东西比较多,做个笔记。方便日后查阅学习。
java 锁机制
Java中常用的锁机制
java多线程—锁机制
在开发Java多线程应用程序中,各个线程之间由于要共享资源,必须用到锁机制。Java提供了多种多线程锁机制的实现方式,常见的有synchronized、ReentrantLock、Semaphore、AtomicInteger等。每种机制都有优缺点与各自的适用场景,必须熟练掌握他们的特点才能在Java多线程应用开发时得心应手。
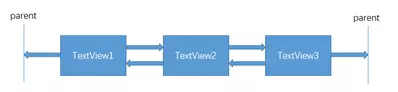
线程同步有关的类图关系可用以下的图总结:
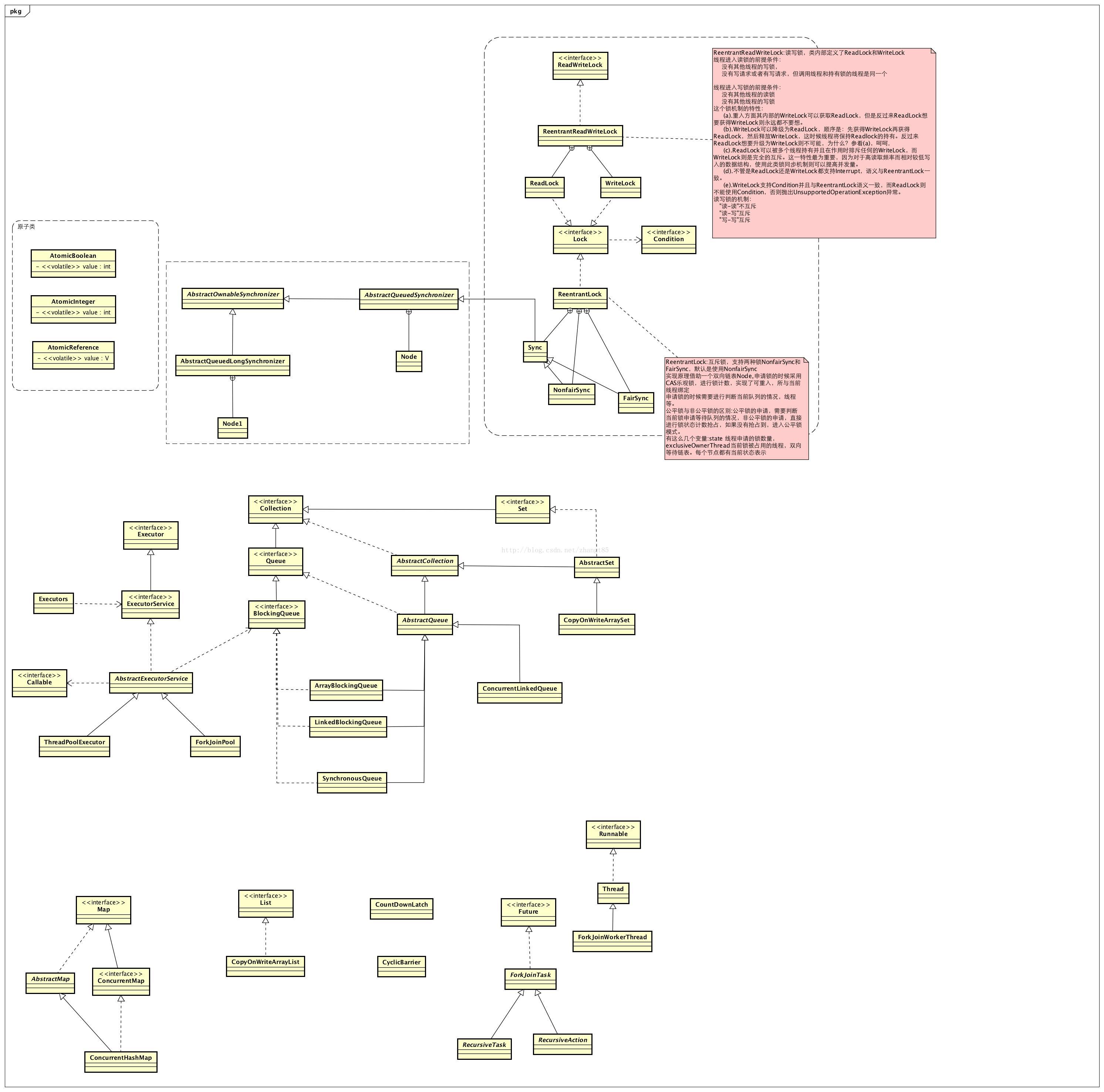
锁的介绍
什么是锁
在计算机科学中,锁(lock)或互斥(mutex)是一种同步机制,用于在有许多执行线程的环境中强制对资源的访问限制。锁旨在强制实施互斥排他、并发控制策略。
锁通常需要硬件支持才能有效实施。这种支持通常采取一个或多个原子指令的形式,如”test-and-set”, “fetch-and-add” or “compare-and-swap””。这些指令允许单个进程测试锁是否空闲,如果空闲,则通过单个原子操作获取锁。
通俗的理解是,锁是为了解决多个线程公用一种临界资源而产生冲突的。跟上厕所一样,假如有ABC三个人都来上厕所而厕所只有一个一次只能进一人,A先来了,那么在A出来之前,这个厕所就处在了“锁”定状态,B和C憋死也要在外面等着,直到A出门(原因很多,如睡着了,方便完了,忘带厕纸了跑出来找人要….)“锁”定解除B和C才能进入,当然牛逼的进(A和B有一腿只让B进或者优先级高或者…),其他的在外面继续等。
锁的属性—粒度
在引入锁粒度之前,需要了解关于锁的三个概念:
1、锁开销 lock overhead 锁占用内存空间、 cpu初始化和销毁锁、获取和释放锁的时间。程序使用的锁越多,相应的锁开销越大
2、锁竞争 lock contention 一个进程或线程试图获取另一个进程或线程持有的锁,就会发生锁竞争。锁粒度越小,发生锁竞争的可能性就越小
3、死锁 deadlock 至少两个任务中的每一个都等待另一个任务持有的锁的情况锁粒度是衡量锁保护的数据量大小,通常选择粗粒度的锁(锁的数量少,每个锁保护大量的数据),在当单进程访问受保护的数据时锁开销小,但是当多个进程同时访问时性能很差。因为增大了锁的竞争。相反,使用细粒度的锁(锁数量多,每个锁保护少量的数据)增加了锁的开销但是减少了锁竞争。例如数据库中,锁的粒度有表锁、页锁、行锁、字段锁、字段的一部分锁
相关术语 Critical Section(临界区)、 Mutex/mutual exclusion(互斥体)、 Semaphore/binary semaphore(信号量)
注:
锁的粒度通常就是锁的级别。详细见:https://blog.csdn.net/qq_25408423/article/details/84340432
Java锁的种类
公平锁/非公平锁
可重入锁
独享锁/共享锁
互斥锁/读写锁
乐观锁/悲观锁
分段锁
偏向锁/轻量级锁/重量级锁
自旋锁
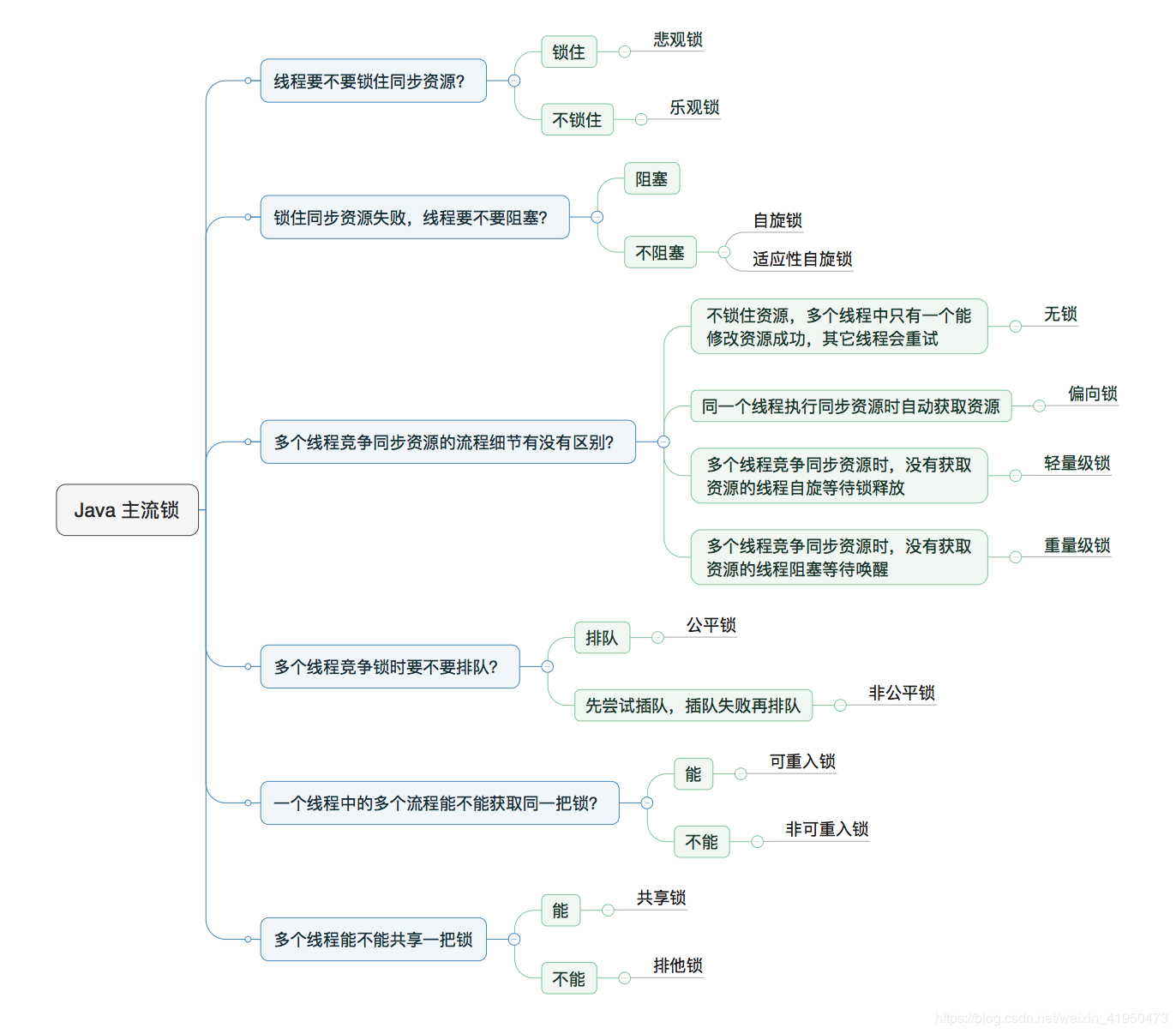
上面是很多锁的名词,这些分类并不是全是指锁的状态,有的指锁的特性,有的指锁的设计,下面总结的内容是对每个锁的名词进行一定的解释。
1.公平锁/非公平锁
公平锁是指多个线程按照申请锁的顺序来获取锁,线程直接进入队列中排队,队列中的第一个线程才能获得锁。公平锁的优点是等待锁的线程不会饿死。缺点是整体吞吐效率相对非公平锁要低,等待队列中除第一个线程以外的所有线程都会阻塞,CPU唤醒阻塞线程的开销比非公平锁大。
非公平锁是多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待。但如果此时锁刚好可用,那么这个线程可以无需阻塞直接获取到锁,所以非公平锁有可能出现后申请锁的线程先获取锁的场景。非公平锁的优点是可以减少唤起线程的开销,整体的吞吐效率高,因为线程有几率不阻塞直接获得锁,CPU不必唤醒所有线程。缺点是处于等待队列中的线程可能会饿死,或者等很久才会获得锁。对于Java ReentrantLock而言,通过构造函数指定该锁是否是公平锁,默认是非公平锁。
非公平锁的优点在于吞吐量比公平锁大。
例子:
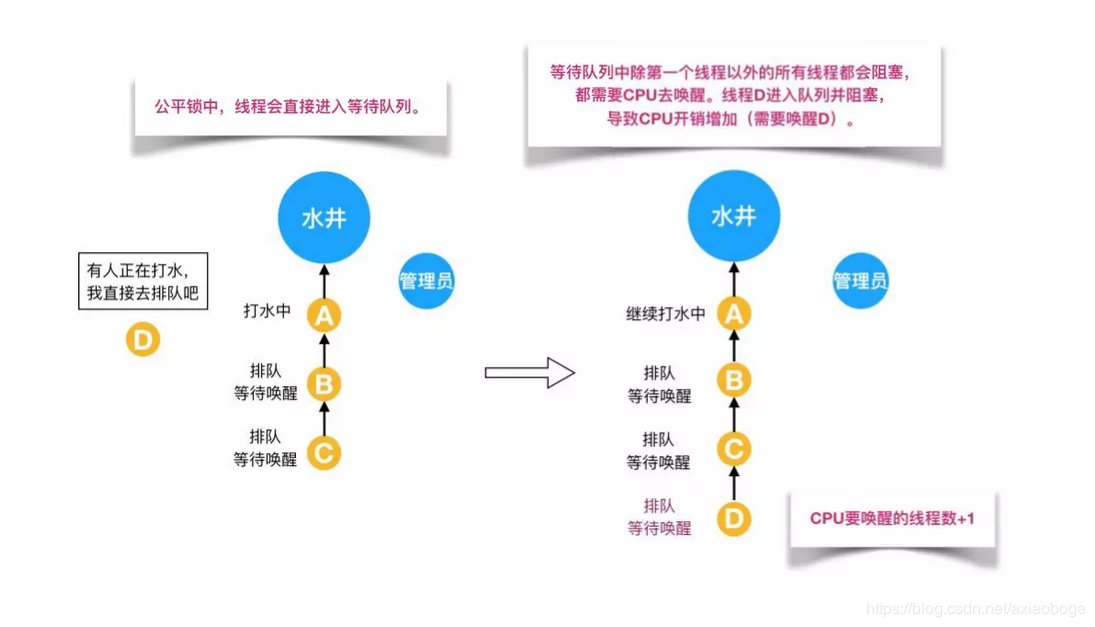
如上图所示,假设有一口水井,有管理员看守,管理员有一把锁,只有拿到锁的人才能够打水,打完水要把锁还给管理员。每个过来打水的人都要管理员的允许并拿到锁之后才能去打水,如果前面有人正在打水,那么这个想要打水的人就必须排队。管理员会查看下一个要去打水的人是不是队伍里排最前面的人,如果是的话,才会给你锁让你去打水;如果你不是排第一的人,就必须去队尾排队,这就是公平锁。
但是对于非公平锁,管理员对打水的人没有要求。即使等待队伍里有排队等待的人,但如果在上一个人刚打完水把锁还给管理员而且管理员还没有允许等待队伍里下一个人去打水时,刚好来了一个插队的人,这个插队的人是可以直接从管理员那里拿到锁去打水,不需要排队,原本排队等待的人只能继续等待。如下图所示:
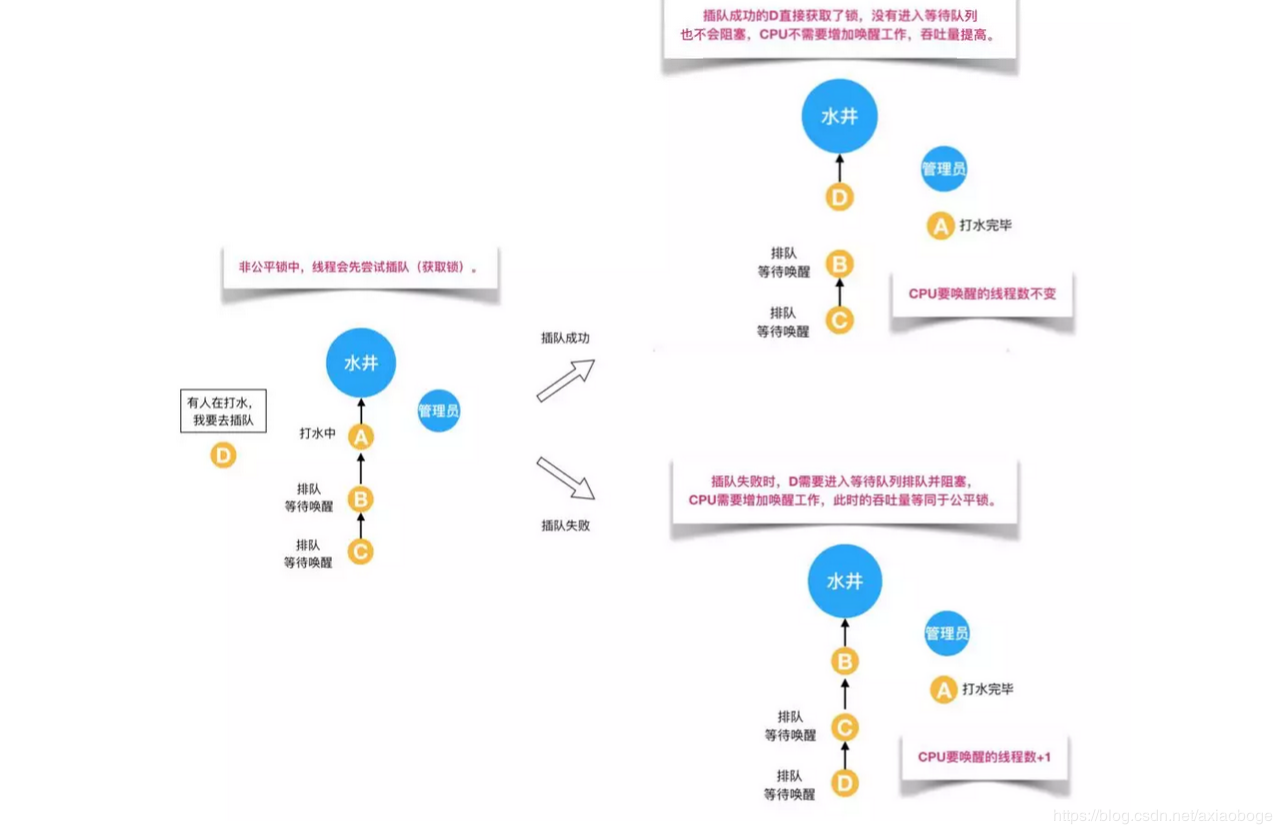
对于synchronized而言,也是一种非公平锁。由于其并不像ReentrantLock是通过AQS的来实现线程调度,所以并没有任何办法使其变成公平锁。
接下来我们通过ReentrantLock的源码来讲解公平锁和非公平锁。
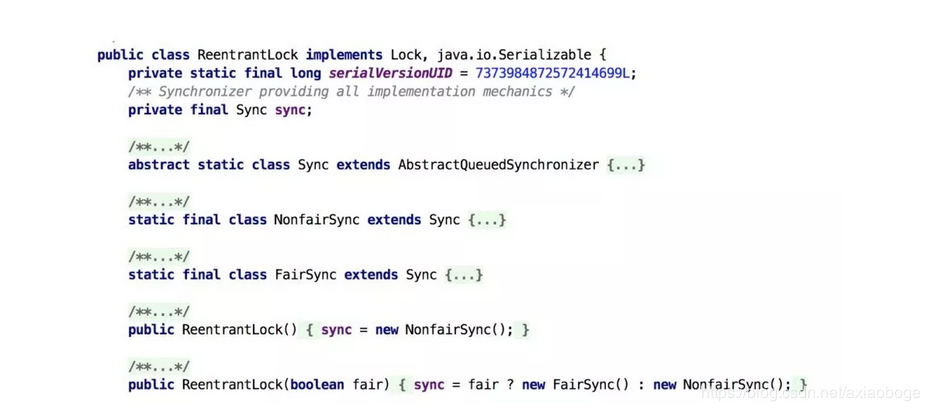
根据代码可知,ReentrantLock里面有一个内部类Sync,Sync继承AQS(AbstractQueuedSynchronizer),添加锁和释放锁的大部分操作实际上都是在Sync中实现的。它有公平锁FairSync和非公平锁NonfairSync两个子类。ReentrantLock默认使用非公平锁,也可以通过构造器来显示的指定使用公平锁。
下面我们来看一下公平锁与非公平锁的加锁方法的源码:

通过上图中的源代码对比,我们可以明显的看出公平锁与非公平锁的lock()方法唯一的区别就在于公平锁在获取同步状态时多了一个限制条件:hasQueuedPredecessors()。

再进入hasQueuedPredecessors(),可以看到该方法主要做一件事情:主要是判断当前线程是否位于同步队列中的第一个。如果是则返回true,否则返回false。
综上,公平锁就是通过同步队列来实现多个线程按照申请锁的顺序来获取锁,从而实现公平的特性。非公平锁加锁时不考虑排队等待问题,直接尝试获取锁,所以存在后申请却先获得锁的情况。
2.独享锁/共享锁
独享锁和共享锁同样是一种概念。我们先介绍一下具体的概念,然后通过ReentrantLock和ReentrantReadWriteLock的源码来介绍独享锁和共享锁。
独享锁也叫排他锁,是指该锁一次只能被一个线程所持有。如果线程T对数据A加上排它锁后,则其他线程不能再对A加任何类型的锁。获得排它锁的线程即能读数据又能修改数据。JDK中的synchronized和JUC中Lock的实现类就是互斥锁。
共享锁是指该锁可被多个线程所持有。如果线程T对数据A加上共享锁后,则其他线程只能对A再加共享锁,不能加排它锁。获得共享锁的线程只能读数据,不能修改数据。
独享锁与共享锁也是通过AQS来实现的,通过实现不同的方法,来实现独享或者共享。
下图为ReentrantReadWriteLock的部分源码:

