是用于使用Bean:@Component , @Repository , @ Controller , @Service , @Configration这些注解都是把你要实例化的对象转化成一个Bean,放在IoC容器中,等你要用的时候,它会和上面的@Autowired , @Resource配合到一起,把对象、属性、方法完美组装。
用于使用Bean的注解:比如@Autowired , @Resource注解,这些注解就是把屋子里的东西自己拿来用,如果你要拿,前提一定是屋子(IOC)里有的,不然就会报错,比如你要做一道牛肉拼盘需要五头牛做原材料才行,你现在锅里只有四头牛,这个时候你知道,自己往屋子里搬过五头牛,这个时候就直接把屋子里的那头牛直接放进锅里,完成牛肉拼盘的组装。是的这些注解就是需要啥想要啥,只要容器中有就往容器中拿!而这些注解又有各自的区别,比如@Autowired用在筷子上,这筷子你可能只想用木质的,或许只想用铁质的,@Autowired作用在什么属性的筷子就那什么筷子,而@Resource如果用在安格斯牛肉上面,就指定要名字就是安格斯牛肉的牛肉。
@Component:通用的注解,可标注任意类为Spring组件。如果一个 Bean 不知道属于哪个层,可以使用@Component注解标注。@Repository: 对应持久层即 Dao 层,主要用于数据库相关操作。@Service: 对应服务层,主要涉及一些复杂的逻辑,需要用到 Dao 层。@Controller: 对应 Spring MVC 控制层,主要用户接受用户请求并调用 Service 层返回数据给前端页面。
三、bean的配置方式
bean配置有三种方法:
- 基于xml配置Bean
- 使用注解定义Bean
- 基于java类提供Bean定义信息
1、传统XML配置方式
直接填写 bean标签属性和子标签,根据构造函数实现,可能还会有ref引用其他bean,或者基本属性,集合属性等等
1 |
|
创建对象时,默认执行无参构造函数创建对象。
- 默认命名空间:
- 它没有空间名,用于Spring Bean的定义;
- xsi命名空间:这个命名空间用于为每个文档中命名空间指定相应的Schema样式文件,是标准组织定义的标准命名空间;
- aop命名空间:这个命名空间是Spring配置AOP的命名空间,是用户自定义的命名空间。
命名空间的定义分为两个步骤:第一步指定命名空间的名称;第二步指定命名空间的Schema文档样式文件的位置,用空格或回车换行进行分分隔。
2、Bean基本配置
在Spring容器的配置文件中定义一个简要Bean的配置片段如下所示:
1 | <bean id="" class=""></bean> |
一般情况下,Spring IOC容器中的一个Bean即对应配置文件中的一个<bean>,这种镜像对应关系应该容易理解。
- id为这个Bean的名称,通过容器的getBean(“foo”)即可获取对应的Bean,在容器中起到定位查找的作用,是外部程序和Spring IOC容器进行交互的桥梁。
- class属性指定了Bean对应的实现类。
3、依赖注入
- 属性注入
- 构造函数注入
- 工厂方式注入
使用注解定义bean——@Component
Spring容器成功启动的三大要件分别是:Bean定义信息、Bean实现类以及Spring本身。如果采用基于XML的配置,Bean定义信息和Bean实现类本身是分离的,而采用基于注解的配置方式时,Bean定义信息即通过在Bean实现类上标注注解实现。
下面是使用注解定义一个DAO的Bean:
1 | package com.baobaotao.anno; |
在(1)处,我们使用@Component注解在UserDao类声明处对类进行标注,它可以被Spring容器识别,Spring容器自动将POJO转换为容器管理的Bean。
它和以下的XML配置是等效的:
1 | <bean id="userDao" class="com.baobaotao.anno.UserDao"/> |
除了@Component以外,Spring提供了3个功能基本和@Component等效的注解,它们分别用于对DAO、Service及Web层的Controller进行注解,所以也称这些注解为Bean的衍型注解:(类似于xml文件中定义Bean<bean id=” “ class=” “/>
@Repository:用于对DAO实现类进行标注;==> Dao层@Service:用于对Service实现类进行标注;==>业务逻辑层@Controller:用于对Controller实现类进行标注;==>web控制层
之所以要在@Component之外提供这三个特殊的注解,是为了让注解类本身的用途清晰化,此外Spring将赋予它们一些特殊的功能。
使用注解配置信息启动spring容器
Spring提供了一个context的命名空间,它提供了通过扫描类包以应用注解定义Bean的方式:
1 |
|
在①处声明context命名空间,在②处即可通过context命名空间的component-scan的base-package属性指定一个需要扫描的基类包,Spring容器将会扫描这个基类包里的所有类,并从类的注解信息中获取Bean的定义信息。
如果仅希望扫描特定的类而非基包下的所有类,你们可以使用resource-pattern属性过滤特定的类,如下所示:
1 | < context:component-scan base-package="com.baobaotao" resource-pattern="anno/*.class"/ > |
这里我们将基类包设置为com.baobaotao,默认情况下resource-pattern属性的值为”**/.class”,即基类包里的所有类。这里我们设置为”anno/.class”,则Spring仅会扫描基包里anno子包中的类。
4、基于java类提供Bean定义——@Configuration
在普通的POJO类中只要标注@Configuration注解,就可以为spring容器提供Bean定义的信息了,每个标注了@Bean的类方法都相当于提供了一个Bean的定义信息。
1 | package com.baobaotao.conf; |
①处在APPConf类的定义处标注了@Configuration注解,说明这个类可用于为Spring提供Bean的定义信息。类的方法处可以标注@Bean注解,Bean的类型由方法返回值类型决定,名称默认和方法名相同,也可以通过入参显示指定Bean名称,如@Bean(name=”userDao”).直接在@Bean所标注的方法中提供Bean的实例化逻辑。
在②处userDao()和logDao()方法定义了一个UserDao和一个LogDao的Bean,它们的Bean名称分别是userDao和logDao。在③处,又定义了一个logonService Bean,并且在④处注入②处所定义的两个Bean。
因此,以上的配置和以下XML配置时等效的:
1 | <bean id="userDao" class="com.baobaotao.anno.UserDao"/> |
基于java类的配置方式和基于XML或基于注解的配置方式相比,前者通过代码的方式更加灵活地实现了Bean的实例化及Bean之间的装配,但后面两者都是通过配置声明的方式,在灵活性上要稍逊一些,但是配置上要更简单一些。
5、@Component 和 @Bean 的区别是什么?
@Component注解作用于类,而@Bean注解作用于方法。@Component通常是通过类路径扫描来自动侦测以及自动装配到 Spring 容器中(我们可以使用@ComponentScan注解定义要扫描的路径从中找出标识了需要装配的类自动装配到 Spring 的 bean 容器中)。@Bean注解通常是我们在标有该注解的方法中定义产生这个 bean,@Bean告诉了 Spring 这是某个类的实例,当我需要用它的时候还给我。@Bean注解比@Component注解的自定义性更强,而且很多地方我们只能通过@Bean注解来注册 bean。比如当我们引用第三方库中的类需要装配到Spring容器时,则只能通过@Bean来实现。
@Bean注解使用示例:
1 |
|
上面的代码相当于下面的 xml 配置
1 | <beans> |
下面这个例子是通过 @Component 无法实现的。
1 |
|
四、Bean注入
Bean注入的方式有两种,一种是在XML中配置,此时分别有属性注入、构造函数注入和工厂方法注入;另一种则是使用注解的方式注入 @Autowired,@Resource,@Required。
1、在xml文件中配置依赖注入
a.属性注入
属性注入即通过setXxx()方法注入Bean的属性值或依赖对象,由于属性注入方式具有可选择性和灵活性高的优点,因此属性注入是实际应用中最常采用的注入方式。
属性注入要求Bean提供一个默认的构造函数,并为需要注入的属性提供对应的Setter方法。Spring先调用Bean的默认构造函数实例化Bean对象,然后通过反射的方式调用Setter方法注入属性值。
1 | package com.baobaotao.anno; |
bean.xml配置
1 |
|
- ref引用一个已经存在的对象
- property:是通过setter方法注入
b.构造方法注入
使用构造函数注入的前提是Bean必须提供带参数的构造函数。例如
1 | package com.baobaotao.anno; |
bean.xml配置
1 |
|
- constructor-arg:通过构造方法注入
constructor-arg标签属性:
- name属性:通过参数名找到参数列表中对应参数
- index属性:通过参数在参数列表中的索引找到参数列表中对应参数,index从0开始:
- type属性:通过参数数据类型找到参数列表中对应参数
- value属性:设置参数列表参数对应的值,用于设定基本数据类型和String类型的数据
- ref属性:如果参数值为非基本数据类型,则可通过ref为参数注入值,其值为另一个bean标签id或name属性的属性值
constructor-arg子标签:
- ref子标签:对应ref属性,该标签name属性的属性值为另一个bean标签id或name属性的属性值;
- value子标签:对应value属性,用于设置基本数据类型或String类型的参数值;
- list子标签:为数组或List类型的参数赋值
- set子标签:为Set集合类型参数赋值
- map子标签:为Map集合类型参数赋值
- props子标签:为Properties类型的参数赋值
参考文章:
c.工厂方法注入
非静态工厂方法:
有些工厂方法是非静态的,即必须实例化工厂类后才能调用工厂放。
1 | package com.baobaotao.ditype; |
工厂类负责创建一个或多个目标类实例,工厂类方法一般以接口或抽象类变量的形式返回目标类实例,工厂类对外屏蔽了目标类的实例化步骤,调用者甚至不用知道具体的目标类是什么。
1 |
|
静态工厂方法:
很多工厂类都是静态的,这意味着用户在无须创建工厂类实例的情况下就可以调用工厂类方法,因此,静态工厂方法比非静态工厂方法的调用更加方便。
1 |
|
2、使用注解的方式注入
a.使用@Autowired进行自动注入
Spring通过@Autowired注解实现Bean的依赖注入,下面是一个例子:
1 | package com.baobaotao.anno; |
在①处,我们使用@Service将LogonService标注为一个Bean,在②处,通过@Autowired注入LogDao及UserDao的Bean。
@Autowired默认按类型匹配的方式,在容器查找匹配的Bean,当有且仅有一个匹配的Bean时,Spring将其注入到@Autowired标注的变量中。
使用@Autowired的required属性
如果容器中没有一个和标注变量类型匹配的Bean,Spring容器启动时将报NoSuchBeanDefinitionException的异常。如果希望Spring即使找不到匹配的Bean完成注入也不用抛出异常,那么可以使用@Autowired(required=false)进行标注:
1 |
|
默认情况下,@Autowired的required属性的值为true,即要求一定要找到匹配的Bean,否则将报异常。
b.使用@Qualifier指定注入Bean的名称
如果容器中有一个以上匹配的Bean时,则可以通过@Qualifier注解限定Bean的名称,如下所示:
1 |
|
这里假设容器有两个类型为UserDao的Bean,一个名为userDao,另一个名为otherUserDao,则①处会注入名为userDao的Bean。
c.对类方法进行标注
@Autowired可以对类成员变量及方法的入参进行标注,下面我们在类的方法上使用@Autowired注解:
1 | package com.baobaotao.anno; |
如果一个方法拥有多个入参,在默认情况下,Spring自动选择匹配入参类型的Bean进行注入。Spring允许对方法入参标注@Qualifier以指定注入Bean的名称,如下所示:
1 |
|
在以上例子中,UserDao的入参注入名为userDao的Bean,而LogDao的入参注入LogDao类型的Bean。
一般情况下,在Spring容器中大部分的Bean都是单实例的,所以我们一般都无须通过@Repository、@Service等注解的value属性为Bean指定名称,也无须使用@Qualifier按名称进行注入。
d.对标准注解的支持
此外,Spring还支持@Resource和@Inject注解,这两个标准注解和@Autowired注解的功能类型,都是对类变量及方法入参提供自动注入的功能。
@Resource要求提供一个Bean名称的属性,如果属性为空,则自动采用标注处的变量名或方法名作为Bean的名称。
1 | package com.baobaotao.anno; |
这时,如果@Resource未指定”car”属性,则也可以根据属性方法得到需要注入的Bean名称。可见**@Autowired默认按类型匹配注入Bean,@Resource则按名称匹配注入Bean**。而@Inject和@Autowired一样也是按类型匹配注入的Bean的,只不过它没有required属性。可见不管是@Resource还是@Inject注解,其功能都没有@Autowired丰富,因此除非必须,大可不必在乎这两个注解。
(类似于Xml中使用
1 | <constructor-arg ref="logDao"></constructor-arg> |
进行注入,如果使用了@Autowired或者Resource等,这不需要在定义Bean时使用属性注入和构造方法注入了)
e.@Autowired 和 @Resource 的区别
@Autowired注入是按照类型注入的,只要配置文件中的bean类型和需要的bean类型是一致的,这时候注入就没问题。但是如果相同类型的bean不止一个,此时注入就会出现问题,Spring容器无法启动。Autowired属于 Spring 内置的注解,默认的注入方式为byType(根据类型进行匹配),也就是说会优先根据接口类型去匹配并注入 Bean (接口的实现类)。这会有什么问题呢? 当一个接口存在多个实现类的话,
byType这种方式就无法正确注入对象了,因为这个时候 Spring 会同时找到多个满足条件的选择,默认情况下它自己不知道选择哪一个。这种情况下,注入方式会变为
byName(根据名称进行匹配),这个名称通常就是类名(首字母小写)。@Resourced标签是按照bean的名字来进行注入的,如果我们没有在使用@Resource时指定bean的名字,同时Spring容器中又没有该名字的bean,这时候@Resource就会退化为@Autowired即按照类型注入,这样就有可能违背了使用@Resource的初衷。所以建议在使用@Resource时都显示指定一下bean的名字@Resource(name=”xxx”)
就比如说下面代码中的 smsService 。
1 | // smsService 就是我们上面所说的名称 |
举个例子,SmsService 接口有两个实现类: SmsServiceImpl1和 SmsServiceImpl2,且它们都已经被 Spring 容器所管理。
1 | // 报错,byName 和 byType 都无法匹配到 bean |
我们还是建议通过 @Qualifier 注解来显示指定名称而不是依赖变量的名称。
@Resource属于 JDK 提供的注解,默认注入方式为 byName。如果无法通过名称匹配到对应的 Bean 的话,注入方式会变为byType。
@Resource 有两个比较重要且日常开发常用的属性:name(名称)、type(类型)。
1 | public Resource { |
如果仅指定 name 属性则注入方式为byName,如果仅指定type属性则注入方式为byType,如果同时指定name 和type属性(不建议这么做)则注入方式为byType+byName。
1 | // 报错,byName 和 byType 都无法匹配到 bean |
简单总结一下:
@Autowired是 Spring 提供的注解,@Resource是 JDK 提供的注解。Autowired默认的注入方式为byType(根据类型进行匹配),@Resource默认注入方式为byName(根据名称进行匹配)。- 当一个接口存在多个实现类的情况下,
@Autowired和@Resource都需要通过名称才能正确匹配到对应的 Bean。Autowired可以通过@Qualifier注解来显示指定名称,@Resource可以通过name属性来显示指定名称。
f.让@Resource和@Autowired生效的几种方式
1.在xml配置文件中显式指定
1 | <!-- 为了使用Autowired标签,我们必须在这里配置一个bean的后置处理器 --> |
2.在xml配置文件中使用context:annotation-config
1 | <context:annotation-config /> |
3.在xml配置文件中使用context:component-scan
1 | <context:component-scan base-package="com.baobaotao.anno"/> |
4.重写Spring容器的Context,在自定义BeanFactory时调用AnnotationConfigUtils.registerAnnotationConfigProcessors()把这两个注解处理器增加到容器中。
g.自动注入
此时对象已经存放在了容器中,等着被用。那我们怎么从容器中取到我们想用的对象呢?
两种方式,一种是通过类型,一种是通过名字。(容器中的一个对象必然携带两个信息,一个是自己是哪个类的对象,即类型;一个是自己叫什么名字)
最先想到的就是get,对,get。从哪里get呢?从容器中。容器在哪里呢?
容器 最根是个BeanFactory(开始设计的时候定义的),有个子类叫ApplicationContext(容器管理的一些方法,就像Object和Map),专门做这事情。从 ApplicationContext中get出来我们需要的对象。
ApplicationContext 有很多实现,主要针对不同场景下
- AnnotationConfigApplicationContext : 从一个或多个基于Java的配置类中加载上下文定义,适用于Java注解的方式;
- ClassPathXmlApplicationContext : 从类路径下的一个或多个xml配置文件中加载上下文定义,适用于xml配置的方式;
- FilesSystemXmlApplicationContext : 从文件系统下的一个或多个xml配置文件中加载上下文定义,也就是说系统盘符中加载xml配置文件
- AnnotationConfigWebApplicationContext : 专门为web应用准备的,适用于注解方式;
- XmlWebApplicationContext : 从web应用下的一个或多个xml配置文件加载上下文定义,适用于xml配置方式
五、Bean的作用域
Spring 中 Bean 的作用域通常有下面几种:
- singleton : 唯一 bean 实例,Spring 中的 bean 默认都是单例的,对单例设计模式的应用。
- prototype : 每次请求都会创建一个新的 bean 实例。
- request : 每一次 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP request 内有效。
- session : 每一次来自新 session 的 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP session 内有效。
- global-session : 全局 session 作用域,仅仅在基于 portlet 的 web 应用中才有意义,Spring5 已经没有了。Portlet 是能够生成语义代码(例如:HTML)片段的小型 Java Web 插件。它们基于 portlet 容器,可以像 servlet 一样处理 HTTP 请求。但是,与 servlet 不同,每个 portlet 都有不同的会话。
如何配置 bean 的作用域呢?
xml 方式:
1 | <bean id="..." class="..." scope="singleton"></bean> |
注解方式:
1 |
|
六、Bean的生命周期
下面的内容整理自:https://yemengying.com/2016/07/14/spring-bean-life-cycle/ ,除了这篇文章,再推荐一篇很不错的文章 :https://www.cnblogs.com/zrtqsk/p/3735273.html 。
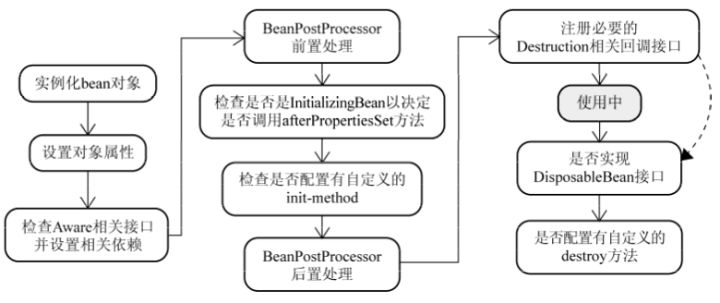
- Bean 容器找到配置文件中 Spring Bean 的定义。
- Bean 容器利用 Java Reflection API 创建一个 Bean 的实例。由BeanFactory读取Bean定义文件,并生成各个实例。
- 如果涉及到一些属性值 利用
set()方法设置一些属性值。 - 如果 Bean 实现了
BeanNameAware接口,调用setBeanName()方法,传入 Bean 的名字。 - 如果 Bean 实现了
BeanClassLoaderAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。 - 如果 Bean 实现了
BeanFactoryAware接口,调用setBeanFactory()方法,传入BeanFactory对象的实例。 - 与上面的类似,如果实现了其他
*.Aware接口,就调用相应的方法。 - 如果有和加载这个 Bean 的 Spring 容器相关的
BeanPostProcessor对象,执行postProcessBeforeInitialization()方法 - 如果 Bean 实现了
InitializingBean接口,执行afterPropertiesSet()方法。 - 如果 Bean 在配置文件中的定义包含 init-method 属性,执行指定的方法。
- 如果有和加载这个 Bean 的 Spring 容器相关的
BeanPostProcessor对象,执行postProcessAfterInitialization()方法 - 当要销毁 Bean 的时候,如果 Bean 实现了
DisposableBean接口,执行destroy()方法。 - 当要销毁 Bean 的时候,如果 Bean 在配置文件中的定义包含 destroy-method 属性,执行指定的方法。
图示:
与之比较类似的中文版本:
七、Bean的实例化
1、 懒汉式:BeanFactory
只有当客户端调用BeanFactory的getBean()方法来请求某个实例对象的时候,才会触发相应bean的实例化进程( 当然对于 BeanFactory 容器而言并不是所有的 getBean() 方法都会触发实例化进程,比如 signleton 类型的 bean,该类型的 bean 只会在第一次调用 getBean() 的时候才会触发,而后续的调用则会直接返回容器缓存中的实例对象)
2、 饿汉式:ApplicationContext
使用ApplicationContext容器启动的时候立刻调用注册到该容器所有bean定义的实例化方法
Spring提供了两种类型的IOC容器实现(两种类型的配置方式是一样)
- BeanFactory:是Spring框架的基础设施,面向Spring本身
- ApplicationContext: 面向使用 Spring 框架的开发者,几乎所有的应用场合都直接使用 ApplicationContext 而非底层的
Spring单例Bean与单例模式的区别
单例模式是指在一个JVM进程中仅有一个实例,而Spring单例是指一个Spring Bean容器(ApplicationContext)中仅有一个实例。
首先看单例模式,在一个JVM进程中(理论上,一个运行的JAVA程序就必定有自己一个独立的JVM)仅有一个实例,于是无论在程序中的何处获取实例,始终都返回同一个对象。
与此相比,Spring的单例Bean是与其容器(ApplicationContext)密切相关的,所以在一个JVM进程中,如果有多个Spring容器,即使是单例bean,也一定会创建多个实例。
单例 Bean 的线程安全问题
大部分时候我们并没有在项目中使用多线程,所以很少有人会关注这个问题。单例 Bean 存在线程问题,主要是因为当多个线程操作同一个对象的时候是存在资源竞争的。
常见的有两种解决办法:
- 在 Bean 中尽量避免定义可变的成员变量。
- 在类中定义一个
ThreadLocal成员变量,将需要的可变成员变量保存在ThreadLocal中(推荐的一种方式)。
不过,大部分 Bean 实际都是无状态(没有实例变量)的(比如 Dao、Service),这种情况下, Bean 是线程安全的。
javaSpring学习(五)——SpringMVC
Spring MVC
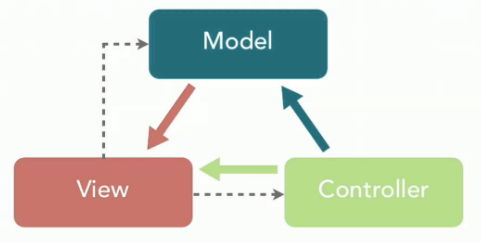
MVC 是模型(Model)、视图(View)、控制器(Controller)的简写,其核心思想是通过将业务逻辑、数据、显示分离来组织代码。

网上有很多人说 MVC 不是设计模式,只是软件设计规范,我个人更倾向于 MVC 同样是众多设计模式中的一种。**java-design-patterns** 项目中就有关于 MVC 的相关介绍。
想要真正理解 Spring MVC,我们先来看看 Model 1 和 Model 2 这两个没有 Spring MVC 的时代。
Model 1 时代
很多学 Java 后端比较晚的朋友可能并没有接触过 Model 1 时代下的 JavaWeb 应用开发。在 Model1 模式下,整个 Web 应用几乎全部用 JSP 页面组成,只用少量的 JavaBean 来处理数据库连接、访问等操作。
这个模式下 JSP 即是控制层(Controller)又是表现层(View)。显而易见,这种模式存在很多问题。比如控制逻辑和表现逻辑混杂在一起,导致代码重用率极低;再比如前端和后端相互依赖,难以进行测试维护并且开发效率极低。

Model 2 时代
学过 Servlet 并做过相关 Demo 的朋友应该了解“Java Bean(Model)+ JSP(View)+Servlet(Controller) ”这种开发模式,这就是早期的 JavaWeb MVC 开发模式。
- Model:系统涉及的数据,也就是 dao 和 bean。
- View:展示模型中的数据,只是用来展示。
- Controller:处理用户请求都发送给 ,返回数据给 JSP 并展示给用户。

Model2 模式下还存在很多问题,Model2 的抽象和封装程度还远远不够,使用 Model2 进行开发时不可避免地会重复造轮子,这就大大降低了程序的可维护性和复用性。
于是,很多 JavaWeb 开发相关的 MVC 框架应运而生比如 Struts2,但是 Struts2 比较笨重。
Spring MVC 时代
随着 Spring 轻量级开发框架的流行,Spring 生态圈出现了 Spring MVC 框架, Spring MVC 是当前最优秀的 MVC 框架。相比于 Struts2 , Spring MVC 使用更加简单和方便,开发效率更高,并且 Spring MVC 运行速度更快。
MVC 是一种设计模式,Spring MVC 是一款很优秀的 MVC 框架。Spring MVC 可以帮助我们进行更简洁的 Web 层的开发,并且它天生与 Spring 框架集成。Spring MVC 下我们一般把后端项目分为 Service 层(处理业务)、Dao 层(数据库操作)、Entity 层(实体类)、Controller 层(控制层,返回数据给前台页面)。
SpringMVC 工作原理
Spring MVC 原理如下图所示:
SpringMVC 工作原理的图解我没有自己画,直接图省事在网上找了一个非常清晰直观的,原出处不明。
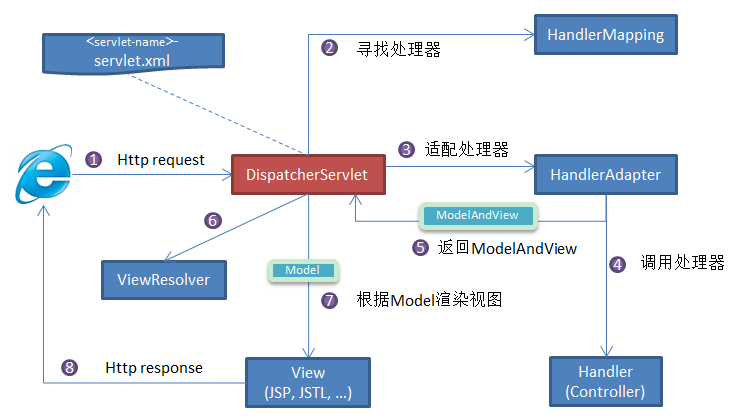
流程说明(重要):
- 客户端(浏览器)发送请求,直接请求到
DispatcherServlet。 DispatcherServlet根据请求信息调用HandlerMapping处理器映射器,解析请求对应的Handler。- 解析到对应的
Handler(也就是我们平常说的Controller控制器) - 处理器映射器找到具体的处理器(可以根据xml配置、注解进行查找),生成处理器对象及处理器拦截器(如果有则生成)一并返回给
DispatcherServlet。 DispatcherServlet调用HandlerAdapter处理器适配器。HandlerAdapter会根据Handler来调用真正的处理器开处理请求,并处理相应的业务逻辑。- 处理器处理完业务后,会返回一个
ModelAndView对象,Model是返回的数据对象,View是个逻辑上的View。 HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet。DispatcherServlet将ModelAndView传给ViewReslover视图解析器。ViewResolver会根据逻辑View查找实际的View。DispaterServlet把返回的Model传给View(视图渲染)。- 把
View返回给请求者(浏览器)
请求 —> DispatcherServlet(前端控制器)—> 调用HandlerMapping(处理器映射器)—> DispatcherServlet调用 HandlerAdapter(处理器适配器)—> 适配调用具体的Controller —> 返回ModelAndView —> 传给ViewReslover视图解析器 —> 解析后返回具体View —> 根据View进行渲染视图响应用户.
Spring与SpringMVC父子容器的区别和联系
- Spring 与SpringMVC 两个都是容器,存在父子关系(包含和被包含的关系)
- Spring容器中存放着mapper代理对象,service对象,SpringMVC存放着Controller对象。子容器SpringMVC中可以访问父容器中的对象。但父容器Spring不能访问子容器SpringMVC的对象(存在领域作用域的原因,子容器可以访问父容器中的成员,而子容器的成员则只能被自己使用)。如:Service对象可以在Controller层中注入,反之则不行。
- Spring容器导入的properties配置文件,只能在Spring容器中用而在SpringMVC容器中不能读取到。 需要在SpringMVC 的配置文件中重新进行导入properties文件,并且同样在父容器Spring中不能被使用,导入后使用@Value(“${key}”)在java类中进行读取。
SpringMVC拦截器
常见应用场景
- 日志记录:记录请求信息的日志,以便进行信息监控、信息统计、计算PV(Page View)等
- 权限检查:如登录检测,进入处理器检测检测是否登录,如果没有直接返回到登录页面
- 性能监控:有时候系统在某段时间莫名其妙的慢,可以通过拦截器在进入处理器之前记录开始时间,在处理完后记录结束时间,从而得到该请求的处理时间(如果有反向代理,如apache可以自动记录)
- 通用行为:读取cookie得到用户信息并将用户对象放入请求,从而方便后续流程使用,还有如提取Locale、Theme信息等,只要是多个处理器都需要的即可使用拦截器实现。
- OpenSessionInView:如Hibernate,在进入处理器打开Session,在完成后关闭Session。
拦截器接口
1 | public interface HandlerInterceptor { |
拦截器和过滤器什么区别
Spring的拦截器与Servlet的过滤器Filter有很多相似之处,比如两者都是AOP编程思想的体现,都能实现权限检查、日志记录等,不同的是:
- 使用范围不同:Filter是Servlet规范规定的,只能用于Web程序中,而拦截器既可以用于Web程序,也可以用于Application、Swing程序中
- 规范不同:Filter是Servlet规范中定义的,是Servlet容器支持的。而拦截器是在Spring容器内的,是Spring框架支持的
- 使用的资源不同:拦截器是一个Spring的组件,归Spring管理,配置在Spring文件中,因此能使用Spring里的任何资源、对象,例如Service对象、数据源、事务管理等,通过IoC注入到拦截器即可,而Filter则不能
- 深度不同:Filter只在Servlet前后起作用。而拦截器能够深入到方法前后、异常抛出前后等,因此拦截器的使用具有更大的弹性。所以在Spring架构的程序中,要优先使用拦截器。
- 实现原理不同:拦截器是基于动态代理来实现的,而过滤器是基于函数回调来实现的。
- 作用域不同:拦截器只对Action起作用,过滤器可以对所有请求起作用。
- 调用次序不同:在action的生命周期中,拦截器可以多次被调用,而过滤器只能在容器初始化时被调用一次。
参考
javaSpring学习(四)——Spring事务
Spring事务介绍
事务是逻辑上的一组操作,要么都执行,要么都不执行。
格外注意的是:事务能否生效数据库引擎是否支持事务是关键。比如常用的 MySQL 数据库默认使用支持事务的 innodb引擎。但是,如果把数据库引擎变为 myisam,那么程序也就不再支持事务了!