我们看到ReentrantReadWriteLock有两把锁:ReadLock和WriteLock,由词知意,一个读锁一个写锁,合称“读写锁”。再进一步观察可以发现ReadLock和WriteLock是靠内部类Sync实现的锁。Sync是AQS的一个子类,这种结构在CountDownLatch、ReentrantLock、Semaphore里面也都存在。
在ReentrantReadWriteLock里面,读锁和写锁的锁主体都是Sync,但读锁和写锁的加锁方式不一样。读锁是共享锁,写锁是独享锁。读锁的共享锁可保证并发读非常高效,而读写、写读、写写的过程互斥,因为读锁和写锁是分离的。所以ReentrantReadWriteLock的并发性相比一般的互斥锁有了很大提升。
那读锁和写锁的具体加锁方式有什么区别呢?在了解源码之前我们需要回顾一下其他知识。
在最开始提及AQS的时候我们也提到了state字段(int类型,32位),该字段用来描述有多少线程获持有锁。
在独享锁中这个值通常是0或者1(如果是重入锁的话state值就是重入的次数),在共享锁中state就是持有锁的数量。但是在ReentrantReadWriteLock中有读、写两把锁,所以需要在一个整型变量state上分别描述读锁和写锁的数量(或者也可以叫状态)。于是将state变量“按位切割”切分成了两个部分,高16位表示读锁状态(读锁个数),低16位表示写锁状态(写锁个数)。如下图所示:

了解了概念之后我们再来看代码,先看写锁的加锁源码:

- 这段代码首先取到当前锁的个数c,然后再通过c来获取写锁的个数w。因为写锁是低16位,所以取低16位的最大值与当前的c做与运算( int w = exclusiveCount(c); ),高16位和0与运算后是0,剩下的就是低位运算的值,同时也是持有写锁的线程数目。
- 在取到写锁线程的数目后,首先判断是否已经有线程持有了锁。如果已经有线程持有了锁(c!=0),则查看当前写锁线程的数目,如果写线程数为0(即此时存在读锁)或者持有锁的线程不是当前线程就返回失败(涉及到公平锁和非公平锁的实现)。
- 如果写入锁的数量大于最大数(65535,2的16次方-1)就抛出一个Error。
- 如果当且写线程数为0(那么读线程也应该为0,因为上面已经处理c!=0的情况),并且当前线程需要阻塞那么就返回失败;如果通过CAS增加写线程数失败也返回失败。
- 如果c=0,w=0或者c>0,w>0(重入),则设置当前线程或锁的拥有者,返回成功!
tryAcquire()除了重入条件(当前线程为获取了写锁的线程)之外,增加了一个读锁是否存在的判断。如果存在读锁,则写锁不能被获取,原因在于:必须确保写锁的操作对读锁可见,如果允许读锁在已被获取的情况下对写锁的获取,那么正在运行的其他读线程就无法感知到当前写线程的操作。
因此,只有等待其他读线程都释放了读锁,写锁才能被当前线程获取,而写锁一旦被获取,则其他读写线程的后续访问均被阻塞。写锁的释放与ReentrantLock的释放过程基本类似,每次释放均减少写状态,当写状态为0时表示写锁已被释放,然后等待的读写线程才能够继续访问读写锁,同时前次写线程的修改对后续的读写线程可见。
接着是读锁的代码:

可以看到在tryAcquireShared(int unused)方法中,如果其他线程已经获取了写锁,则当前线程获取读锁失败,进入等待状态。如果当前线程获取了写锁或者写锁未被获取,则当前线程(线程安全,依靠CAS保证)增加读状态,成功获取读锁。读锁的每次释放(线程安全的,可能有多个读线程同时释放读锁)均减少读状态,减少的值是“1<<16”。所以读写锁才能实现读读的过程共享,而读写、写读、写写的过程互斥。
此时,我们再回头看一下互斥锁ReentrantLock中公平锁和非公平锁的加锁源码:

我们发现在ReentrantLock虽然有公平锁和非公平锁两种,但是它们添加的都是独享锁。根据源码所示,当某一个线程调用lock方法获取锁时,如果同步资源没有被其他线程锁住,那么当前线程在使用CAS更新state成功后就会成功抢占该资源。而如果公共资源被占用且不是被当前线程占用,那么就会加锁失败。所以可以确定ReentrantLock无论读操作还是写操作,添加的锁都是都是独享锁。
对于Java ReentrantLock而言,其是独享锁。但是对于Lock的另一个实现类ReadWriteLock,其读锁是共享锁,其写锁是独享锁。读锁的共享锁可保证并发读是非常高效的,读写、写读 、写写的过程是互斥的。独享锁与共享锁也是通过AQS来实现的,通过实现不同的方法,来实现独享或者共享。对于synchronized而言,当然是独享锁。
3.互斥锁/读写锁
上面说到的独享锁/共享锁就是一种广义的说法,互斥锁/读写锁就是具体的实现。互斥锁在Java中的具体实现就是ReentrantLock(可重入锁);读写锁在Java中的具体实现就是ReadWriteLock。独享锁与共享锁也是通过AQS来实现的。
在多线程的环境下,对同一份数据进行读写,会涉及到线程安全的问题。比如在一个线程读取数据的时候,另外一个线程在写数据,而导致前后数据的不一致性;一个线程在写数据的时候,另一个线程也在写,同样也会导致线程前后看到的数据的不一致性。 这时候可以在读写方法中加入互斥锁,任何时候只能允许一个线程的一个读或写操作,而不允许其他线程的读或写操作,这样是可以解决这样以上的问题,但是效率却大打折扣了。因为在真实的业务场景中,一份数据,读取数据的操作次数通常高于写入数据的操作,而线程与线程间的读读操作是不涉及到线程安全的问题,没有必要加入互斥锁,只要在读-写,写-写期间上锁就行了。对于这种情况,读写锁则最好的解决方案!
读写锁的机制:
“读-读”不互斥
“读-写”互斥
“写-写”互斥
即在任何时候必须保证:
- 只有一个线程在写入;
- 线程正在读取的时候,写入操作等待;
- 线程正在写入的时候,其他线程的写入操作和读取操作都要等待;
示例:
1 | public class CachedData { |
4.乐观锁/悲观锁
乐观锁与悲观锁不是指具体的什么类型的锁,而是指看待并发同步的角度。
悲观锁:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁。比如Java里面的同步原语synchronized关键字的实现就是悲观锁。
乐观锁:顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS(Compare and Swap 比较并交换)实现的。
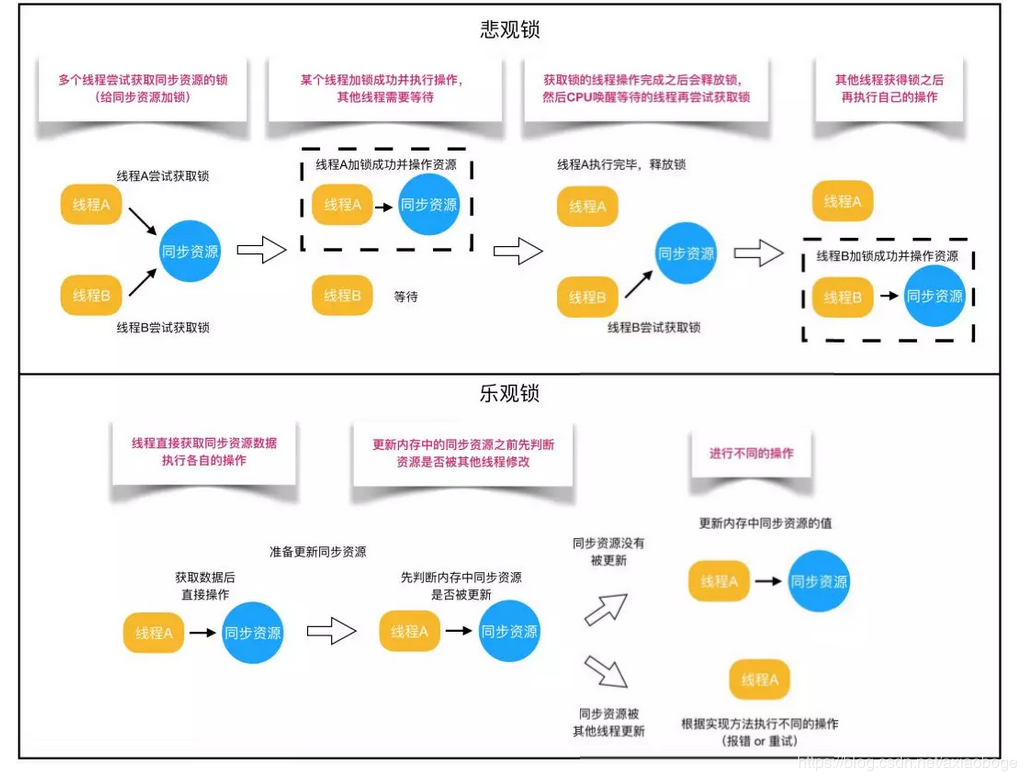
根据从上面的概念描述我们可以发现:
悲观锁适合写操作多的场景,先加锁可以保证写操作时数据正确。
乐观锁适合读操作多的场景,不加锁的特点能够使其读操作的性能大幅提升。
乐观锁和悲观锁的调用方式示例:

通过调用方式示例,我们可以发现悲观锁基本都是在显式的锁定之后再操作同步资源,而乐观锁则直接去操作同步资源。那么,为何乐观锁能够做到不锁定同步资源也可以正确的实现线程同步呢?我们通过介绍乐观锁的主要实现方式 “CAS” 的技术原理来为大家解惑。
乐观锁的一种实现:CAS
CAS全称 Compare And Swap(比较与交换),是一种无锁算法。在不使用锁(没有线程被阻塞)的情况下实现多线程之间的变量同步。java.util.concurrent包中的原子类就是通过CAS来实现了乐观锁。
CAS算法涉及到三个操作数:
- 需要读写的内存值 V。
- 进行比较的值 A。
- 要写入的新值 B。
当且仅当 V 的值等于 A 时,CAS通过原子方式用新值B来更新V的值(“比较+更新”整体是一个原子操作),否则不会执行任何操作。一般情况下,“更新”是一个不断重试的操作。
注:
【原子性:即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
“原子操作(atomic operation)是不需要synchronized”,所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch;
java中一般事务管理里面用到原子操作。
原子操作可以是一个步骤,也可以是多个操作步骤,但是其顺序不可以被打乱,也不可以被切割而只执行其中的一部分,将整个操作视作一个整体是原子性的核心特征;
使用原子操作的好处:
⑴. 性能角度:它执行多次的所消耗的时间远远小于由于线程所挂起到恢复所消耗的时间,因此无锁的CAS操作在性能上要比同步锁高很多;
⑵. 业务需求:业务本身的需求上,无锁机制本身就可以满足我们绝大多数的需求,并且在性能上也可以大大的进行提升。】
之前提到java.util.concurrent包中的原子类,就是通过CAS来实现了乐观锁,那么我们进入原子类AtomicInteger的源码,看一下AtomicInteger的定义:
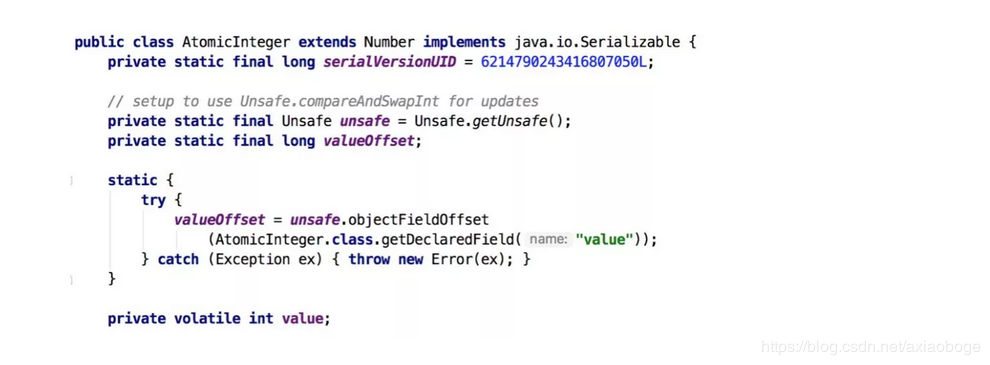
根据定义我们可以看出各属性的作用:
- unsafe: 获取并操作内存的数据。
- valueOffset: 存储value在AtomicInteger中的偏移量。
- value: 存储AtomicInteger的int值,该属性需要借助volatile关键字保证其在线程间是可见的。
接下来,我们查看AtomicInteger的自增函数incrementAndGet()的源码时,发现自增函数底层调用的是unsafe.getAndAddInt()。但是由于JDK本身只有Unsafe.class,只通过class文件中的参数名,并不能很好的了解方法的作用,所以我们通过OpenJDK 8 来查看Unsafe的源码:

根据OpenJDK 8的源码我们可以看出,getAndAddInt()循环获取给定对象o中的偏移量处的值v,然后判断内存值是否等于v。如果相等则将内存值设置为 v + delta,否则返回false,继续循环进行重试,直到设置成功才能退出循环,并且将旧值返回。整个“比较+更新”操作封装在compareAndSwapInt()中,在JNI里是借助于一个CPU指令完成的,属于原子操作,可以保证多个线程都能够看到同一个变量的修改值。
后续JDK通过CPU的cmpxchg指令,去比较寄存器中的 A 和 内存中的值 V。如果相等,就把要写入的新值 B 存入内存中。如果不相等,就将内存值 V 赋值给寄存器中的值 A。然后通过Java代码中的while循环再次调用cmpxchg指令进行重试,直到设置成功为止。
CAS虽然很高效,但是它也存在三大问题,这里也简单说一下:
\1. ABA问题。CAS需要在操作值的时候检查内存值是否发生变化,没有发生变化才会更新内存值。但是如果内存值原来是A,后来变成了B,然后又变成了A,那么CAS进行检查时会发现值没有发生变化,但是实际上是有变化的。ABA问题的解决思路就是在变量前面添加版本号,每次变量更新的时候都把版本号加一,这样变化过程就从“A-B-A”变成了“1A-2B-3A”。
JDK从1.5开始提供了AtomicStampedReference类来解决ABA问题,具体操作封装在compareAndSet()中。compareAndSet()首先检查当前引用和当前标志与预期引用和预期标志是否相等,如果都相等,则以原子方式将引用值和标志的值设置为给定的更新值。
\2. 循环时间长开销大。CAS操作如果长时间不成功,会导致其一直自旋,给CPU带来非常大的开销。
\3. 只能保证一个共享变量的原子操作。对一个共享变量执行操作时,CAS能够保证原子操作,但是对多个共享变量操作时,CAS是无法保证操作的原子性的。
Java从1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,可以把多个变量放在一个对象里来进行CAS操作。
5.分段锁
分段锁其实是一种锁的设计,并不是具体的一种锁,对于ConcurrentHashMap而言,其并发的实现就是通过分段锁的形式来实现高效的并发操作,ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap(JDK7与JDK8中HashMap的实现)的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表;同时又是一个ReentrantLock(Segment继承了ReentrantLock)。当需要put元素的时候,并不是对整个HashMap进行加锁,而是先通过hashcode来知道他要放在那一个分段中,然后对这个分段进行加锁,所以当多线程put的时候,只要不是放在一个分段中,就实现了真正的并行的插入。但是,在统计size的时候,可就是获取HashMap全局信息的时候,就需要获取所有的分段锁才能统计。
分段锁的设计目的是细化锁的粒度,当操作不需要更新整个数组的时候,就仅仅针对数组中的一项进行加锁操作。
6.无锁/偏向锁/轻量级锁/重量级锁(待看)
这四种锁是指锁的状态,并且是针对synchronized。在Java 5通过引入锁升级的机制来实现高效synchronized。这三种锁(偏向锁/轻量级锁/重量级锁)的状态是通过对象监视器在对象头中的字段来表明的。
Synchronized用法
synchronized是实现线程同步的基本手段,然而底层实现还是通过锁机制来保证,对于被synchronized修饰的区域每次只有一个线程可以访问,从而满足线程安全的目的。
synchronized通过锁机制的实现,满足了原子性,可见性和有序性,是并发编程正确执行的有效保障,而volatile只保证了可见性和有序性(禁止指令重排)。
synchronized可以修饰范围的包括:方法级别,代码块级别;而实际加锁的目标包括:对象锁(普通变量,静态变量),类锁。
下面是synchronized的几种常用方法:
1 | public class SynMethod { |
测试情况1
1 | public class SynTest { |
运行结果:
1 | A synchronized loop 0 |
两个线程运行了同一个对象t1的同一个public方法method1。
测试情况2
1 | public class SynTest { |
运行结果:
1 | A synchronized loop 0 |
两个线程运行同一个对象t1的不同的方法method1和method2方法,但是这两个方法是使用同一个对象t1上进行同步的,所以实现同步的效果,侧面印证了这两种写法的一致性。
测试情况3:
1 | public class SynTest { |
运行结果:
1 | A synchronized loop 0 |
两个线程运行了不同的类对象t1和t2的同一个方法method3,这个方法是在一个静态对象上同步,这个静态变量是在这个类的所有实例上共享的,所以也是达到了同步的效果
测试情况4:
1 | public class SynTest { |
运行结果:
1 | A synchronized loop 0 |
两个线程运行了同一个对象t1的method2和method3方法,这个方法分别在t1对象和SynMethod类的静态对象上同步,所以达到同步效果。因为method3方法是针对同一类的,
测试情况5:
1 | public class SynTest { |
运行结果:
1 | A synchronized loop 0 |
两个线程运行了不同对象t1和t2的同一个方法method4,该方法是在SynMethod类上同步,实现了同步效果
测试情况6:
1 | public class SynTest { |
运行结果:
1 | A synchronized loop 0 |
两个线程分别运行了对象t1的method4和静态方法staticMethod,这个两个方法都在SynMethod类上同步,实现了同步的效果。
测试情况7:
1 | public class SynTest { |
运行结果:
1 | A synchronized loop 0 |
这次两个线程运行了两个对象的method3和method4发放,这个两个方法分别在SynMethod类和SynMethod类的静态对象上同步,所以没有达到同步效果
测试情况8:
1 | public class SynTest { |
运行结果:
1 | A synchronized loop 0 |
这次两个线程运行了两个对象的method4和method2方法,这两个方法分别在SynMethod类和对象t2上同步,所以没有达到同步效果。
使用总结:虽然上面说的情况比较多,但是从同步对象的角度,同步的场景只用三个,一个是SynMethod实例(可以多个),SynMethod的静态对象(共享)和SynMethod类(一个),只要是在同一个对象上同步,这个对象可以是实例对象,可以是静态对象,可以是类对象,那么就可以实现同步效果,否则无法达到同步,这也与synchronized设计的初衷一致。
为什么Synchronized能实现线程同步?
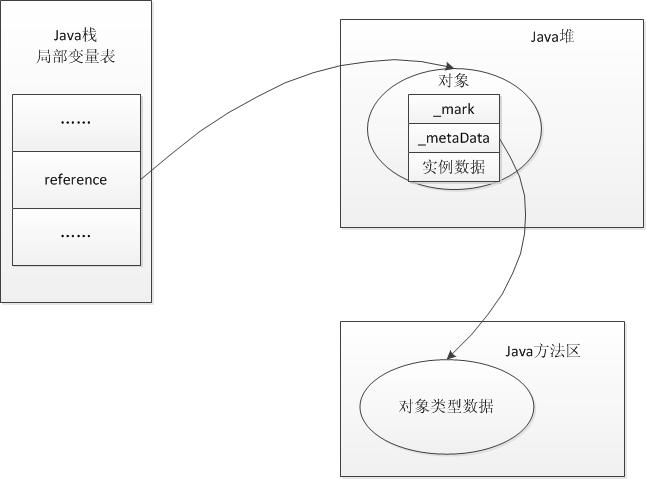
在回答这个问题之前我们需要了解两个重要的概念:“Java对象头”、“Monitor”。
1、Java对象头
synchronized是悲观锁,在操作同步资源之前需要给同步资源先加锁,这把锁就是存在Java对象头里的,而Java对象头又是什么呢?
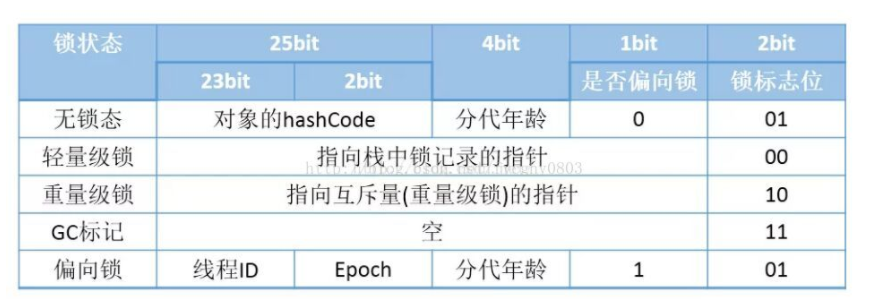
我们以Hotspot虚拟机为例,Hotspot的对象头主要包括两部分数据:Mark Word(标记字段)、Klass Pointer(类型指针)。
Mark Word:默认存储对象的HashCode,分代年龄和锁标志位信息。这些信息都是与对象自身定义无关的数据,所以Mark Word被设计成一个非固定的数据结构以便在极小的空间内存存储尽量多的数据。它会根据对象的状态复用自己的存储空间,也就是说在运行期间Mark Word里存储的数据会随着锁标志位的变化而变化。
Klass Point:对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
运行时JVM内存布局
Mark Word在不同锁状态下的标志位存储
2、Monitor
Monitor可以理解为一个同步工具或一种同步机制,通常被描述为一个对象。每一个Java对象就有一把看不见的锁,称为内部锁或者Monitor锁。
Monitor是线程私有的数据结构,每一个线程都有一个可用monitor record列表,同时还有一个全局的可用列表。每一个被锁住的对象都会和一个monitor关联,同时monitor中有一个Owner字段存放拥有该锁的线程的唯一标识,表示该锁被这个线程占用。
现在话题回到synchronized,synchronized通过Monitor来实现线程同步,Monitor是依赖于底层的操作系统的Mutex Lock(互斥锁)来实现的线程同步。
如同我们在自旋锁中提到的“阻塞或唤醒一个Java线程需要操作系统切换CPU状态来完成,这种状态转换需要耗费处理器时间。如果同步代码块中的内容过于简单,状态转换消耗的时间有可能比用户代码执行的时间还要长”。这种方式就是synchronized最初实现同步的方式,这就是JDK 6之前synchronized效率低的原因。这种依赖于操作系统Mutex Lock所实现的锁我们称之为“重量级锁”,JDK 6中为了减少获得锁和释放锁带来的性能消耗,引入了“偏向锁”和“轻量级锁”。
所以目前锁一共有4种状态,级别从低到高依次是:无锁、偏向锁、轻量级锁和重量级锁。锁状态只能升级不能降级。
通过上面的介绍,我们对synchronized的加锁机制以及相关知识有了一个了解,那么下面我们给出四种锁状态对应的的Mark Word内容,然后再分别讲解四种锁状态的思路以及特点:

无锁
无锁没有对资源进行锁定,所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功。
无锁的特点就是修改操作在循环内进行,线程会不断的尝试修改共享资源。如果没有冲突就修改成功并退出,否则就会继续循环尝试。如果有多个线程修改同一个值,必定会有一个线程能修改成功,而其他修改失败的线程会不断重试直到修改成功。上面我们介绍的CAS原理及应用即是无锁的实现。无锁无法全面代替有锁,但无锁在某些场合下的性能是非常高的。
偏向锁
偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁,降低获取锁的代价。
在大多数情况下,锁总是由同一线程多次获得,不存在多线程竞争,所以出现了偏向锁。其目标就是在只有一个线程执行同步代码块时能够提高性能。
当一个线程访问同步代码块并获取锁时,会在Mark Word里存储锁偏向的线程ID。在线程进入和退出同步块时不再通过CAS操作来加锁和解锁,而是检测Mark Word里是否存储着指向当前线程的偏向锁。引入偏向锁是为了在无多线程竞争的情况下尽量减少不必要的轻量级锁执行路径,因为轻量级锁的获取及释放依赖多次CAS原子指令,而偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令即可。
偏向锁只有遇到其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁,线程不会主动释放偏向锁。偏向锁的撤销,需要等待全局安全点(在这个时间点上没有字节码正在执行),它会首先暂停拥有偏向锁的线程,判断锁对象是否处于被锁定状态。撤销偏向锁后恢复到无锁(标志位为“01”)或轻量级锁(标志位为“00”)的状态。
偏向锁在JDK 6及以后的JVM里是默认启用的。可以通过JVM参数关闭偏向锁:-XX:-UseBiasedLocking=false,关闭之后程序默认会进入轻量级锁状态。
轻量级锁
是指当锁是偏向锁的时候,被另外的线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能。
在代码进入同步块的时候,如果同步对象锁状态为无锁状态(锁标志位为“01”状态,是否为偏向锁为“0”),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝,然后拷贝对象头中的Mark Word复制到锁记录中。
拷贝成功后,虚拟机将使用CAS操作尝试将对象的Mark Word更新为指向Lock Record的指针,并将Lock Record里的owner指针指向对象的Mark Word。
如果这个更新动作成功了,那么这个线程就拥有了该对象的锁,并且对象Mark Word的锁标志位设置为“00”,表示此对象处于轻量级锁定状态。
如果轻量级锁的更新操作失败了,虚拟机首先会检查对象的Mark Word是否指向当前线程的栈帧,如果是就说明当前线程已经拥有了这个对象的锁,那就可以直接进入同步块继续执行,否则说明多个线程竞争锁。
若当前只有一个等待线程,则该线程通过自旋进行等待。但是当自旋超过一定的次数,或者一个线程在持有锁,一个在自旋,又有第三个来访时,轻量级锁升级为重量级锁。
重量级锁
升级为重量级锁时,锁标志的状态值变为“10”,此时Mark Word中存储的是指向重量级锁的指针,此时等待锁的线程都会进入阻塞状态。
整体的锁状态升级流程如下:

综上,偏向锁通过对比Mark Word解决加锁问题,避免执行CAS操作。而轻量级锁是通过用CAS操作和自旋来解决加锁问题,避免线程阻塞和唤醒而影响性能。重量级锁是将除了拥有锁的线程以外的线程都阻塞。
重量级锁是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。重量级锁会让其他申请的线程进入阻塞,性能降低。随着竞争情况锁状态逐渐升级、锁可以升级但不能降级。
偏向锁的获取和撤销:
HotSpot作者经过研究发现,大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入偏向锁。
线程1检查对象头中的Mark Word中是否存储了线程1,如果没有则CAS操作将Mark Word中的线程ID替换为线程1。此时,锁偏向线程1,后面该线程进入同步块时不需要进行CAS操作,只需要简单的测试一下Mark Word中是否存储指向当前线程的偏向锁,如果成功表明该线程已经获得锁。如果失败,则再需要测试一下Mark Word中偏向锁标识是否设置为1(是否是偏向锁),如果没有设置,则使用CAS竞争锁,如果设置了,则尝试使用CAS将偏向锁指向当前线程
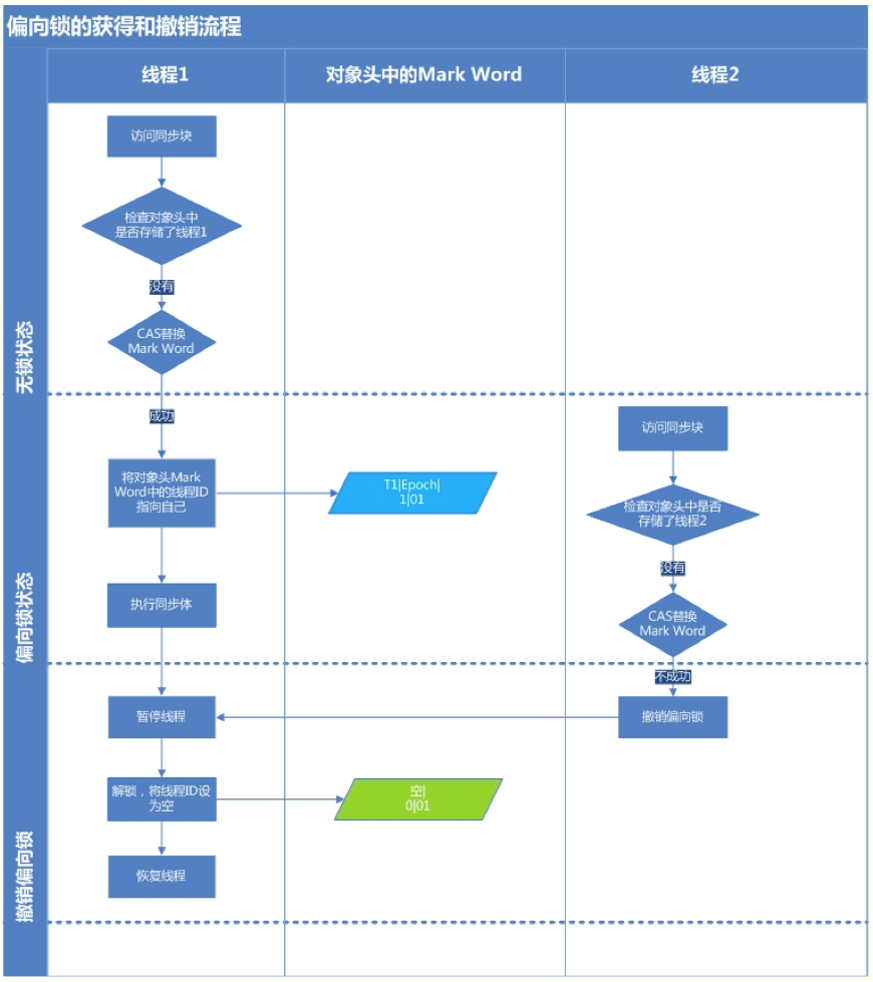
偏向锁的竞争结果:
根据持有偏向锁的线程是否存活
1.如果不活动,偏向锁撤销到无锁状态,再偏向到其他线程
2.如果线程仍然活着,则升级到轻量级锁
偏向锁在Java6和Java7中默认是开启的,但是在应用程序启动几秒后才激活,如果有必要可以关闭延迟:
-XX:BiasedLockingStartupDelay=0
如果确定应用程序中所有的锁通常情况下处于竞争状态,可以通过JVM参数关闭偏向锁:
-XX:-UseBiasedLocking=false,那么程序默认会进入轻量级锁。
-XX:BiasedLockingStartupDelay=0 -XX:+TraceBiasedLocking
轻量级锁膨胀:
1.线程在执行同步块之前,JVM会在当前栈桢中创建用于存储锁记录的空间(Lock record),并将对象头中的Mark Word复制到锁记录中(Displaced Mark Word)。
2.然后线程尝试使用CAS将对象头中的Mark Word替换为指向锁记录的指针
3.如果成功,当前线程获得锁,如果失败,表示其他线程竞争锁,当前线程尝试使用自旋来获取锁
偏向锁、轻量级锁、重量级锁的优缺点
1.偏向锁是为了避免某个线程反复获得/释放同一把锁时的性能消耗,如果仍然是同个线程去获得这个锁,尝试偏向锁时会直接进入同步块,不需要再次获得锁。
2.而轻量级锁和自旋锁都是为了避免直接调用操作系统层面的互斥操作,因为挂起线程是一个很耗资源的操作。
为了尽量避免使用重量级锁(操作系统层面的互斥),首先会尝试轻量级锁,轻量级锁会尝试使用CAS操作来获得锁,如果轻量级锁获得失败,说明存在竞争。但是也许很快就能获得锁,就会尝试自旋锁,将线程做几个空循环,每次循环时都不断尝试获得锁。如果自旋锁也失败,那么只能升级成重量级锁。
3.可见偏向锁,轻量级锁,自旋锁都是乐观锁。
逃逸分析:

逃逸分析:通俗一点讲,当一个对象的指针被多个方法或线程引用时,我们称这个指针发生了逃逸,必须在JIT里完成
锁粗化:
如果虚拟机探测到有这样一串零碎的操作都对同一个对象加锁,将会把加锁同步的范围扩展到整个操作序列的外部,这样就只需要加锁一次就够了
锁消除:
如果你定义的类的方法上有同步锁,但在运行时,却只有一个线程在访问,此时逃逸分析后的机器码,会去掉同步锁运行。
栈上分配:
分析找到未逃逸的变量,将变量类的实例化内存直接在栈里分配(无需进入堆),分配完成后,继续在调用栈内执行,最后线程结束,栈空间被回收,局部变量对象也被回收。
从jdk1.6开始默认开启:
开启: -XX:+DoEscapeAnalysis
关闭: -XX:-DoEscapeAnalysis
7.自旋锁
在Java中,自旋锁是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU。
在介绍自旋锁前,我们需要介绍一些前提知识来帮助大家明白自旋锁的概念。
阻塞或唤醒一个Java线程需要操作系统切换CPU状态来完成,这种状态转换需要耗费处理器时间。如果同步代码块中的内容过于简单,状态转换消耗的时间有可能比用户代码执行的时间还要长。
在许多场景中,同步资源的锁定时间很短,为了这一小段时间去切换线程,线程挂起和恢复现场的花费可能会让系统得不偿失。如果物理机器有多个处理器,能够让两个或以上的线程同时并行执行,我们就可以让后面那个请求锁的线程不放弃CPU的执行时间,看看持有锁的线程是否很快就会释放锁。
而为了让当前线程“稍等一下”,我们需让当前线程进行自旋,如果在自旋完成后前面锁定同步资源的线程已经释放了锁,那么当前线程就可以不必阻塞而是直接获取同步资源,从而避免切换线程的开销。这就是自旋锁。
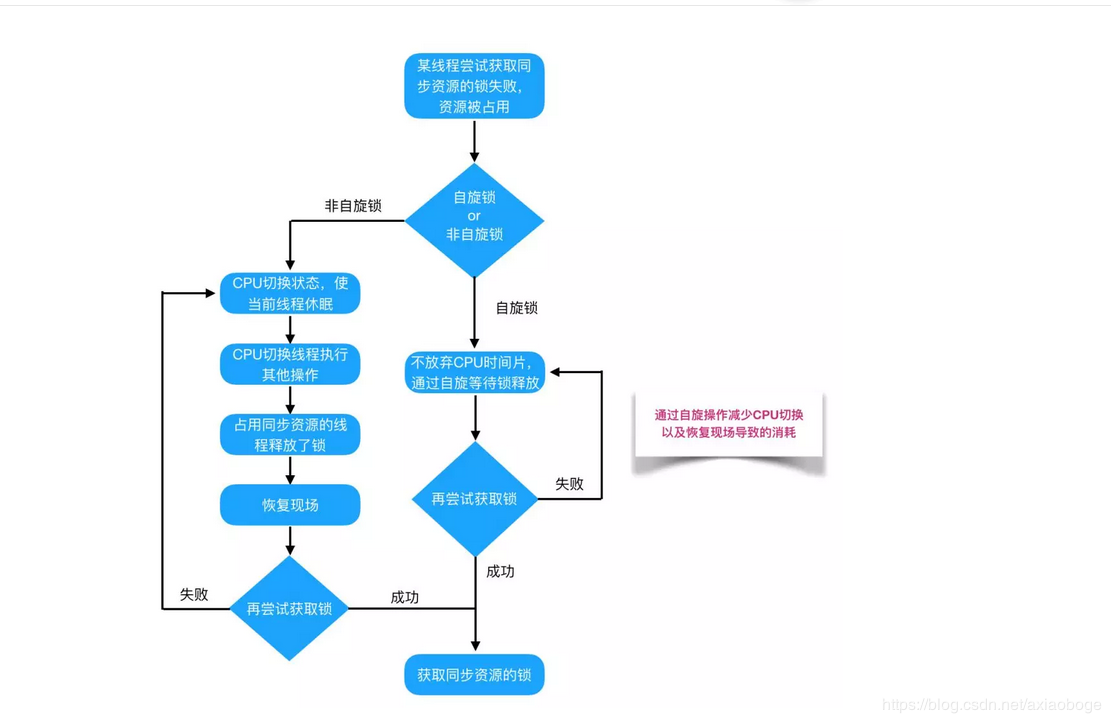
自旋锁本身是有缺点的,它不能代替阻塞。自旋等待虽然避免了线程切换的开销,但它要占用处理器时间。如果锁被占用的时间很短,自旋等待的效果就会非常好。反之,如果锁被占用的时间很长,那么自旋的线程只会白浪费处理器资源。所以,自旋等待的时间必须要有一定的限度,如果自旋超过了限定次数(默认是10次,可以使用-XX:PreBlockSpin来更改)没有成功获得锁,就应当挂起线程。
自旋锁的实现原理同样也是CAS,AtomicInteger中调用unsafe进行自增操作的源码中的do-while循环就是一个自旋操作,如果修改数值失败则通过循环来执行自旋,直至修改成功。

自旋锁在JDK1.4.2中引入,使用-XX:+UseSpinning来开启。JDK 6中变为默认开启,并且引入了自适应的自旋锁(适应性自旋锁)。
自适应意味着自旋的时间(次数)不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间。如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源。
在自旋锁中 另有三种常见的锁形式:TicketLock、CLHlock和MCSlock。
8.可重入锁/非可重入锁
可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提锁对象得是同一个对象或者class),不会因为之前已经获取过还没释放而阻塞。Java中ReentrantLock和synchronized都是可重入锁,可重入锁的一个优点是可一定程度避免死锁。下面用示例代码来进行分析:

在上面的代码中,类中的两个方法都是被内置锁synchronized修饰的,doSomething()方法中调用doOthers()方法。因为内置锁是可重入的,所以同一个线程在调用doOthers()时可以直接获得当前对象的锁,进入doOthers()进行操作。
如果是一个不可重入锁,那么当前线程在调用doOthers()之前需要将执行doSomething()时获取当前对象的锁释放掉,实际上该对象锁已被当前线程所持有,且无法释放。所以此时会出现死锁。
而为什么可重入锁就可以在嵌套调用时可以自动获得锁呢?我们通过图示和源码来分别解析一下。
还是打水的例子,有多个人在排队打水,此时管理员允许锁和同一个人的多个水桶绑定。这个人用多个水桶打水时,第一个水桶和锁绑定并打完水之后,第二个水桶也可以直接和锁绑定并开始打水,所有的水桶都打完水之后打水人才会将锁还给管理员。这个人的所有打水流程都能够成功执行,后续等待的人也能够打到水。这就是可重入锁。
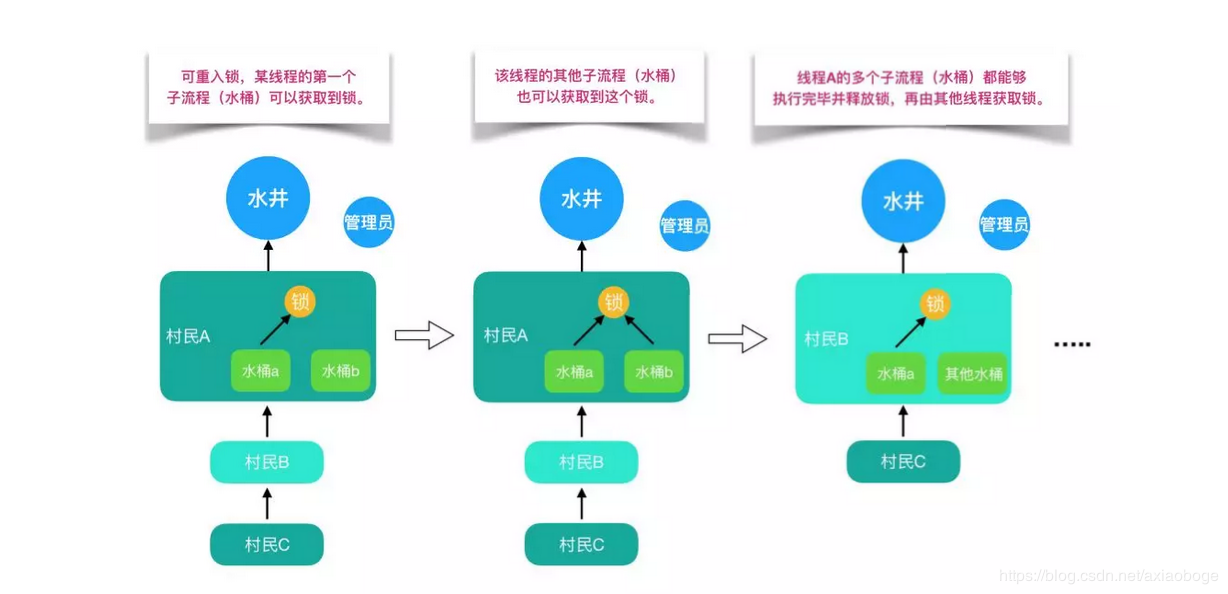
但如果是非可重入锁的话,此时管理员只允许锁和同一个人的一个水桶绑定。第一个水桶和锁绑定打完水之后并不会释放锁,导致第二个水桶不能和锁绑定也无法打水。当前线程出现死锁,整个等待队列中的所有线程都无法被唤醒。
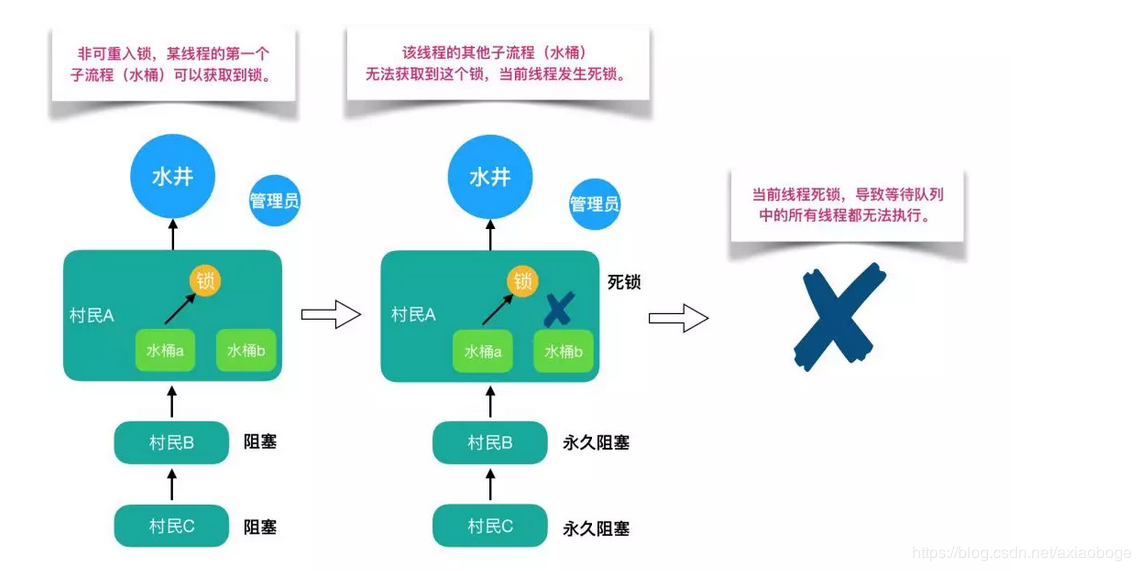
之前我们说过ReentrantLock和synchronized都是重入锁,那么我们通过重入锁ReentrantLock以及非可重入锁NonReentrantLock的源码来对比分析一下为什么非可重入锁在重复调用同步资源时会出现死锁。
首先ReentrantLock和NonReentrantLock都继承父类AQS,其父类AQS中维护了一个同步状态status来计数重入次数,status初始值为0。
当线程尝试获取锁时,可重入锁先尝试获取并更新status值,如果status == 0表示没有其他线程在执行同步代码,则把status置为1,当前线程开始执行。如果status != 0,则判断当前线程是否是获取到这个锁的线程,如果是的话执行status+1,且当前线程可以再次获取锁。而非可重入锁是直接去获取并尝试更新当前status的值,如果status != 0的话会导致其获取锁失败,当前线程阻塞。
释放锁时,可重入锁同样先获取当前status的值,在当前线程是持有锁的线程的前提下。如果status-1 == 0,则表示当前线程所有重复获取锁的操作都已经执行完毕,然后该线程才会真正释放锁。而非可重入锁则是在确定当前线程是持有锁的线程之后,直接将status置为0,将锁释放。

1 | synchronized void setA() throws Exception{ |
上面的代码就是一个可重入锁的一个特点,如果不是可重入锁的话,setB可能不会被当前线程执行,可能造成死锁。
需要注意的是,可重入锁加锁和解锁的次数要相等。
C==0表明未获得锁,Else表示已经获得锁,这时对state加1,相应的,每次释放锁都会对state减1
drawable
drawable
drawable常用作View的背景(还可以作为ImageView中的图像来显示)。是通过xml来定义的。
Drawable是个抽象类,是所有Dreawble对象的基类,每个具体的Drawable是它的子类。这就反映了Drawable是可以通过代码来创建的。
分类
1.BitmapDrawable
表示一张图片,可以直接接引原始的图片,或者通过XML的方式描述。
2.ShapeDrawble
通过颜色构造的图形
3.LayerDrawable
将不同的Drawable放置在不同的层上面达到一种叠加效果。XML标签是
4.StateListDrawable
对应着
它包含许多个item(表示一个具体的Drawable)里面包含了view的状态。故系统自上而下根据view的状态选择item。(找到一个就返回,没找到就选择默认的item)默认的item是不附带状态的。
5.LevelListDrawable
对应
感觉上可以自由选择自己想要的背景。
6.TransitionDrawable
对应
在其中确定自己的item(即item对应的drawable之前淡入淡出)
可以直接在view中设置为其背景
1 | <ImageView |
或者在代码中控制
1 | ImageView image = (ImageView) findViewById(R.id.mIv); |
问题:如何实现多个drawable的淡入淡出?
开启一个线程(死循环)每隔一段时间发送消息到UI主线程中替换主线程中的transitionDrawable对象中的图片就可以了,需要用到handler。
https://blog.csdn.net/z_zt_t/article/details/52761432
7.InsetDrawable
对应
很像drawable的padding属性,区别在于 padding表示drawable的内容与drawable本身的边距,insetDrawable表示两个drawable和容器之间的边距。
8.ScaleDrawable
对应与
9.ClipDrawable
对应与
https://blog.csdn.net/briblue/article/details/53528837
10.自定义Drawable
核心是draw方法(?)。系统调用draw方法来绘制view的背景。由此可得,可以通过重写drawable的draw方法来自定义drawable。
11.VectorDrawable
Android API 21(5.0)引入了一个Drawable的子类VectorDrawable目的就是用来渲染矢量图,AnimatedVectorDrawable用来播放矢量动画。
准备
使用矢量图要根据minSdkVersion来分3中不同的情况:
minSdkVersion>=21:用xml文件或者代码定义VectorDrawable,和普通的Drawable用法一样,不再需要额外任何东西;如何编写矢量图,下文有介绍;minSdkVersion<21:如果想要渲染矢量图的话必须在app模块的build.gralde文件里添加一行代码:
1 | defaultConfig { |
3. minSdkVersion<21以及更多:上面的第二种情况是使用兼容包,但是兼容包仅支持AppCompatImageView和AppCompatImageButton及其子类矢量图,而且矢量图的引用必须放在app:srcCompat属性中才会被识别并生效,代码必须这样写才行:
1 | <android.support.v7.widget.AppCompatImageView |
ic_oval.xml是我们使用xml编写的矢量图,如果想要TextView的drawableTop或者其他额外方式使用矢量图渲染,那么必须在Activity中加入代码:
1 | static { |
同时这个Activity必须继承AppCompatActivity这个compat兼容包属性才会生效。
minSdkVersion<21情况下在非app:srcCompat属性的地方使用矢量图时,需要将矢量图用drawable容器(如StateListDrawable, InsetDrawable, LayerDrawable, LevelListDrawable, 和RotateDrawable)包裹起来使用。否则会在低版本的情况下报错org.xmlpull.v1.XmlPullParserException: Binary XML file line #0: invalid drawable tag vector。minSdkVersion>=21则没有任何限制。
矢量图使用
准备工作做好之后,我们就需要自己动手编辑矢量图了。VectorDrawable类在xml中对应的是标签是vector。我目前所知道的是只有xml文件才能决定矢量图的样子(也就是编辑pathData、fillColor等属性),貌似无法使用代码来决定矢量图的绘制逻辑,而只能使用代码加载编辑好的xml文件,这个xml文件有两种方法来创建:
- 右击drawable–>Drawable resource file–>设置
root element为vector,这样的矢量图绘制逻辑完全掌握在开发者手里; - 右击drawable–>Vector Asset,选择SVG或者PSD文件直接生成根标签为vector的xml文件,可以百度或者Google怎样把png转换成SVG。
写了这么多字,一直在瞎扯淡而没谈重点,下面我们看下根标签为vector的xml文件的真面目,代码:
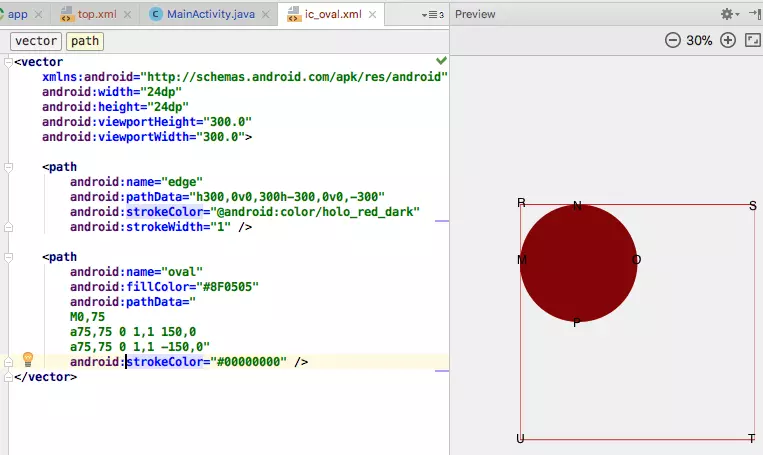
上图中标签vector使用了四个属性:android:width="24dp"、android:height="24dp"、android:viewportHeight="300.0"、android:viewportWidth="300.0"。
- width和height:当使用这个矢量图的View的宽高是wrap_content 的时候这两个属性才生效;
- viewportWidth和viewportHeight:决定画布的宽高,是定义的一个虚拟空间,方便编辑pathData属性,如果pathData中的点超出了这个虚拟空间,超出的部分将不会展现给用户;虚拟空间的原点仍然还是在左上角(R点就是原点)。
path标签是vector标签的子标签,它使用了以下属性:
android:name:类似View的id属性,方便path被引用,如上图的edge是虚拟空间四个边界的path,oval是一个椭圆的path;android:fillColor:填充path的颜色,如果没有定义则不填充pathandroid:strokeColor:path边框颜色,如果没有定义则不显示边框android:strokeWidth:path边框的粗细尺寸android:pathData:path指令,决定path的移动和绘制逻辑,这个是最主要的属性,下面详细讨论。
更多path属性请参考链接。
pathData的指令和Path类的API方法基本差不多,比如M指令对应moveTo方法,m指令对应rMoveTo方法,下面是一些基本的指令:
- Mx,y:移动到点(x,y)
- Lx,y:直线连到点x,y,简化命令H(x)水平连接和V(y)垂直连接;
- Qx1,y1 x2,y2:二阶贝塞尔曲线,控制点(x1,y1),终点x2,y2;
- Cx1,y1 x2,y2 x3,y3:三阶贝塞尔曲线,控制点(x1,y1)( x2,y2),终点x3,y3;
- Tx y:平滑的二阶贝塞尔曲线,参数只有一个点(x,y),这个点是结束点,控制点是前一个二阶贝塞尔曲线的控制点相对于前一个贝塞尔曲线的结束点的镜像点。
- Sx2,y2 x,y:平滑的三阶贝塞尔曲线,参数为(x2,y2 x,y) ,x2,y2 为第二个控制点,x,y为绘制终点,那么第一个控制点则是前一个三阶曲线的第二个控制点相对于前一个三阶曲线终点的镜像点。
- Arx,ry x-axis-rotation large-arc-flag,sweep-flag x,y:ellipse arc圆弧曲线
- z:close闭合
……
- z:close闭合
每个指令都有大小写形式,大写表示后面的参数是绝对坐标,小写表示相对于上一个点的相对坐标位置,参数可以用逗号或者空格分离。
只要掌握上面5个基本指令就能编辑pathData并且绘制一些酷炫的SVG。更详细全面的path指令请参阅链接。
估计你已经发现了,圆弧曲线指令A竟然那么多参数,这直接吓跑了很多的程序员,其实也并不难,且慢慢道来。
先根据图1里的代码来分析pathData指令。如图一所示,edge这个path使用了四个相对指令,首先指令h300 0相对向右水平移动300到点S,然后指令v0 300相对向下垂直移动300到T,再次指令h-300 0相对向左水平移动300到U,最后指令v0 -300相对向上垂直移动300到起点R,这样就根据属性strokeColor和strokeWidth绘制了四条直线,最后一个指令可以使用z代替。这很简单吧?!
再来看oval这个path。它使用了三条指令。第一条指令移动到点M处,第二条指令a75,75 0 1,1 150,0绘制M-N-O的弧线,第三条指令a75,75 0 1,1 -150,0绘制O-P-M的弧线。a指令共有7个参数:rx和ry表示椭圆的两个半径,x-axis-rotation表示x轴的旋转角度,x和y表示绘制椭圆弧线的终点,这5个参数很简单很好理解,large-arc-flag和sweep-flag这两个参数有点唬人。