事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账 1000 元,这个转账会涉及到两个关键操作就是:
- 将小明的余额减少 1000 元。
- 将小红的余额增加 1000 元。
万一在这两个操作之间突然出现错误比如银行系统崩溃或者网络故障,导致小明余额减少而小红的余额没有增加,这样就不对了。事务就是保证这两个关键操作要么都成功,要么都要失败。
1 | public class OrdersService { |
另外,数据库事务的 ACID 四大特性是事务的基础,下面简单来了解一下。
- 原子性(Atomicity): 一个事务(transaction)中的所有操作,或者全部完成,或者全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。即,事务不可分割、不可约简。
- 一致性(Consistency): 在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设约束、触发器、级联回滚等。
- 隔离性(Isolation): 数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括未提交读(Read uncommitted)、提交读(read committed)、可重复读(repeatable read)和串行化(Serializable)。
- 持久性(Durability): 事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
Spring 管理事务的方式
- 编程式事务 : 在代码中硬编码(不推荐使用) : 通过
TransactionTemplate或者TransactionManager手动管理事务,实际应用中很少使用,但是对于你理解 Spring 事务管理原理有帮助。 - 声明式事务 : 在 XML 配置文件中配置或者直接基于注解(推荐使用) : 实际是通过 AOP 实现(基于
@Transactional的全注解方式使用最多)
编程式事务管理
通过 TransactionTemplate或者TransactionManager手动管理事务,实际应用中很少使用,但是对于你理解 Spring 事务管理原理有帮助。
使用TransactionTemplate 进行编程式事务管理的示例代码如下:
1 |
|
使用 TransactionManager 进行编程式事务管理的示例代码如下:
1 |
|
声明式事务管理
推荐使用(代码侵入性最小),实际是通过 AOP 实现(基于@Transactional 的全注解方式使用最多)。
使用 @Transactional注解进行事务管理的示例代码如下:
1 |
|
Spring 事务管理接口介绍
Spring 框架中,事务管理相关最重要的 3 个接口如下:
- **
PlatformTransactionManager**: (平台)事务管理器,Spring 事务策略的核心。 - **
TransactionDefinition**: 事务定义信息(事务隔离级别、传播行为、超时、只读、回滚规则)。 - **
TransactionStatus**: 事务运行状态。
我们可以把 PlatformTransactionManager 接口可以被看作是事务上层的管理者,而 TransactionDefinition 和 TransactionStatus 这两个接口可以看作是事务的描述。
PlatformTransactionManager 会根据 TransactionDefinition 的定义比如事务超时时间、隔离级别、传播行为等来进行事务管理 ,而 TransactionStatus 接口则提供了一些方法来获取事务相应的状态比如是否新事务、是否可以回滚等等。
PlatformTransactionManager:事务管理接口
Spring 并不直接管理事务,而是提供了多种事务管理器 。Spring 事务管理器的接口是: PlatformTransactionManager 。
通过这个接口,Spring 为各个平台如 JDBC(DataSourceTransactionManager)、Hibernate(HibernateTransactionManager)、JPA(JpaTransactionManager)等都提供了对应的事务管理器,但是具体的实现就是各个平台自己的事情了。
PlatformTransactionManager 接口的具体实现如下:
![]()
PlatformTransactionManager接口中定义了三个方法:
1 | package org.springframework.transaction; |
这里多插一嘴。为什么要定义或者说抽象出来PlatformTransactionManager这个接口呢?
主要是因为要将事务管理行为抽象出来,然后不同的平台去实现它,这样我们可以保证提供给外部的行为不变,方便我们扩展。
“为什么我们要用接口?” 。
《设计模式》(GOF 那本)这本书在很多年前都提到过说要基于接口而非实现编程,你真的知道为什么要基于接口编程么?
纵观开源框架和项目的源码,接口是它们不可或缺的重要组成部分。要理解为什么要用接口,首先要搞懂接口提供了什么功能。我们可以把接口理解为提供了一系列功能列表的约定,接口本身不提供功能,它只定义行为。但是谁要用,就要先实现我,遵守我的约定,然后再自己去实现我定义的要实现的功能。
举个例子,我上个项目有发送短信的需求,为此,我们定了一个接口,接口只有两个方法:
1.发送短信 2.处理发送结果的方法。
刚开始我们用的是阿里云短信服务,然后我们实现这个接口完成了一个阿里云短信的服务。后来,我们突然又换到了别的短信服务平台,我们这个时候只需要再实现这个接口即可。这样保证了我们提供给外部的行为不变。几乎不需要改变什么代码,我们就轻松完成了需求的转变,提高了代码的灵活性和可扩展性。
什么时候用接口?当你要实现的功能模块设计抽象行为的时候,比如发送短信的服务,图床的存储服务等等。
TransactionDefinition:事务属性
事务管理器接口 PlatformTransactionManager 通过 getTransaction(TransactionDefinition definition) 方法来得到一个事务,这个方法里面的参数是 TransactionDefinition 类 ,这个类就定义了一些基本的事务属性。
什么是事务属性呢? 事务属性可以理解成事务的一些基本配置,描述了事务策略如何应用到方法上。
事务属性包含了 5 个方面:
- 隔离级别
- 传播行为
- 回滚规则
- 是否只读
- 事务超时
TransactionDefinition 接口中定义了 5 个方法以及一些表示事务属性的常量比如隔离级别、传播行为等等。
1 | package org.springframework.transaction; |
TransactionStatus:事务状态
TransactionStatus接口用来记录事务的状态 该接口定义了一组方法,用来获取或判断事务的相应状态信息。
PlatformTransactionManager.getTransaction(…)方法返回一个 TransactionStatus 对象。
TransactionStatus 接口内容如下:
1 | public interface TransactionStatus{ |
事务属性详解
实际业务开发中,大家一般都是使用 @Transactional 注解来开启事务,但很多人并不清楚这个注解里面的参数是什么意思,有什么用。为了更好的在项目中使用事务管理,强烈推荐好好阅读一下下面的内容。
事务传播行为
事务传播行为是为了解决业务层方法之间互相调用的事务问题。
当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。
举个例子:我们在 A 类的aMethod()方法中调用了 B 类的 bMethod() 方法。这个时候就涉及到业务层方法之间互相调用的事务问题。如果我们的 bMethod()如果发生异常需要回滚,如何配置事务传播行为才能让 aMethod()也跟着回滚呢?这个时候就需要事务传播行为的知识了,如果你不知道的话一定要好好看一下。
1 |
|
在TransactionDefinition定义中包括了如下几个表示传播行为的常量:
1 | public interface TransactionDefinition { |
不过,为了方便使用,Spring 相应地定义了一个枚举类:Propagation
1 | package org.springframework.transaction.annotation; |
正确的事务传播行为可能的值如下 :
1.TransactionDefinition.PROPAGATION_REQUIRED
使用的最多的一个事务传播行为,我们平时经常使用的@Transactional注解默认使用就是这个事务传播行为。如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。也就是说:
- 如果外部方法没有开启事务的话,
Propagation.REQUIRED修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。 - 如果外部方法开启事务并且被
Propagation.REQUIRED的话,所有Propagation.REQUIRED修饰的内部方法和外部方法均属于同一事务 ,只要一个方法回滚,整个事务均回滚。
举个例子:如果我们上面的aMethod()和bMethod()使用的都是PROPAGATION_REQUIRED传播行为的话,两者使用的就是同一个事务,只要其中一个方法回滚,整个事务均回滚。
1 |
|
2.TransactionDefinition.PROPAGATION_REQUIRES_NEW
创建一个新的事务,如果当前存在事务,则把当前事务挂起。也就是说不管外部方法是否开启事务,Propagation.REQUIRES_NEW修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。
举个例子:如果我们上面的bMethod()使用PROPAGATION_REQUIRES_NEW事务传播行为修饰,aMethod还是用PROPAGATION_REQUIRED修饰的话。如果aMethod()发生异常回滚,bMethod()不会跟着回滚,因为 bMethod()开启了独立的事务。但是,如果 bMethod()抛出了未被捕获的异常并且这个异常满足事务回滚规则的话,aMethod()同样也会回滚,因为这个异常被 aMethod()的事务管理机制检测到了。
1 |
|
3.TransactionDefinition.PROPAGATION_NESTED:
如果当前存在事务,就在嵌套事务内执行;如果当前没有事务,就执行与TransactionDefinition.PROPAGATION_REQUIRED类似的操作。也就是说:
- 在外部方法开启事务的情况下,在内部开启一个新的事务,作为嵌套事务存在。
- 如果外部方法无事务,则单独开启一个事务,与
PROPAGATION_REQUIRED类似。
这里还是简单举个例子:如果 bMethod() 回滚的话,aMethod()也会回滚。
1 |
|
4.TransactionDefinition.PROPAGATION_MANDATORY
如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
这个使用的很少,就不举例子来说了。
若是错误的配置以下 3 种事务传播行为,事务将不会发生回滚,这里不对照案例讲解了,使用的很少。
TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
更多关于事务传播行为的内容请看这篇文章:《太难了~面试官让我结合案例讲讲自己对 Spring 事务传播行为的理解。》
Spring 事务中的隔离级别
和事务传播行为这块一样,为了方便使用,Spring 也相应地定义了一个枚举类:Isolation
1 | public enum Isolation { |
下面我依次对每一种事务隔离级别进行介绍:
TransactionDefinition.ISOLATION_DEFAULT:使用后端数据库默认的隔离级别,MySQL 默认采用的REPEATABLE_READ隔离级别 Oracle 默认采用的READ_COMMITTED隔离级别.TransactionDefinition.ISOLATION_READ_UNCOMMITTED:最低的隔离级别,使用这个隔离级别很少,因为它允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读TransactionDefinition.ISOLATION_READ_COMMITTED: 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生TransactionDefinition.ISOLATION_REPEATABLE_READ: 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。TransactionDefinition.ISOLATION_SERIALIZABLE: 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
相关阅读:MySQL事务隔离级别详解。
事务超时属性
所谓事务超时,就是指一个事务所允许执行的最长时间,如果超过该时间限制但事务还没有完成,则自动回滚事务。在 TransactionDefinition 中以 int 的值来表示超时时间,其单位是秒,默认值为-1,这表示事务的超时时间取决于底层事务系统或者没有超时时间。
事务只读属性
1 | package org.springframework.transaction; |
对于只有读取数据查询的事务,可以指定事务类型为 readonly,即只读事务。只读事务不涉及数据的修改,数据库会提供一些优化手段,适合用在有多条数据库查询操作的方法中。
很多人就会疑问了,为什么我一个数据查询操作还要启用事务支持呢?
拿 MySQL 的 innodb 举例子,根据官网 https://dev.mysql.com/doc/refman/5.7/en/innodb-autocommit-commit-rollback.html 描述:
MySQL 默认对每一个新建立的连接都启用了
autocommit模式。在该模式下,每一个发送到 MySQL 服务器的sql语句都会在一个单独的事务中进行处理,执行结束后会自动提交事务,并开启一个新的事务。
但是,如果你给方法加上了Transactional注解的话,这个方法执行的所有sql会被放在一个事务中。如果声明了只读事务的话,数据库就会去优化它的执行,并不会带来其他的什么收益。
如果不加Transactional,每条sql会开启一个单独的事务,中间被其它事务改了数据,都会实时读取到最新值。
分享一下关于事务只读属性,其他人的解答:
- 如果你一次执行单条查询语句,则没有必要启用事务支持,数据库默认支持 SQL 执行期间的读一致性;
- 如果你一次执行多条查询语句,例如统计查询,报表查询,在这种场景下,多条查询 SQL 必须保证整体的读一致性,否则,在前条 SQL 查询之后,后条 SQL 查询之前,数据被其他用户改变,则该次整体的统计查询将会出现读数据不一致的状态,此时,应该启用事务支持
事务回滚规则
这些规则定义了哪些异常会导致事务回滚而哪些不会。默认情况下,事务只有遇到运行期异常(RuntimeException 的子类)时才会回滚,Error 也会导致事务回滚,但是,在遇到检查型(Checked)异常时不会回滚。

如果你想要回滚你定义的特定的异常类型的话,可以这样:
1 |
@Transactional注解
Exception 分为运行时异常 RuntimeException 和非运行时异常。事务管理对于企业应用来说是至关重要的,即使出现异常情况,它也可以保证数据的一致性。
当 @Transactional 注解作用于类上时,该类的所有 public 方法将都具有该类型的事务属性,同时,我们也可以在方法级别使用该标注来覆盖类级别的定义。如果类或者方法加了这个注解,那么这个类里面的方法抛出异常,就会回滚,数据库里面的数据也会回滚。
在 @Transactional 注解中如果不配置rollbackFor属性,那么事务只会在遇到RuntimeException的时候才会回滚,加上 rollbackFor=Exception.class,可以让事务在遇到非运行时异常时也回滚。
@Transactional 注解使用详解
- 方法 :推荐将注解使用于方法上,不过需要注意的是:该注解只能应用到 public 方法上,否则不生效。
- 类 :如果这个注解使用在类上的话,表明该注解对该类中所有的 public 方法都生效。
- 接口 :不推荐在接口上使用。
工作原理
- 当spring遍历容器中所有的切面,查找与当前实例化bean匹配的切面,这里就是获取事务属性切面,查找@Transactional注解及其属性值,然后根据得到的切面进入createProxy方法,创建一个AOP代理。
- 默认是使用JDK动态代理创建代理,如果目标类是接口,则使用JDK动态代理,否则使用Cglib。
- 获取的是当前目标方法对应的拦截器,里面是根据之前获取到的切面来获取相对应拦截器,这时候会得到TransactionInterceptor实例。如果获取不到拦截器,则不会创建MethodInvocation,直接调用目标方法。
- 在需要进行事务操作的时候,Spring会在调用目标类的目标方法之前进行开启事务、调用异常回滚事务、调用完成会提交事务。是否需要开启新事务,是根据@Transactional注解上配置的参数值来判断的。如果需要开启新事务,获取Connection连接,然后将连接的自动提交事务改为false,改为手动提交
- Spring并不会对所有类型异常都进行事务回滚操作,默认是只对Unchecked Exception(Error和RuntimeException)进行事务回滚操作。
从上面的分析可以看到,Spring使用AOP实现事务的统一管理,基本都是下面这两种情况:
- A类的a1方法没有标注@Transactional,a2方法标注@Transactional,在a1里面调用a2。a1方法是目标类A的原生方法,调用a1的时候即直接进入目标类A进行调用,在目标类A里面只有a2的原生方法,在a1里调用a2,即直接执行a2的原生方法,并不通过创建代理对象进行调用,所以并不会进入TransactionInterceptor的invoke方法,不会开启事务。
- 将@Transactional注解标注在非public方法上。内部使用AOP,所以必须是public修饰的方法才可以被代理
参数配置
@Transactional注解源码如下,里面包含了基本事务属性的配置:
1 |
|
@Transactional 的常用配置参数总结:
| 属性名 | 说明 |
|---|---|
| propagation | Propagation类型(枚举),事务的传播行为,默认值为 REQUIRED,可选的值在上面介绍过 |
| isolation | Isolation类型(枚举),事务的隔离级别,默认值采用 DEFAULT,可选的值在上面介绍过 |
| timeout | int类型,事务的超时时间,默认值为-1(不会超时)。如果超过该时间限制但事务还没有完成,则自动回滚事务。 |
| readOnly | boolean类型,指定事务是否为只读事务,默认值为 false。 |
| rollbackFor | Class<? extends Throwable>[]类型,默认为空数组。用于指定能够触发事务回滚的异常类型,并且可以指定多个异常类型。 |
其他参数:
- rollbackForClassName参数,String[]类型,默认为空数组。
- noRollbackFor参数,Class<? extends Throwable>[]类型,默认为空数组。
- noRollbackForClassName参数,String[]类型,默认为空数组。
一般不推荐使用rollbackForClassName和noRollbackForClassName两个参数,而用另外两个参数来代替,从参数的类型上就可以看出区别,使用字符串的缺点在于:如果不是用类的完整路径,就可能导致回滚设置对位于不同包中的同名类都生效;且如果类名写错,也无法得到IDE的动态提示。
但是,如果不配置任何与回滚有关的参数,不代表事务不会进行回滚,如果没有配置这四个选项,那么DefaultTransactionAttribute配置将会生效,具体的行为是,抛掷任何unchecked Exception都会触发回滚,当然包括所有的RuntimeException。
事务注解原理
我们知道,**@Transactional 的工作机制是基于 AOP 实现的,AOP 又是使用动态代理实现的。如果目标对象实现了接口,默认情况下会采用 JDK 的动态代理,如果目标对象没有实现了接口,会使用 CGLIB 动态代理。**
多提一嘴:createAopProxy() 方法 决定了是使用 JDK 还是 Cglib 来做动态代理,源码如下:
1 | public class DefaultAopProxyFactory implements AopProxyFactory, Serializable { |
如果一个类或者一个类中的 public 方法上被标注@Transactional 注解的话,Spring 容器就会在启动的时候为其创建一个代理类,在调用被@Transactional 注解的 public 方法的时候,实际调用的是,TransactionInterceptor 类中的 invoke()方法。这个方法的作用就是在目标方法之前开启事务,方法执行过程中如果遇到异常的时候回滚事务,方法调用完成之后提交事务。
TransactionInterceptor类中的invoke()方法内部实际调用的是TransactionAspectSupport类的invokeWithinTransaction()方法。由于新版本的 Spring 对这部分重写很大,而且用到了很多响应式编程的知识,这里就不列源码了。
Spring AOP 自调用问题
若同一类中的其他没有 @Transactional 注解的方法内部调用有 @Transactional 注解的方法,有@Transactional 注解的方法的事务会失效。
这是由于Spring AOP代理的原因造成的,因为只有当 @Transactional 注解的方法在类以外被调用的时候,Spring 事务管理才生效。
MyService 类中的method1()调用method2()就会导致method2()的事务失效。
1 |
|
解决办法就是避免同一类中自调用或者使用 AspectJ 取代 Spring AOP 代理。
@Transactional的使用注意事项总结
@Transactional注解只有作用到 public 方法上事务才生效,不推荐在接口上使用;- 避免同一个类中调用
@Transactional注解的方法,这样会导致事务失效; - 正确的设置
@Transactional的rollbackFor和propagation属性,否则事务可能会回滚失败; - 被
@Transactional注解的方法所在的类必须被 Spring 管理,否则不生效; - 底层使用的数据库必须支持事务机制,否则不生效;
- ……
Spring事务什么情况下回滚?
Spring事务回滚机制是这样的:当所拦截的方法有指定异常抛出,事务才会自动进行回滚。
默认配置下,事务只会对Error与RuntimeException及其子类这些UNChecked异常,做出回滚。一般的Exception这些Checked异常不会发生回滚(如果一般Exception想回滚要做出配置);
Spring事务try catch会回滚吗?
依赖spring事物时,当service层进行try catch异常捕获时,事物不会产生回滚,代码如下
1 | public void insertMsg(ConversationBean conversationBean){ |
此时异常被捕获,这种业务方法也就等于脱离了spring事务的管理,因为没有任何异常会从业务方法中抛出,全被捕获,导致spring异常抛出触发事务回滚策略失效。
解决此类问题时,需要在try catch中显示的抛出异常RuntimeException 然后在Controller层捕获异常并编写返回值,代码如下:
1 | public void insertMsg(ConversationBean conversationBean){ |
参考
- [总结]Spring 事务管理中@Transactional 的参数:http://www.mobabel.net/spring 事务管理中 transactional 的参数/
- Spring 官方文档:https://docs.spring.io/spring/docs/4.2.x/spring-framework-reference/html/transaction.html
- 《Spring5 高级编程》
- 透彻的掌握 Spring 中@transactional 的使用: https://www.ibm.com/developerworks/cn/java/j-master-spring-transactional-use/index.html
- Spring 事务的传播特性:https://github.com/love-somnus/Spring/wiki/Spring 事务的传播特性
- Spring 事务传播行为详解 :https://segmentfault.com/a/1190000013341344
- 全面分析 Spring 的编程式事务管理及声明式事务管理:https://www.ibm.com/developerworks/cn/education/opensource/os-cn-spring-trans/index.html
javaSpring学习(一)——Spring介绍
Spring介绍
一般说 Spring 框架指的都是 Spring Framework,它是很多模块的集合,使用这些模块可以很方便地协助我们进行开发。
Spring 最核心的思想就是不重新造轮子,开箱即用!
Spring框架的设计目标、设计理念以及核心
Spring设计目标:Spring为开发者提供一个一站式轻量级应用开发平台;
Spring设计理念:在JavaEE开发中,支持POJO和JavaBean开发方式,使应用面向接口开发,充分支持OO(面向对象)设计方法;Spring通过IoC容器实现对象耦合关系的管理,并实现依赖反转,将对象之间的依赖关系交给IoC容器,实现解耦;
POJO是普通java类,具有一部分getter/setter方法的那种类就可以称作POJO。相对于bean类缺少了:无参构造方法和序列化serializable接口。
Spring框架的核心:IoC容器和AOP模块。通过IoC容器管理POJO对象以及他们之间的耦合关系;通过AOP以动态非侵入的方式增强服务。
IoC让相互协作的组件保持松散的耦合,而AOP编程允许你把遍布于应用各层的功能分离出来形成可重用的功能组件。
Spring 提供的核心功能主要是 IoC 和 AOP。
- Spring 官网:https://spring.io/
- Github 地址: https://github.com/spring-projects/spring-framework
列举一些重要的 Spring 模块
下图对应的是 Spring4.x 版本。目前最新的 5.x 版本中 Web 模块的 Portlet 组件已经被废弃掉,同时增加了用于异步响应式处理的 WebFlux 组件。
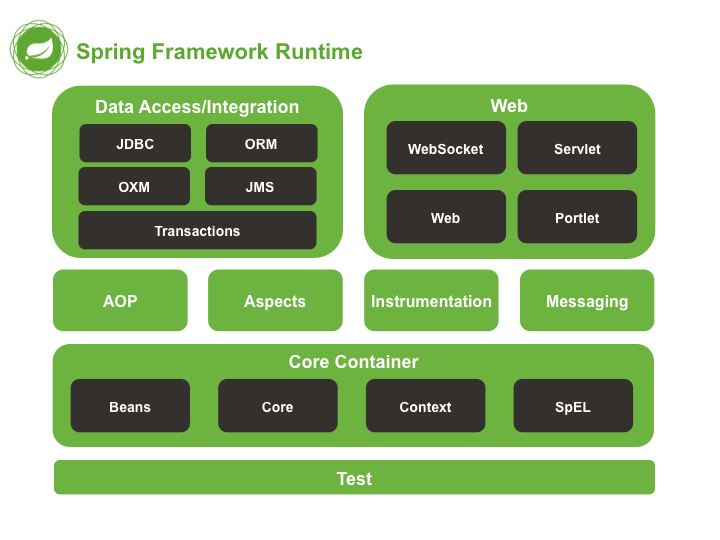
Spring Core
核心模块, Spring 其他所有的功能基本都需要依赖于该模块,主要提供 IoC 依赖注入功能的支持。
Spring Aspects
该模块为与 AspectJ 的集成提供支持。
Spring AOP
提供了面向切面的编程实现。
Spring Data Access/Integration :
Spring Data Access/Integration 由 5 个模块组成:
- spring-jdbc : 提供了对数据库访问的抽象 JDBC。不同的数据库都有自己独立的 API 用于操作数据库,而 Java 程序只需要和 JDBC API 交互,这样就屏蔽了数据库的影响。
- spring-tx : 提供对事务的支持。
- spring-orm : 提供对 Hibernate 等 ORM 框架的支持。
- spring-oxm : 提供对 Castor 等 OXM 框架的支持。
- spring-jms : Java 消息服务。
Spring Web
Spring Web 由 4 个模块组成:
- spring-web :对 Web 功能的实现提供一些最基础的支持。
- spring-webmvc : 提供对 Spring MVC 的实现。
- spring-websocket : 提供了对 WebSocket 的支持,WebSocket 可以让客户端和服务端进行双向通信。
- spring-webflux :提供对 WebFlux 的支持。WebFlux 是 Spring Framework 5.0 中引入的新的响应式框架。与 Spring MVC 不同,它不需要 Servlet API,是完全异步.
Spring Test
Spring 团队提倡测试驱动开发(TDD)。有了控制反转 (IoC)的帮助,单元测试和集成测试变得更简单。
Spring 的测试模块对 JUnit(单元测试框架)、TestNG(类似 JUnit)、Mockito(主要用来 Mock 对象)、PowerMock(解决 Mockito 的问题比如无法模拟 final, static, private 方法)等等常用的测试框架支持的都比较好。
Spring,Spring MVC,Spring Boot 之间什么关系?
很多人对 Spring,Spring MVC,Spring Boot 这三者傻傻分不清楚!这里简单介绍一下这三者,其实很简单,没有什么高深的东西。
Spring 包含了多个功能模块(上面刚刚提高过),其中最重要的是 Spring-Core(主要提供 IoC 依赖注入功能的支持) 模块, Spring 中的其他模块(比如 Spring MVC)的功能实现基本都需要依赖于该模块。
Spring MVC 是 Spring 中的一个很重要的模块,主要赋予 Spring 快速构建 MVC 架构的 Web 程序的能力。MVC 是模型(Model)、视图(View)、控制器(Controller)的简写,其核心思想是通过将业务逻辑、数据、显示分离来组织代码。
使用 Spring 进行开发各种配置过于麻烦比如开启某些 Spring 特性时,需要用 XML 或 Java 进行显式配置。于是,Spring Boot 诞生了!
Spring 旨在简化 J2EE 企业应用程序开发。Spring Boot 旨在简化 Spring 开发(减少配置文件,开箱即用!)。
Spring Boot 只是简化了配置,如果你需要构建 MVC 架构的 Web 程序,你还是需要使用 Spring MVC 作为 MVC 框架,只是说 Spring Boot 帮你简化了 Spring MVC 的很多配置,真正做到开箱即用!
Spring 框架中用到了哪些设计模式?
关于下面一些设计模式的详细介绍,可以看文章《面试官:“谈谈 Spring 中都用到了那些设计模式?”。》 。
- 工厂设计模式 : Spring 使用工厂模式通过
BeanFactory、ApplicationContext创建 bean 对象。 - 代理设计模式 : Spring AOP 功能的实现。
- 单例设计模式 : Spring下默认的bean均为singleton,可以通过singleton=“true|false” 或者 scope=”?”来指定。
- 模板方法模式 : Spring 中
jdbcTemplate、hibernateTemplate等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。 - 包装器设计模式 : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
- 观察者模式: Spring 事件驱动模型就是观察者模式很经典的一个应用。
- 适配器模式 : Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配
Controller。 - ……
JPA
如何使用 JPA 在数据库中非持久化一个字段?
假如我们有下面一个类:
1 | @Entity(name="USER") |
如果我们想让secrect 这个字段不被持久化,也就是不被数据库存储怎么办?我们可以采用下面几种方法:
1 | static String transient1; // not persistent because of static |
一般使用后面两种方式比较多
参考文章
JavaGuide/spring-knowledge-and-questions-summary.md at main · Snailclimb/JavaGuide (github.com)
《Spring 技术内幕》
https://www.journaldev.com/2696/spring-interview-questions-and-answers
https://www.edureka.co/blog/interview-questions/spring-interview-questions/
https://howtodoinjava.com/interview-questions/top-spring-interview-questions-with-answers/
http://www.tomaszezula.com/2014/02/09/spring-series-part-5-component-vs-bean/
https://stackoverflow.com/questions/34172888/difference-between-bean-and-autowired
javaSpring学习(二)——SpringCore
容器
容器是一种为某种特定组件的运行提供必要支持的一个软件环境。例如,Tomcat就是一个Servlet容器,它可以为Servlet的运行提供运行环境。类似Docker这样的软件也是一个容器,它提供了必要的Linux环境以便运行一个特定的Linux进程。
通常来说,使用容器运行组件,除了提供一个组件运行环境之外,容器还提供了许多底层服务。例如,Servlet容器底层实现了TCP连接,解析HTTP协议等非常复杂的服务,如果没有容器来提供这些服务,我们就无法编写像Servlet这样代码简单,功能强大的组件。早期的JavaEE服务器提供的EJB容器最重要的功能就是通过声明式事务服务,使得EJB组件的开发人员不必自己编写冗长的事务处理代码,所以极大地简化了事务处理。
Spring的核心就是提供了一个IoC容器,它可以管理所有轻量级的JavaBean组件,提供的底层服务包括组件的生命周期管理、配置和组装服务、AOP支持,以及建立在AOP基础上的声明式事务服务等。
ioc和aop
IoC 解决了以下问题:
- 创建了许多重复对象,造成大量资源浪费;
- 更换实现类需要改动多个地方;
- 创建和配置组件工作繁杂,给组件调用方带来极大不便。
AOP 解决了以下问题:
- 切面逻辑编写繁琐,有多少个业务方法就需要编写多少次。
Spring IOC
IoC(Inverse of Control:控制反转) 是一种设计思想,而不是一个具体的技术实现。
IOC的思想是:IoC的核心思想在于资源统一管理,你所持有的资源全部放入到IoC容器中,而你也只需要依赖IoC容器,该容器会自动为你装配所需要的具体依赖,而不是传统的在你的对象内部直接控制。对于spring框架来说,就是由spring来负责控制对象的生命周期和对象间的关系。
- 谁控制谁,控制什么:IoC 容器控制了对象;主要控制了外部资源获取(不只是对象包括比如文件等)
- 为何是反转,哪些方面反转了:传统应用程序是由我们自己在对象中主动控制去直接获取依赖对象,也就是正转;而反转则是由容器来帮忙创建及注入依赖对象;为何是反转?因为由容器帮我们查找及注入依赖对象,对象只是被动的接受依赖对象,所以是反转;哪些方面反转了?依赖对象的获取被反转了。
当某个角色(可能是一个Java实例,调用者)需要另一个角色(另一个Java实例,被调用者)的协助时,在 传统的程序设计过程中,通常由调用者来创建被调用者的实例。但在Spring里,创建被调用者的工作不再由调用者来完成,因此称为控制反转;创建被调用者 实例的工作通常由Spring容器来完成,然后注入调用者,因此也称为依赖注入。
注入内容包括:注入某个对象所需要的外部资源(包括对象、资源、常量数据)
为什么叫控制反转?
Spring所倡导的开发方式:所有的类都会在spring容器中登记,告诉spring你是个什么东西,你需要什么东西,然后spring会在系统运行到适当的时候,把你要的东西主动给你,同时也把你交给其他需要你的东西。所有的类的创建、销毁都由 spring来控制,也就是说控制对象生存周期的不再是引用它的对象,而是spring。对于某个具体的对象而言,以前是它控制其他对象,现在是所有对象都被spring控制,所以这叫控制反转。
- 控制 :指的是对象创建(实例化、管理)的权力
- 反转 :控制权交给外部环境(Spring 框架、IoC 容器)

其实IoC对编程带来的最大改变不是从代码上,而是从思想上,发生了“主从换位”的变化。应用程序原本是老大,要获取什么资源都是主动出击,但是在IoC/DI思想中,应用程序就变成被动的了,被动的等待IoC容器来创建并注入它所需要的资源了。
IoC很好的体现了面向对象设计法则之一—— 好莱坞法则:“别找我们,我们找你”;即由IoC容器帮对象找相应的依赖对象并注入,而不是由对象主动去找。
在 Spring 中, IoC 容器是 Spring 用来实现 IoC 的载体, IoC 容器实际上就是个 Map(key,value),Map 中存放的是各种对象。
Spring 时代我们一般通过 XML 文件来配置 Bean,后来开发人员觉得 XML 文件来配置不太好,于是 SpringBoot 注解配置就慢慢开始流行起来。
IOC/DI
引言:Spring 能有效地组织J2EE应用各层的对象。不管是控制层的Action对象,还是业务层的Service对象,还是持久层的DAO对象,都可在Spring的 管理下有机地协调、运行。Spring将各层的对象以松耦合的方式组织在一起,Action对象无须关心Service对象的具体实现,Service对 象无须关心持久层对象的具体实现,各层对象的调用完全面向接口。当系统需要重构时,代码的改写量将大大减少。
上面所说的一切都得宜于Spring的核心机制,依赖注入。依赖注入让bean与bean之间以配置文件组织在一起,而不是以硬编码的方式耦合在一起。
IoC的一个重点是在系统运行中,动态的向某个对象提供它所需要的其他对象。这一点是通过DI(Dependency Injection,依赖注入)来实现的。
如果调用者使用到被调用对象才会从spring容器中取出依赖的对象注入到使用的类中,如果不用则会放回spring容器的对象池中,做到内存节省并且代码的耦合度也降低。面向接口编程中,让依赖注入只需要找到符合规范的接口注入即可实现调用者和被调用者解耦。对象的调用关系由spring管理。
spring的依赖注入对调用者和被调用者几乎没有任何要求,完全支持对pojo之间依赖关系的管理
IoC和DI由什么关系呢?其实它们是同一个概念的不同角度描述,相对IoC 而言,“依赖注入”明确描述了“被注入对象依赖IoC容器配置依赖对象”。
构造器依赖注入和 Setter方法注入的区别
| 构造函数注入 | setter 注入 |
|---|---|
| 没有部分注入 | 有部分注入 |
| 不会覆盖 setter 属性 | 会覆盖 setter 属性 |
| 任意修改都会创建一个新实例 | 任意修改不会创建一个新实例 |
| 适用于设置很多属性 | 适用于设置少量属性 |
两种依赖方式都可以使用,构造器注入和Setter方法注入。最好的解决方案是用构造器参数实现强制依赖,setter方法实现可选依赖。
装配bean
- Spring的bean容器也叫beanfactory,我们常用的applicationcontext实际上内部有一个listablebeanfactory实际存储bean的map。
- bean加载过程:spring容器加载时先读取配置文件,一般是xml,然后解析xml,找到其中所有bean,依次解析,然后生成每个bean的beandefinition,存在一个map中,根据beanid映射实际bean的map。
- bean初始化:加载完以后,如果不启用懒加载模式,则默认使用单例加载,在注册完bean以后,可以获取到beandefinition信息,然后根据该信息首先先检查依赖关系,如果依赖其他bean则先加载其他bean,然后通过反射的方式即newinstance创建一个单例bean。
为什么要用反射呢,因为实现类可以通过配置改变,但接口是一致的,使用反射可以避免实现类改变时无法自动进行实例化。
当然,bean也可以使用原型方式加载,使用原型的话,每次创建bean都会是全新的。
第一步:
完成类的功能;例如MailService和一个UserService,实现用户注册和登录;
1 | public class UserService { |
第二步:
编写一个特定的application.xml配置文件,告诉Spring的IoC容器应该如何创建并组装Bean:
1 |
|
注意观察上述配置文件,其中与XML Schema相关的部分格式是固定的,我们只关注两个<bean ...>的配置:
- 每个
<bean ...>都有一个id标识,相当于Bean的唯一ID; - 在
userServiceBean中,通过<property name="..." ref="..." />注入了另一个Bean; - Bean的顺序不重要,Spring根据依赖关系会自动正确初始化。
把上述XML配置文件用Java代码写出来,就像这样:
1 | UserService userService = new UserService(); |
只不过Spring容器是通过读取XML文件后使用反射完成的。
如果注入的不是Bean,而是boolean、int、String这样的数据类型,则通过value注入
1 | <bean id="dataSource" class="com.zaxxer.hikari.HikariDataSource"> |
第三步:
创建一个Spring的IoC容器实例,然后加载配置文件,让Spring容器为我们创建并装配好配置文件中指定的所有Bean,这只需要一行代码:
1 | ApplicationContext context = new ClassPathXmlApplicationContext("application.xml"); |
接下来,我们就可以从Spring容器中“取出”装配好的Bean然后使用它:
1 | // 获取Bean: |
完整的main()方法如下:
1 | public class Main { |
ApplicationContext
Spring的IoC容器接口是
ApplicationContext,并提供了多种实现类;通过XML配置文件创建IoC容器时,使用
ClassPathXmlApplicationContext;持有IoC容器后,通过
getBean()方法获取Bean的引用。
我们从创建Spring容器的代码:
1 | ApplicationContext context = new ClassPathXmlApplicationContext("application.xml"); |
可以看到,Spring容器就是ApplicationContext,它是一个接口,有很多实现类,这里我们选择ClassPathXmlApplicationContext,表示它会自动从classpath中查找指定的XML配置文件。
获得了ApplicationContext的实例,就获得了IoC容器的引用。从ApplicationContext中我们可以根据Bean的ID获取Bean,但更多的时候我们根据Bean的类型获取Bean的引用:
1 | UserService userService = context.getBean(UserService.class); |
Spring还提供另一种IoC容器叫BeanFactory,使用方式和ApplicationContext类似:
1 | BeanFactory factory = new XmlBeanFactory(new ClassPathResource("application.xml")); |
BeanFactory和ApplicationContext的区别在于,BeanFactory的实现是按需创建,即第一次获取Bean时才创建这个Bean,而ApplicationContext会一次性创建所有的Bean。实际上,ApplicationContext接口是从BeanFactory接口继承而来的,并且,ApplicationContext提供了一些额外的功能,包括国际化支持、事件和通知机制等。通常情况下,我们总是使用ApplicationContext,很少会考虑使用BeanFactory。
使用Annotation配置
使用XML配置的优点是所有的Bean都能一目了然地列出来,并通过配置注入能直观地看到每个Bean的依赖。它的缺点是写起来非常繁琐,每增加一个组件,就必须把新的Bean配置到XML中。
使用Annotation配置,可以完全不需要XML,让Spring自动扫描Bean并组装它们。
相关阅读
Spring AOP
AOP(Aspect-Oriented Programming:面向切面编程)利用一种称为“横切”的技术,剖解开封装的对象内部,并将那些影响了 多个类的公共行为封装到一个可重用模块,并将其名为“Aspect”,即方面。所谓“方面”,简单地说,就是将那些与业务无关,却为业务模块所共同调用的 逻辑或责任封装起来,比如日志记录,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。
AOP中的相关概念
Advice(通知):Advice 定义了在Pointcut里面定义的程序点具体要做的操作,它通过 before、after 和 around 来区别是在每个 joint point 之前、之后还是代替执行的代码。【就是你想要的功能,也就是上面说的 安全,事物,日志等。你给先定义好,然后在想用的地方用一下。】
Joint point(连接点):spring允许你使用通知的地方,那可真就多了,基本每个方法的前,后(两者都有也行),或抛出异常时都可以是连接点,spring只支持方法连接点.其他如aspectJ还可以让你在构造器或属性注入时都行,不过那不是咱关注的,只要记住,和方法有关的前前后后(抛出异常),都是连接点。Pointcut(切点):表示一组 joint point,这些 joint point 或是通过逻辑关系组合起来,或是通过通配、正则表达式等方式集中起来,它定义了相应的 Advice 将要发生的地方。【你的一个类里,有15个方法,那就有几十个连接点了对把,但是你并不想在所有方法附近都使用通知(使用叫织入,以后再说),你只想让其中的几个,在调用这几个方法之前,之后或者抛出异常时干点什么,那么就用切点来定义这几个方法,让切点来筛选连接点,选中那几个你想要的方法。】
Aspect(切面): 切面是通知和切入点的结合。现在发现了吧,没连接点什么事情,连接点就是为了让你好理解切点,搞出来的,明白这个概念就行了。通知说明了干什么和什么时候干(什么时候通过方法名中的before,after,around等就能知道),而切入点说明了在哪干(指定到底是哪个方法),这就是一个完整的切面定义。introduction(引入):允许我们向现有的类添加新方法属性。这不就是把切面(也就是新方法属性:通知定义的)用到目标类中吗Target(目标对象):引入中所提到的目标类,也就是要被通知的对象,也就是真正的业务逻辑,他可以在毫不知情的情况下,被咱们织入切面。而自己专注于业务本身的逻辑。Weaving(织入):把切面应用到目标对象来创建新的代理对象的过程。有3种方式,spring采用的是运行时,为什么是运行时,后面解释。关键就是:切点定义了哪些连接点会得到通知
proxy(代理):怎么实现整套aop机制的,都是通过代理。
AOP原理理解
spring用代理类包裹切面,把他们织入到Spring管理的bean中。也就是说代理类伪装成目标类,它会截取对目标类中方法的调用,让调用者对目标类的调用都先变成调用伪装类,伪装类中就先执行了切面,再把调用转发给真正的目标bean。
现在可以自己想一想,怎么搞出来这个伪装类,才不会被调用者发现(过JVM的检查,JAVA是强类型检查,哪里都要检查类型)。
1.实现和目标类相同的接口,我也实现和你一样的接口,反正上层都是接口级别的调用,这样我就伪装成了和目标类一样的类(实现了同一接口,咱是兄弟了),也就逃过了类型检查,到java运行期的时候,利用多态的后期绑定(所以spring采用运行时),伪装类(代理类)就变成了接口的真正实现,而他里面包裹了真实的那个目标类,最后实现具体功能的还是目标类,只不过伪装类在之前干了点事情(写日志,安全检查,事物等)。
顺着这个思路想,要是本身这个类就没实现一个接口呢,你怎么伪装我,我就压根没有机会让你搞出这个双胞胎的弟弟,那么就用第2种代理方式,创建一个目标类的子类,生个儿子,让儿子伪装我
2.生成子类调用,这次用子类来做为伪装类,当然这样也能逃过JVM的强类型检查,我继承的吗,当然查不出来了,子类重写了目标类的所有方法,当然在这些重写的方法中,不仅实现了目标类的功能,还在这些功能之前,实现了一些其他的(写日志,安全检查,事物等)。
这次的对比就是,儿子先从爸爸那把本事都学会了,所有人都找儿子办事情,但是儿子每次办和爸爸同样的事之前,都要收点小礼物(写日志),然后才去办真正的事。当然爸爸是不知道儿子这么干的了。这里就有件事情要说,某些本事是爸爸独有的(final的),儿子学不了,学不了就办不了这件事,办不了这个事情,自然就不能收人家礼了。
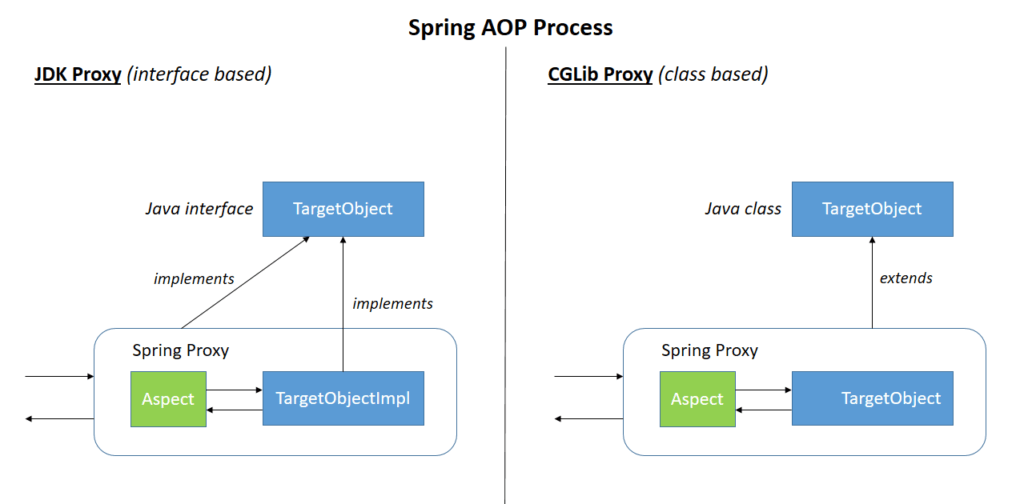
前一种兄弟模式,spring会使用JDK的java.lang.reflect.Proxy类,它允许Spring动态生成一个新类来实现必要的接口,织入通知,并且把对这些接口的任何调用都转发到目标类。
后一种父子模式,spring使用CGLIB库生成目标类的一个子类,在创建这个子类的时候,spring织入通知,并且把对这个子类的调用委托到目标类。
相比之下,还是兄弟模式好些,他能更好的实现松耦合,尤其在今天都高喊着面向接口编程的情况下,父子模式只是在没有实现接口的时候,也能织入通知,应当做一种例外。
Spring实现AOP——动态代理
Spring AOP就是基于动态代理的,如果要代理的对象,实现了某个接口,那么Spring AOP会使用JDK Proxy,去创建代理对象,而对于没有实现接口的对象,就无法使用JDK Proxy去进行代理了(为啥?你写一个JDK Proxy的demo就知道了),这时候Spring AOP会使用Cglib,生成一个被代理对象的子类,来作为代理.
- JDK动态代理:其代理对象必须是某个接口的实现,它是通过在运行期间创建一个接口的实现类来完成对目标对象的代理;其核心的两个类是InvocationHandler和Proxy。
- CGLIB代理:实现原理类似于JDK动态代理,只是它在运行期间生成的代理对象是针对目标类扩展的子类。CGLIB是高效的代码生成包,底层是依靠ASM(开源的java字节码编辑类库)操作字节码实现的,性能比JDK强;需要引入包asm.jar和cglib.jar。
如下图所示:
AOP:
AOP的切面,切点,增强器一般也是配置在xml文件中的,所以bean容器在解析xml时会找到这些内容,并且首先创建增强器bean的实例。
基于上面创建bean的过程,AOP起到了什么作用呢,或者是是否有参与到其中呢,答案是有的。
在获得beandefinition的时候,spring容器会检查该bean是否有aop切面所修饰,是否有能够匹配切点表达式的方法,如果有的话,在创建bean之前,会将bean重新封装成一个动态代理的对象。
代理类会为bean增加切面中配置的advisor增强器,然后返回bean的时候实际上返回的是一个动态代理对象。
所以我们在调用bean的方法时,会自动织入切面的增强器,当然,动态代理既可以选择jdk增强器,也可以选择cglib增强器。
Spring事务:
spring事务其实是一种特殊的aop方式。在spring配置文件中配置好事务管理器和声明式事务注解后,就可以使用@transactional进行事务方法的处理了。
事务管理器的bean中会配置基本的信息,然后需要配置事务的增强器,不同方法使用不同的增强器。当然如果使用注解的话就不用这么麻烦了。
然后和aop的动态代理方式类似,当Spring容器为bean生成代理时,会注入事务的增强器,其中实际上实现了事务中的begin和commit,所以执行方法的过程实际上就是在事务中进行的。
AOP使用场景
- Authentication 权限检查
- Caching 缓存
- Context passing 内容传递
- Error handling 错误处理
- Lazy loading 延迟加载
- Debugging 调试
- logging, tracing, profiling and monitoring 日志记录,跟踪,优化,校准
- Performance optimization 性能优化,效率检查
- Persistence 持久化
- Resource pooling 资源池
- Synchronization 同步
- Transactions 事务管理
过滤器filter、拦截器interceptor、和AOP的区别与联系
filter过滤器
- 过滤器拦截web访问url地址。 严格意义上讲,filter只是适用于web中,依赖于Servlet容器,利用Java的回调机制进行实现。
- Filter过滤器:和框架无关,可以控制最初的http请求,但是更细一点的类和方法控制不了。
- **过滤器可以拦截到方法的请求和响应(ServletRequest request, ServletResponse response)**,并对请求响应做出像响应的过滤操作,
- 比如设置字符编码,鉴权操作等
Interceptor拦截器
- 拦截器拦截以 .action结尾的url,拦截Action的访问。 Interfactor是基于Java的反射机制(APO思想)进行实现,不依赖Servlet容器。
- 拦截器可以在方法执行之前(preHandle)和方法执行之后(afterCompletion)进行操作,回调操作(postHandle),可以获取执行的方法的名称,请求(HttpServletRequest)
- Interceptor:可以控制请求的控制器和方法,但控制不了请求方法里的参数(只能获取参数的名称,不能获取到参数的值)
- (用于处理页面提交的请求响应并进行处理,例如做国际化,做主题更换,过滤等)。
Spring AOP拦截器
- 只能拦截Spring管理Bean的访问(业务层Service)。 具体AOP详情参照 Spring AOP:原理、 通知、连接点、切点、切面、表达式
- 实际开发中,AOP常和事务结合:Spring的事务管理:声明式事务管理(切面)
- AOP操作可以对操作进行横向的拦截,最大的优势在于他可**以获取执行方法的参数( ProceedingJoinPoint.getArgs() )**,对方法进行统一的处理。
- Aspect : 可以自定义切入的点,有方法的参数,但是拿不到http请求,可以通过其他方式如RequestContextHolder获得( ServletRequestAttributes servletRequestAttributes= (ServletRequestAttributes) RequestContextHolder.getRequestAttributes(); )。
- 常见**使用日志,事务,请求参数安全验证
Spring AOP 和 AspectJ AOP 有什么区别?
Spring AOP 属于运行时增强,而 AspectJ 是编译时增强。 Spring AOP 基于代理(Proxying),而 AspectJ 基于字节码操作(Bytecode Manipulation)。
Spring AOP 已经集成了 AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。AspectJ 相比于 Spring AOP 功能更加强大,但是 Spring AOP 相对来说更简单,
如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择 AspectJ ,它比 Spring AOP 快很多。
参考文章
java-maven学习(六)——单元测试
单元测试概念
单元测试(Unit Testing):是指对软件中的最小可测试单元进行检查和验证。
这个定义有点抽象,这里举几个单元测试的特性:一般是一个方法配几个单元测试、单元测试不应该依赖外部系统、单元测试运行速度很快、单元测试不应该造成测试环境的脏数据、单元测试可以重复运行。
- 单元测试就是测试某个方法是否符合设计的逻辑,而且只测试这个方法,不涉及其他依赖方法的测试。
这里要注意区分集成测试和单元测试。
- 集成测试的是测试某个模块的功能,通俗的讲就是测试模块所有用到类和方法。
单元测试的重要性
“每当我要进行重构的时候,第一个步骤永远相同:我得为即将修改的代码建立一组可靠的测试环境 ” ——摘自《重构:改善既有代码的设计》
- 单元测试使得我们可以放心修改、重构业务代码,而不用担心修改某处代码后带来的副作用。
- 单元测试使得系统具备更好的可维护性、具备更好的可读性。
- 单元测试能提高代码质量,可以帮助我们反思模块划分的合理性,如果一个单元测试写得逻辑非常复杂、或者说一个函数复杂到无法写单测,那就说明模块的抽象有问题。
单元测试基本原则
首先要明确单元测试的一些基本原则,优秀的单元测试具有以下特点:
- 自动的、可重复的
- 容易实现
- 一旦写好,将来都可使用
- 任何人都可运行
- 单击一个按钮就可运行
- 可以快速地运行
单元测试并非是随手写来验证功能的临时代码,而是需要符合 AIR 原则,所以编写起来是需要一定的功力的。
- 【强制】好的单元测试必须遵守AIR原则。
说明:单元测试在线上运行时,感觉像空气(AIR)一样并不存在,但在测试质量的保障上,却是非常关键的。好的单元测试宏观上来说,具有自动化、独立性、可重复执行的特点。
- A:Automatic(自动化)
- I:Independent(独立性)
- R:Repeatable(可重复)
- 【强制】单元测试应该是全自动执行的,并且非交互式的。测试用例通常是被定期执行的,执行过程必须完全自动化才有意义。输出结果需要人工检查的测试不是一个好的单元测试。单元测试中不准使用System.out来进行人肉验证,必须使用assert来验证。
- 【强制】保持单元测试的独立性。为了保证单元测试稳定可靠且便于维护,单元测试用例之间决不能互相调用,也不能依赖执行的先后次序。
反例:method2需要依赖method1的执行,将执行结果作为method2的输入。
- 【强制】单元测试是可以重复执行的,不能受到外界环境的影响。
说明:单元测试通常会被放到持续集成中,每次有代码check in时单元测试都会被执行。如果单测对外部环境(网络、服务、中间件等)有依赖,容易导致持续集成机制的不可用。
正例:为了不受外界环境影响,要求设计代码时就把SUT的依赖改成注入,在测试时用spring 这样的DI框架注入一个本地(内存)实现或者Mock实现。
- 【强制】对于单元测试,要保证测试粒度足够小,有助于精确定位问题。单测粒度至多是类级别,一般是方法级别。
说明:只有测试粒度小才能在出错时尽快定位到出错位置。单测不负责检查跨类或者跨系统的交互逻辑,那是集成测试的领域。
- 【强制】核心业务、核心应用、核心模块的增量代码确保单元测试通过。
说明:新增代码及时补充单元测试,如果新增代码影响了原有单元测试,请及时修正。
JUnit
在Java的单元测试领域主流工具为JUnit与Mockito。JUnit 负责写单元测试业务逻辑,Mockito负责mock依赖。
JUnit5的主要特性:
- 提供全新的断言和测试注解,支持测试类内嵌
- 更丰富的测试方式:支持动态测试,重复测试,参数化测试等
- 实现了模块化,让测试执行和测试发现等不同模块解耦,减少依赖
- 提供对 Java 8 的支持,如 Lambda 表达式,Sream API等。
JUnit5 包含3个部分:
JUnit Platform: 用于JVM上启动测试框架的基础服务,提供命令行,IDE和构建工具等方式执行测试的支持。
JUnit Jupiter:包含 JUnit 5 新的编程模型和扩展模型,主要就是用于编写测试代码和扩展代码。
JUnit Vintage:用于在JUnit 5 中兼容运行 JUnit3.x 和 JUnit4.x 的测试用例。
JUnit5常见用法介绍
首先,在 Maven 工程里引入 JUnit 5 的依赖坐标,需注意的是当前JDK 环境要在 Java 8 以上。
1 | <dependency> |
第一个测试用例
引入JUnit 5,我们可以先快速编写一个简单的测试用例,从这个测试用例来认识初步下 JUnit 5:
1 |
|
直接运行这个测试用例,可以看到控制台日志如下:

可以看到左边一栏的结果里显示测试项名称就是我们在测试类和方法上使用 @DisplayName 设置的名称,这个注解就是 JUnit 5 引入,用来定义一个测试类并指定用例在测试报告中的展示名称,这个注解可以使用在类上和方法上,在类上使用它就表示该类为测试类,在方法上使用则表示该方法为测试方法。
1 |
|
再来看下示例代码中使用到的一对注解 **@BeforeAll **和 @AfterAll ,它们定义了整个测试类在开始前以及结束时的操作,只能修饰静态方法,主要用于在测试过程中所需要的全局数据和外部资源的初始化和清理。
@BeforeEach 和 @AfterEach 所标注的方法会在每个测试用例方法开始前和结束时执行,主要是负责该测试用例所需要的运行环境的准备和销毁。
禁用执行测试:@Disabled
当我们希望在运行测试类时,跳过某个测试方法,正常运行其他测试用例时,我们就可以用上 @Disabled 注解,表明该测试方法处于不可用,执行测试类的测试方法时不会被 JUnit 执行。
下面看下使用 @Disbaled 之后的运行效果,在原来测试类中添加如下代码:
1 |
|
运行后看到控制台日志如下,用 @Disabled 标记的方法不会执行,只有单独的方法信息打印:
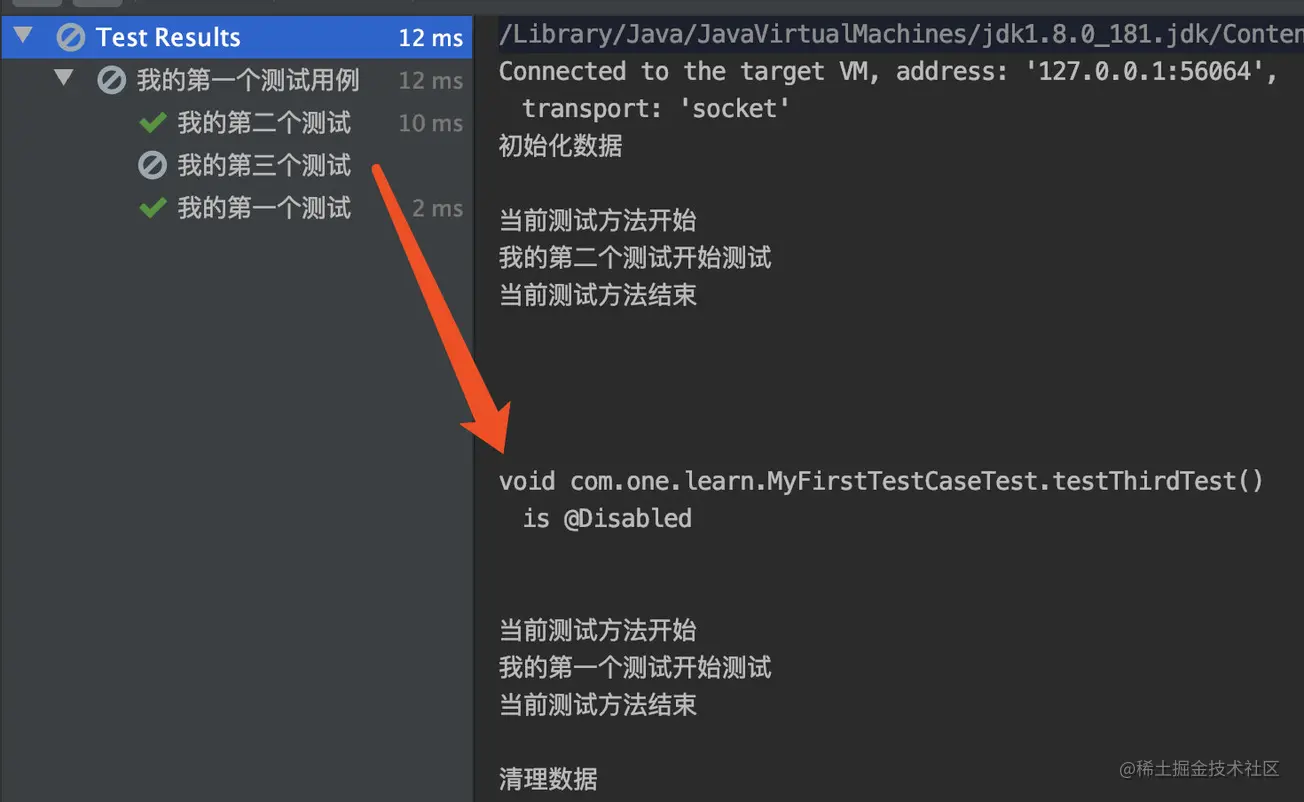
@Disabled 也可以使用在类上,用于标记类下所有的测试方法不被执行,一般使用对多个测试类组合测试的时候。
内嵌测试类:@Nested
当我们编写的类和代码逐渐增多,随之而来的需要测试的对应测试类也会越来越多。为了解决测试类数量爆炸的问题,JUnit 5提供了@Nested 注解,能够以静态内部成员类的形式对测试用例类进行逻辑分组。 并且每个静态内部类都可以有自己的生命周期方法, 这些方法将按从外到内层次顺序执行。 此外,嵌套的类也可以用@DisplayName 标记,这样我们就可以使用正确的测试名称。下面看下简单的用法:
1 |
|
运行所有测试用例后,在控制台能看到如下结果:

重复性测试:@RepeatedTest
在 JUnit 5 里新增了对测试方法设置运行次数的支持,允许让测试方法进行重复运行。当要运行一个测试方法 N次时,可以使用 @RepeatedTest 标记它,如下面的代码所示:
1 |
|
运行后测试方法会执行3次,在 IDEA 的运行效果如下图所示:
这是基本的用法,我们还可以对重复运行的测试方法名称进行修改,利用 @RepeatedTest 提供的内置变量,以占位符方式在其 name 属性上使用,下面先看下使用方式和效果:
1 |
|

@RepeatedTest 注解内用 currentRepetition 变量表示已经重复的次数,totalRepetitions 变量表示总共要重复的次数,displayName 变量表示测试方法显示名称,我们直接就可以使用这些内置的变量来重新定义测试方法重复运行时的名称。
新的断言
在断言 API 设计上,JUnit 5 进行显著地改进,并且充分利用 Java 8 的新特性,特别是 Lambda 表达式,最终提供了新的断言类: org.junit.jupiter.api.Assertions 。许多断言方法接受 Lambda 表达式参数,在断言消息使用 Lambda 表达式的一个优点就是它是延迟计算的,如果消息构造开销很大,这样做一定程度上可以节省时间和资源。
现在还可以将一个方法内的多个断言进行分组,使用 assertAll 方法如下示例代码:
1 |
|
如果分组断言中任一个断言的失败,都会将以 MultipleFailuresError 错误进行抛出提示。
超时操作的测试:assertTimeoutPreemptively
当我们希望测试耗时方法的执行时间,并不想让测试方法无限地等待时,就可以对测试方法进行超时测试,JUnit 5 对此推出了断言方法 assertTimeout,提供了对超时的广泛支持。
假设我们希望测试代码在一秒内执行完毕,可以写如下测试用例:
1 |
|
这个测试运行失败,因为代码执行将休眠两秒钟,而我们期望测试用例在一秒钟之内成功。但是如果我们把休眠时间设置一秒钟,测试仍然会出现偶尔失败的情况,这是因为测试方法执行过程中除了目标代码还有额外的代码和指令执行会耗时,所以在超时限制上无法做到对时间参数的完全精确匹配。
异常测试:assertThrows
我们代码中对于带有异常的方法通常都是使用 try-catch 方式捕获处理,针对测试这样带有异常抛出的代码,而 JUnit 5 提供方法 Assertions#assertThrows(Class<T>, Executable) 来进行测试,第一个参数为异常类型,第二个为函数式接口参数,跟 Runnable 接口相似,不需要参数,也没有返回,并且支持 Lambda表达式方式使用,具体使用方式可参考下方代码:
1 |
|
当Lambda表达式中代码出现的异常会跟首个参数的异常类型进行比较,如果不属于同一类异常,就会控制台输出如下类似的提示:org.opentest4j.AssertionFailedError: Unexpected exception type thrown ==> expected: <IllegalArgumentException> but was: <...Exception>
JUnit 5 参数化测试
要使用 JUnit 5 进行参数化测试,除了 junit-jupiter-engine 基础依赖之外,还需要另个模块依赖:junit-jupiter-params,其主要就是提供了编写参数化测试 API。同样方式,把相同版本的对应依赖引入 Maven 工程中:
1 | <dependency> |
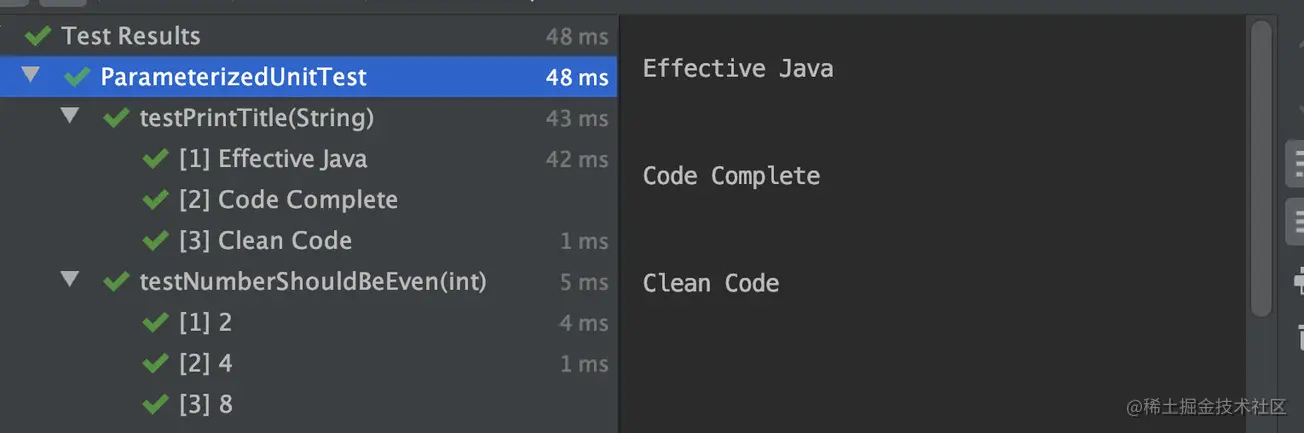
基本数据源测试: @ValueSource
@ValueSource 是 JUnit 5 提供的最简单的数据参数源,支持 Java 的八大基本类型和字符串,Class,使用时赋值给注解上对应类型属性,以数组方式传递,示例代码如下:
1 | public class ParameterizedUnitTest { |
@ParameterizedTest 作为参数化测试的必要注解,替代了 @Test 注解。任何一个参数化测试方法都需要标记上该注解。
运行测试,结果如下图所示,针对 @ValueSource 里每个参数都会运行目标方法,一旦哪个参数运行测试失败,就意味着该测试方法不通过。
CSV 数据源测试:@CsvSource
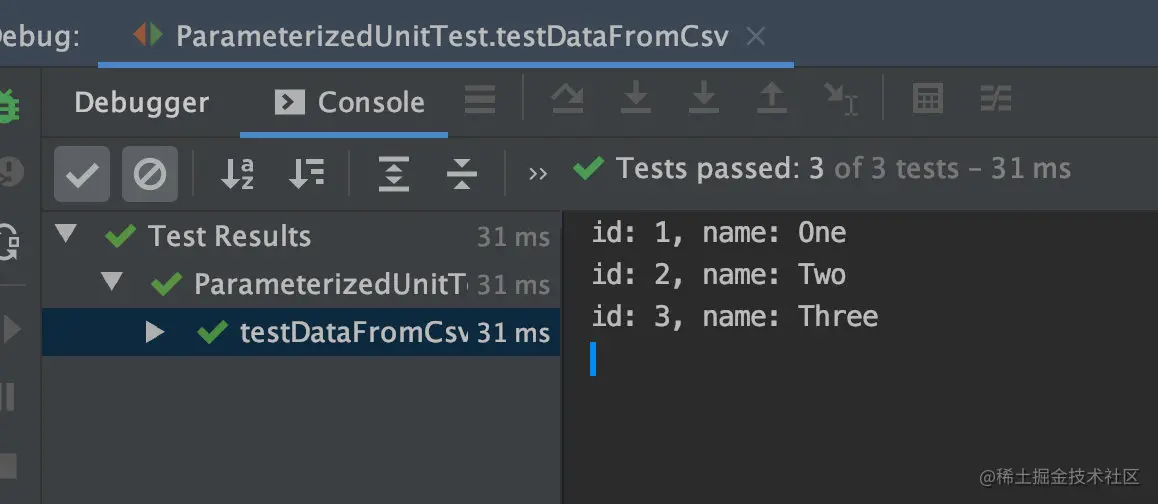
通过 @CsvSource 可以注入指定 CSV 格式 (comma-separated-values) 的一组数据,用每个逗号分隔的值来匹配一个测试方法对应的参数,下面是使用示例:
1 |
|
运行结果如图所示,除了用逗号分隔参数外,@CsvSource 还支持自定义符号,只要修改它的 delimiter 即可,默认为 ,。
JUnit 还提供了读取外部 CSV 格式文件数据的方式作为数据源的实现,我们只要用 @CsvFileSource 指定资源文件路径即可,使用起来跟 @CsvSource 一样简单这里就不再重复演示了。
@CsvFileSource 指定的资源文件路径时要以
/开始,寻找当前测试资源目录下文件。
除了上面提到的三种数据源方式外,JUnit 还提供了以下三种数据源:
- @EnumSource:允许我们通过参数值,给指定 Enum 枚举类型传入,构造出枚举类型中特定的值。
- @MethodSource:指定一个返回的 Stream / Array / 可迭代对象 的方法作为数据源。 需要注意的是该方法必须是静态的,并且不能接受任何参数。
- @ArgumentSource:通过实现 ArgumentsProvider 接口的参数类来作为数据源,重写它的
provideArguments方法可以返回自定义类型的 Stream,作为测试方法所需要的数据使用。
java-maven学习(五)——Nexus搭建私服
序言
什么是私服
私服是指私有服务器,是假设在局域网的一种特殊的远程仓库,目的是代理远程仓库及部署第三方构建.有了私服之后,当maven需要下载构件时,直接请求私服,私服上存在则下载到本地仓库;否则,私服请求外部的远程仓库,将构件下载到私服,在提供给本地仓库下载。
什么是Nexus
Nexus是一个强大的maven仓库管理器,它极大的简化了本地内部仓库的维护和外部仓库的访问
Nexus是一套开箱即用的系统不需要数据库,它使用文件系统加Lucene来组织数据
Nexus使用ExtJS来开发界面,利用Restlet来提供完整的REST APIs,通过IDEA和Eclipse集成使用
Nexus支持WebDAV与LDAP安全身份认证
Nexus提供了强大的仓库管理功能,构件搜索功能,它基于REST,友好的UI是一个extjs的REST客户端,占用较少的内存,基于简单文件系统而非数据库。
Nexus搭建私服的优点
- 内网访问,节省外网带宽。
- 一次外网下载,内网所有用户就可以只下载私服缓存,加速 Maven 项目构建。
- 允许上传和下载私有库,并且不被外部访问,更加安全。
- 减少外部网络因素,提供项目构建的稳定性。
- 方便内部项目服务的依赖引用,而不需要其他项目的完整源代码。
- 有利于公共构件的维护
- 提高工作效率
java-maven学习(三)——pom文件(二)
build——项目构建需要的信息
1 | <!--构建项目需要的信息 --> |
build标签定义了构建项目需要的信息,这部分信息对于定制化项目构建是非常重要的。这里会根据build的子元素的特点,简单地分类讲解。
1、路径管理
1 | <!--------------------- 路径管理(在遵循约定大于配置原则下,不需要配置) ---------------------> |
路径管理定义了各种源码和编译结果的输出路径。如果遵循maven默认的路径约定,这里的几个元素是不需要配置的。这些元素包括:
- sourceDirectory:项目源码目录,定义的是相对于pom文件的相对路径;
- testSourceDirectory:项目单元测试源码目录,定义的也是是相对于pom文件的相对路径;
- outputDirectory:被编译过的应用程序class文件存放的目录,也是是相对于pom文件的相对路径;
- testOutoutDIrectory:被编译过的测试class文件存放的目录,也是是相对于pom文件的相对路径;
- scriptSourceDirectory:项目脚本源码目录,也是是相对于pom文件的相对路径。由于脚本是解释性的语言,所以该目录下的内容,会直接被拷贝到输出目录,而不需要编译。
目录元素集合存在于 build 元素中,它为整个 POM 设置了各种目录结构。由于它们在配置文件构建中不存在,所以这些不能由配置文件更改。
如果上述目录元素的值设置为绝对路径(扩展属性时),则使用该目录。否则,它是相对于基础构建目录:${basedir}。
2、资源管理
资源的配置。资源文件通常不是代码,不需要编译,而是在项目需要捆绑使用的内容。
1 | <!--------------------- 资源管理 ---------------------> |
- resources: 资源元素的列表,每个资源元素描述与此项目关联的文件和何处包含文件。
- targetPath: 指定从构建中放置资源集的目录结构。目标路径默认为基本目录。将要包装在 jar 中的资源的通常指定的目标路径是 META-INF。
- filtering: 值为 true 或 false。表示是否要为此资源启用过滤。请注意,该过滤器
* .properties文件不必定义为进行过滤 - 资源还可以使用默认情况下在 POM 中定义的属性(例如$ {project.version}),并将其传递到命令行中“-D”标志(例如,“-Dname = value”)或由 properties 元素显式定义。过滤文件覆盖上面。 - directory: 值定义了资源的路径。构建的默认目录是
${basedir}/src/main/resources。 - includes: 一组文件匹配模式,指定目录中要包括的文件,使用*作为通配符。
- excludes: 与
includes类似,指定目录中要排除的文件,使用*作为通配符。注意:如果include和exclude发生冲突,maven 会以exclude作为有效项。 - testResources:
testResources与resources功能类似,区别仅在于:testResources指定的资源仅用于 test 阶段,并且其默认资源目录为:${basedir}/src/test/resources。
3、插件管理
与 dependencyManagement 很相似,在当前 POM 中仅声明插件,而不是实际引入插件。子 POM 中只配置 groupId 和 artifactId 就可以完成插件的引用,且子 POM 有权重写 pluginManagement 定义。
插件管理相关的元素有两个,包括pluginManagement和plugins。pluginManagement中有子元素plugins,它和project下的直接子元素plugins的区别是,pluginManagement主要是用来声明子项目可以引用的默认插件信息,这些插件如果只写在pluginManagement中是不会被引入的。project下的直接子元素plugins中定义的才是这个项目中真正需要被引入的插件。
它的目的在于统一所有子 POM 的插件版本。
1 | <!--------------------- 插件管理 ---------------------> |
- executions :需要记住的是,插件可能有多个目标。每个目标可能有一个单独的配置,甚至可能将插件的目标完全绑定到不同的阶段。执行配置插件的目标的执行。
- id: 执行目标的标识。
- goals: 像所有多元化的 POM 元素一样,它包含单个元素的列表。在这种情况下,这个执行块指定的插件目标列表。
- phase: 这是执行目标列表的阶段。这是一个非常强大的选项,允许将任何目标绑定到构建生命周期中的任何阶段,从而改变 maven 的默认行为。
- inherited: 像上面的继承元素一样,设置这个 false 会阻止 maven 将这个执行传递给它的子代。此元素仅对父 POM 有意义。
- configuration: 与上述相同,但将配置限制在此特定目标列表中,而不是插件下的所有目标。
4、构建扩展
扩展是在此构建中使用的 artifacts 的列表。它们将被包含在运行构建的 classpath 中。它们可以启用对构建过程的扩展(例如为 Wagon 传输机制添加一个 ftp 提供程序),并使活动的插件能够对构建生命周期进行更改。简而言之,扩展是在构建期间激活的 artifacts。扩展不需要实际执行任何操作,也不包含 Mojo。因此,扩展对于指定普通插件接口的多个实现中的一个是非常好的。
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
5、其他配置
build 可以分为 “project build” 和 “profile build”。
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
基本构建配置:
1 | <build> |
defaultGoal : 默认执行目标或阶段。如果给出了一个目标,它应该被定义为它在命令行中(如 jar:jar)。如果定义了一个阶段(如安装),也是如此。
directory :构建时的输出路径。默认为:${basedir}/target 。
finalName :这是项目的最终构建名称(不包括文件扩展名,例如:my-project-1.0.jar)
filter :定义 * .properties 文件,其中包含适用于接受其设置的资源的属性列表(如下所述)。换句话说,过滤器文件中定义的“name = value”对在代码中替换$ {name}字符串。
6、reporting——报表规范
报告包含特定针对 site 生成阶段的元素。某些 maven 插件可以生成 reporting 元素下配置的报告,例如:生成 javadoc 报告。reporting 与 build 元素配置插件的能力相似。明显的区别在于:在执行块中插件目标的控制不是细粒度的,报表通过配置 reportSet 元素来精细控制。而微妙的区别在于 reporting 元素下的 configuration 元素可以用作 build 下的 configuration ,尽管相反的情况并非如此( build 下的 configuration 不影响 reporting 元素下的 configuration )。
另一个区别就是 plugin 下的 outputDirectory 元素。在报告的情况下,默认输出目录为 ${basedir}/target/site。
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
项目信息
项目信息相关的这部分标签都不是必要的,也就是说完全可以不填写。
它的作用仅限于描述项目的详细信息。
下面的示例是项目信息相关标签的清单:
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
这部分标签都非常简单,基本都能做到顾名思义,且都属于可有可无的标签,所以这里仅简单介绍一下:
- name - 项目完整名称
- description - 项目描述
- url - 一般为项目仓库的 host
- inceptionYear - 开发年份
- licenses - 开源协议
- organization - 项目所属组织信息
- developers - 项目开发者列表
- contributors - 项目贡献者列表,
<contributor>的子标签和<developer>的完全相同。
备注:maven可以通过mvn site命令生成项目的相关文档。
环境配置
1、issueManagement——描述性信息
这定义了所使用的缺陷跟踪系统(Bugzilla,TestTrack,ClearQuest 等)。虽然没有什么可以阻止插件使用这些信息的东西,但它主要用于生成项目文档。
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
2、ciManagement——持续集成配置
CI 构建系统配置,主要是指定通知机制以及被通知的邮箱。
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
3、mailingLists——邮件列表
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
4、scm——软件配置管理
SCM(软件配置管理,也称为源代码/控制管理或简洁的版本控制)。常见的 scm 有 svn 和 git 。
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
5、prerequisites——前提条件
POM 执行的预设条件。
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
6、repositories——远程仓库列表
repositories 是遵循 Maven 存储库目录布局的 artifacts 集合。默认的 Maven 中央存储库位于https://repo.maven.apache.org/maven2/上。
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
7、pluginRepositories——远程仓库列表
与 repositories 差不多。
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
8、distributionManagement——项目分发信息相关元素
它管理在整个构建过程中生成的 artifact 和支持文件的分布。从最后的元素开始:
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
项目分发信息的相关配置,在distributionManagement中设置。设置的内容包括:
- repository和snapshotRepository:项目产生的构建/快照构建部署的远程仓库。如果不配置snapshotRepository,快照也会部署到repository中;
- site:部署项目的网站需要的信息;
- downloadUrl:项目下载页面的URL,这是为不在仓库中的构建提供的;
- relocation:如果构件有了新的group ID和artifact ID(移到了新的位置),这里列出构件的新的信息;
- status:给出该构件在远程仓库的状态,本地项目中不能设置该元素,这是工具自动更新的。
9、profiles
activation 是一个 profile 的关键。配置文件的功能来自于在某些情况下仅修改基本 POM 的功能。这些情况通过 activation 元素指定。
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" |
Maven 常用 POM 属性
${project.build.sourceDirectory}:项目的主源码目录,默认为src/main/java/${project.build.testSourceDirectory}:项目的测试源码目录,默认为/src/test/java/${project.build.directory}:项目构建输出目录,默认为target/${project.build.outputDirectory}:项目主代码编译输出目录,默认为target/classes/${project.build.testOutputDirectory}:项目测试代码编译输出目录,默认为target/testclasses/${project.groupId}:项目的 groupId.${project.artifactId}:项目的 artifactId.${project.version}:项目的 version,于${version}等价${project.build.finalName}:项目打包输出文件的名称,默认为${project.artifactId}${project.version}
java-maven学习(四)——生命周期和常用插件
maven生命周期
Maven有三套相互独立的生命周期,请注意这里说的是“三套”,而且“相互独立”。
每个生命周期由一系列阶段组成;默认的构建生命周期包括 23 个阶段,这些是主要的构建生命周期。另一方面,clean 生命周期由 3 个阶段组成,而 site 生命周期由4个阶段组成。
这三套生命周期分别如下所示。
Clean Lifecycle
在进行真正的构建之前进行一些清理工作。清理上一次 build 产生的所有的文件(target/)
Clean生命周期一共包含了三个阶段:
- pre-clean 执行一些需要在clean之前完成的工作
- clean 移除所有上一次构建生成的文件
- post-clean 执行一些需要在clean之后立刻完成的工作
Default Lifecycle
负责项目部署的主要生命周期,构建的核心部分,编译,测试,打包,部署等等。
Maven 阶段表示 Maven 构建生命周期中的各个阶段,每个阶段负责一个特定的任务,默认的包括以下这些黑体标粗阶段。
validate:检查构建所需的所有信息是否都可用
generate-sources
process-sources
generate-resources
process-resources 复制并处理资源文件,至目标目录,准备打包
compile:编译项目的源代码
process-classes
generate-test-sources
process-test-sources
generate-test-resources
process-test-resources 复制并处理资源文件,至目标测试目录
test-compile:编译测试源代码
process-test-classes
test:使用合适的单元测试框架运行测试。这些测试代码不会被打包或部署
prepare-package
package:接受编译好的代码,打包成可发布的格式,如 JAR
pre-integration-test
integration-test:集成测试
post-integration-test
verify
install:将包安装至本地仓库,以让其它项目依赖。
deploy:将最终的包复制到远程的仓库,以让其它开发人员与项目共享
那我们在Hello的项目中执行 mvn install 命令,通过日志看看中间经历了什么?

通过日志我们发现,其实执行mvn install,其中已经执行了compile 和 test 。
maven 中的阶段是有先后顺序只分的,当运行靠后的阶段时,前面的也会执行,但是也可以通过一些参数来跳过一些操作,最常见的就是 skipTests 。
总结:不论你要执行生命周期的哪一个阶段,maven都是从这个生命周期的开始执行
插件:每个阶段都有插件(plugin),看上面标红的。插件的职责就是执行它对应的命令。
Site Lifecycle
生成项目报告,站点,发布站点。
- pre-site 执行一些需要在生成站点文档之前完成的工作
- site 生成项目的站点文档
- post-site 执行一些需要在生成站点文档之后完成的工作,并且为部署做准备
- site-deploy 将生成的站点文档部署到特定的服务器上
maven goal
生命周期中会有阶段,阶段中会有一些列目标,每个目标负责一个特定的任务;当我们运行一个阶段时,默认会绑定到这个阶段的所有目标都按顺序执行。下面以 compile 为例:
以下是一些与之相关的阶段和默认目标:
- compile:compile -> 编译器插件的编译目标绑定到编译阶段
- compile:testCompile -> 被绑定到测试编译阶段
怎么去看特定阶段的目标和他的插件信息呢?mvn help:describe -Dcmd=PHASENAME,比如:
1 | mvn help:describe -Dcmd=compile |
Maven 常用插件
插件是Maven的核心功能,它允许在多个项目中重用通用的构建逻辑。插件可用于:
- 创建jar文件,
- 创建war文件,
- 编译代码,
- 单元测试代码,
- 创建项目文档等。
常用的插件有:
- maven-antrun-plugin,让用户在 Maven 项目中运行 Ant 任务。用户可以直接在该插件的配置以 Ant 的方式编写 Target,然后交给该插件的 run 目标去执行。在一些由 Ant 往 Maven 迁移的项目中,该插件尤其有用。此外当你发现需要编写一些自定义程度很高的任务,同时又觉得 Maven 不够灵活时,也可以以 Ant 的方式实现之。maven-antrun-plugin 的 run 目标通常与生命周期绑定运行。
- maven-assembly-plugin,制作项目分发包,该分发包可能包含了项目的可执行文件、源代码、readme、平台脚本等等。maven-assembly-plugin 支持各种主流的格式如 zip、tar.gz、jar 和 war 等,具体打包哪些文件是高度可控的,例如用户可以按文件级别的粒度、文件集级别的粒度、模块级别的粒度、以及依赖级别的粒度控制打包,此外,包含和排除配置也是支持的。maven-assembly-plugin 要求用户使用一个名为assembly.xml的元数据文件来表述打包,它的 single 目标可以直接在命令行调用,也可以被绑定至生命周期。
- maven-help-plugin,一个小巧的辅助工具,最简单的help:system可以打印所有可用的环境变量和 Java 系统属性。help:effective-pom和help:effective-settings最为有用,它们分别打印项目的有效 POM 和有效 settings,有效 POM 是指合并了所有父 POM(包括 Super POM)后的 XML,当你不确定 POM 的某些信息从何而来时,就可以查看有效 POM。
- maven-javadoc-plugin,javadoc 插件,将源码的 javadoc 发布出去。
编写一个插件
编写一个插件大体可以分为以下几步:
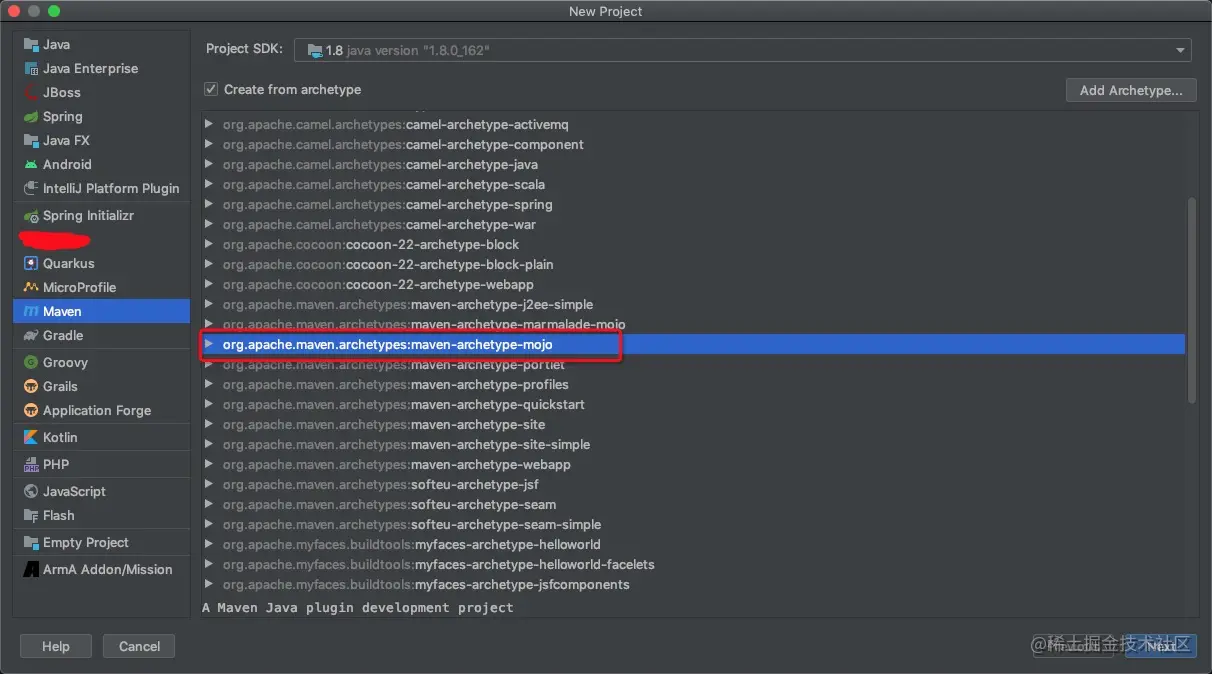
step1:新建一个 maven-archetype-mojo
step2:添加一个 mojo 类
1 |
|
step3:pom.xml 处理
pom 里面,首先是 packaging 不是 pom 也不是 jar,而是
1 | <packaging>maven-plugin</packaging> |
引入一些必要的依赖:
1 | <dependency> |
引入打包插件的 plugin
1 | <build> |
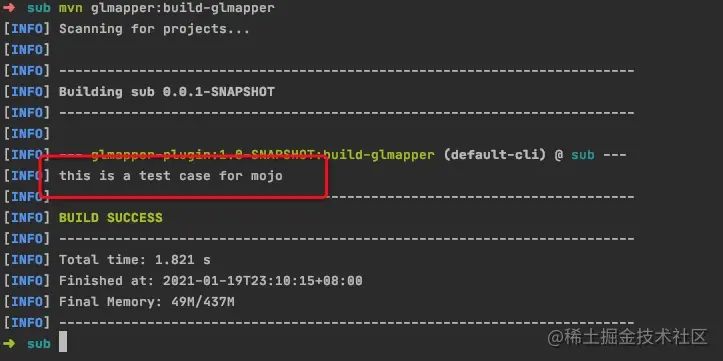
step4:install 你的插件 & 测试插件允许
引入的工程中通过 maven plugin 菜单也能看到:

这里有个小细节,就是执行插件的阶段,比如我们的插件名字是 glmapper-plugin,但是实际上执行时使用的是 glmapper,也就是当插件名满足:xxx-maven-plugin 或maven-xxx-plugin命名规则时,可以直接使用 xxx,即可。
Archetype
基本每个公司的项目都有一套模板,只要开新项目直接复制一份改改包名和一些配置就初始化了一个新项目。这种方式有点繁琐,有没有通过命令甚至是可视化的方式从一个模板项目初始化项目。Maven其实有提供这种能力,这就是基于原型(Archetype)的生成项目。
集成项目模板插件
首先需要在模板项目中集成Maven原型插件:
1 | <plugin> |
从项目生成模板
从项目生成模板只需要三步。
生成模板原型文件
Maven插件允许我们从已有项目生成一个模板项目。在项目根目录下执行mvn archetype:create-from-project命令即可将该项目生成一个项目模板,生成的项目原型被保存在路径target/generated-sources/archetype下。
但是这个存在一个问题,一些和项目模板源码无关的文件也会被加入模板中,比如IDEA中的.iml文件、.idea目录下的文件。这些“垃圾”文件需要在生成模板时被忽略。
maven-archetype-plugin提供了一个属性配置可以帮助我们实现该能力。在原始项目的根目录(或者你喜欢的其它目录)编写一个.properties文件:
1 | # 原型的坐标 必须声明 |
这时候执行生成的命令就需要指定该配置文件了:
1 | mvn archetype:create-from-project -Darchetype.properties=./archetype.properties |
注意:路径为配置文件和根目录的相对路径。
这样生成的原型就忽略掉那些无用的文件了。细心的同学会发现生成原型中的pom.xml的坐标变成了:
1 | <groupId>cn.felord</groupId> |