解释large-arc-flag和sweep-flag这两个参数之前先考虑下这个题目:已知椭圆的半径rx和ry,请绘制若干条从起始点A到终点B的椭圆弧线。题目中是若干条,那到底几条啊?一般情况下会有四条椭圆弧线(特殊情况是rx=线段AB的一半或者ry=线段AB的一半,这时候的椭圆弧线只有两条),而large-arc-flag和sweep-flag这两个参数就从这四个椭圆弧线中选取了最终的一条进行绘制。large-arc-flag决定是大弧线还是小弧线,1大0小,sweep-flag决定是顺时针弧线还是逆时针弧线,1顺0逆。
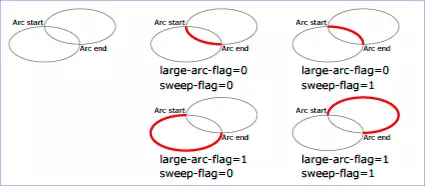
图2
看图2希望你能明白这两个参数的意义。
有人可能会问,图1的oval path是个圆,竟然使用了两个a指令,使用一个a指令就能绘制圆的,只要终点回到起始点就能绘制圆的path了,刚开始我也是这样认为的,比如下面的代码:
1 | <vector |
上面的代码的path从起始点又回到了起始点,不会绘制任何东西,终点x y需要和起始点错开几个像素比如android:pathData="M150,150 a75,75 0 1,1 0,1"就大约是一个圆path,为什么说是大约一个圆?因为起始点和终点不在一起,这只是一个圆的大弧线部分。推荐使用两条a指令绘制圆path,因为一条a指令绘制的不是真正的圆path。
group标签
path没有scale、rotate和translate这三种属性,因此也不能执行这三种属性动画,要达到这样的目的需要借助group这个标签。group标签也是vector的一个子标签,它可以作为path或者其他group的父标签使用,将path和group组合成一个组来附加一些变换操作,这些变换操作包括scale、rotate和translate共三种。这张图3是来自android官网的vector标签树型图:
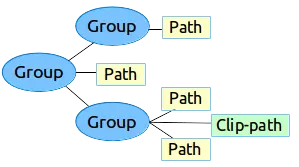
图3
。
- android:name:group的名字;
- android:rotation:group的旋转角度,默认0。
- android:pivotX:scale和rotation变换中心点的X坐标,默认0;
- android:pivotY:scale和rotation变换中心点的Y坐标,默认0;
- android:scaleX:X轴方向的缩放,默认1;
- android:scaleY:Y轴方向的缩放,默认1;
- android:translateX:X轴方向的移动距离,默认0;
- android:translateY:Y轴方向的移动距离,默认0。
这是group的全部属性了,属性都很简单,不需要解释。
clip-path标签
- android:name:clip-path的名字;
- android:pathData:clip-path的路径。
1 | <vector |
上面代码定义了两个clip-path,其效果如图4所示。
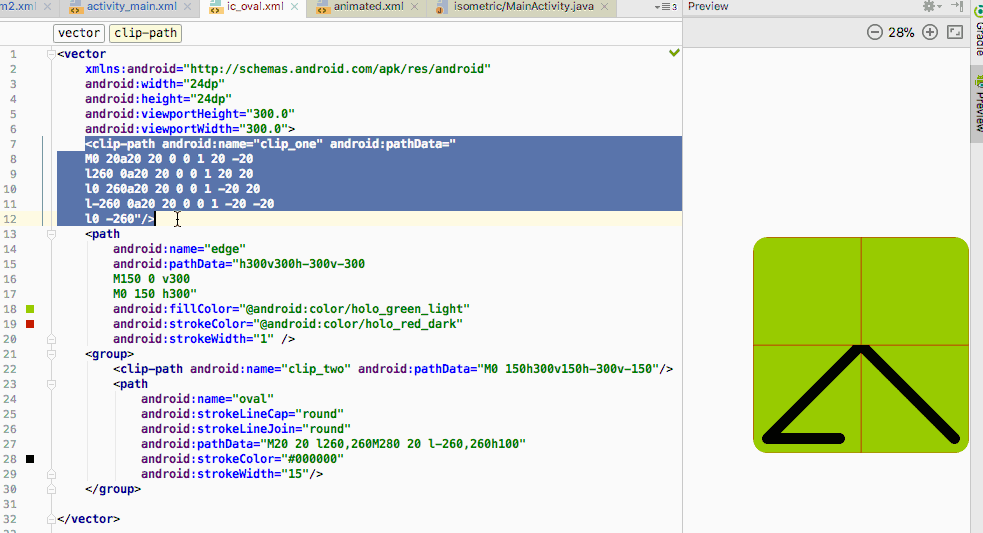
图4.gif
build.gradle中vectorDrawables.useSupportLibrary属性
build.gradle中的vectorDrawables.useSupportLibrary默认是false,不设置为true的话会有什么问题吗?讨论这个问题也需要根据minSdkVersion具体分析:
minSdkVersion>=21:这么高的API根本就不需要兼容包,仍然可以渲染矢量图;minSdkVersion<21:不再使用矢量图兼容包,不能渲染矢量图,但是有趣的是vector标签仍然可以使用,低版本的API完全把VectorDrawable当作Drawable使用了,VectorDrawable的特性完全失效。原理是vector xml文件会生成对应的png文件,使用png方式渲染图片,和矢量图没有任何关系。值得注意的是生成的png图片size很小而且会忽略vector标签的android:tint属性(貌似只忽略这个属性,我试过vector标签的android:alpha属性在生成的png图片中仍然有效,生成的png文件目录是app/build/generated/res/pngs/debug,minSdkVersion>=21或者vectorDrawables.useSupportLibrary=true的话不会生成这些png图片)。而且path标签的color相关的属性不能引用colors.xml的值,android:strokeColor="@android:color/holo_red_dark"这样写的话会编译失败,提示错误:Can't process attribute android:strokeColor="@android:color/holo_red_dark": references to other resources are not supported by build-time PNG generation,而只能写原生的16进制color值比如android:strokeColor="#234aac"。
想看具体信息请查看这篇文章。
SVG实战
我做的项目中一张扑克png资源大小2k左右,我试着用矢量图画这些扑克牌。代码如下:
1 | <vector xmlns:android="http://schemas.android.com/apk/res/android" |
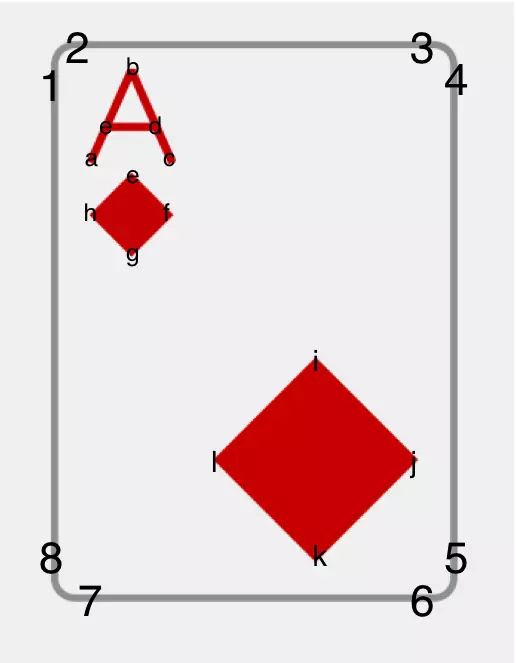
图5
代码很简单,只有4条path。border路径顺序是1-2-3-4-5-6-7-8-1, a的路径是a-b-c-d-e,small_diamond的路径是e-f-g-h,big_diamond的路径是i-j-k-l。这个xml文件只有1k。
vector属性
android:alpha:矢量图的透明度,范围0-1,默认1;android:tint:矢量图的颜色,这个颜色值会覆盖所有与color相关的属性比如path的fillColor和strokeColor等;这个属性会被API setColorFilter(ColorFilter)覆盖。android:tintMode:色彩混合模式,可选值有很多,下面详细讨论,默认src_in。android:autoMirrored:当布局方向变成right-to-left的时候,矢量图是否自动镜像,默认false,这个属性在API>=19才生效。
关于tintMode,先看下PorterDuff这类的源码:
1 | public class PorterDuff { |
首先类名PorterDuff是什么意思呢?PorterDuff是两个人名的组合: Thomas Porter和Tom Duff,他们1984年在ACM SIGGRAPH计算机图形学发表论文《Compositing digital images》,最早提出图形混合概念,极大地推动了图形图像学的发展,有兴趣的同学可以自行查阅资料。
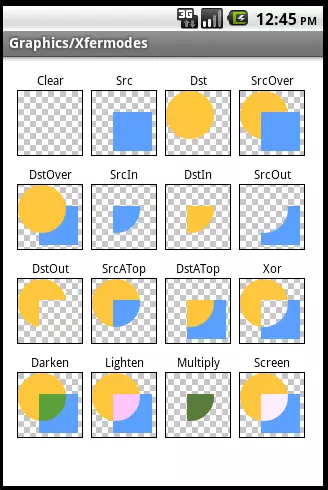
图1
PorterDuff共有18个模式可选,但是android:tintMode可选值只有六个:MULTIPLY、SCREEN、ADD、SRC_ATOP、SRC_IN、SRC_OVER,(xml文件只提供这6个的原因我不知道,请大神留言告知)。当然想使用其余12个tintMode模式也是可以的,需要用代码调用API Drawable.setTintMode(PorterDuff.Mode)即可,可以达到相应tintMode的效果。
tint属性是Android 5.0引入的,Android 6.0又引入了drawableTint的属性。
Button和TextView等一些组件会多出下面6个属性:
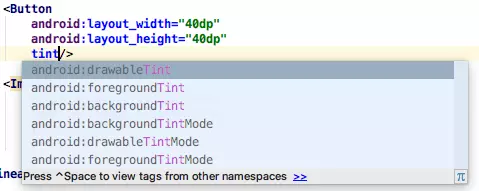
图2
ImageView会多出下面6个属性:
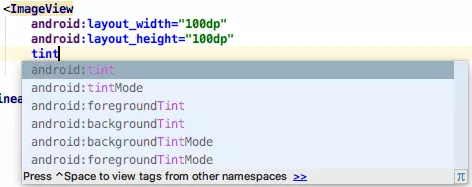
图3
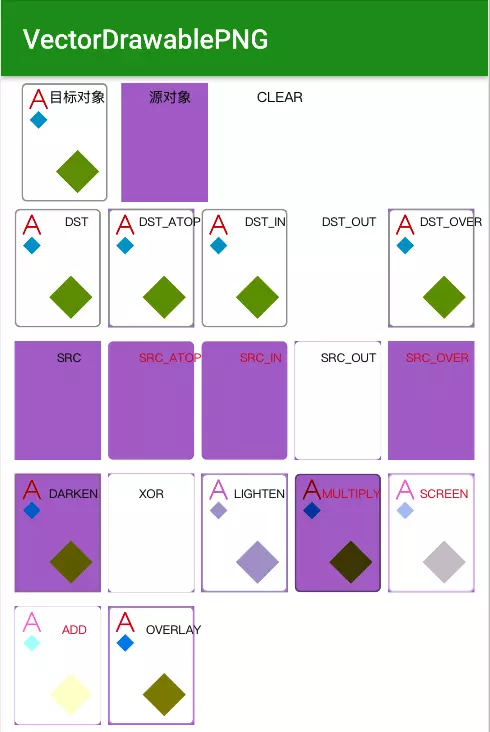
图4
我们对矢量图进行调色,先看效果如图4所示,图4中红色文字表示xml允许使用的6个tintMode。下面贴出代码:
1 | // poker_a.xml |
MainActivity.java代码:
1 | // MainActivity.java |
色彩混合涉及到两个对象,目标对象和源对象,这里的目标对象是poker_a.xml这个矢量图,源对象是tint设置的颜色值,为啥这样说呢,记着这个原则,先绘制的是目标对象,我们就是要对目标对象进行调色。对目标对象调色后的对象叫做复合对象。
有了这两个对象,怎么进行调色呢?这里有很多计算公式,公式中又有很多元素,先来看下这些元素:
1 | * Sa:Source alpha,源对象的Alpha通道; |
下面对这18个tintMode进行剖析,该文受到这篇文章的启发。
CLEAR
复合对象的ARGB值是[0,0],完全透明,相当于清除画布上的图像了。
DST
[Da, Dc],只保留目标对象的alpha和color值,因此绘制出来的只有目标对象,相当于根本就没有进行调色。
DST_ATOP
[Sa, Sa * Dc + Sc * (1 - Da)],两者相交处绘制目标对象,不相交的地方绘制源对象,并且相交处的效果会受到源对象和目标对象alpha的影响。
DST_IN
[Sa * Da, Sa * Dc],两者相交的地方绘制目标对象,不相交的地方不进行绘制,并且相交处的效果会受到源对象对应地方透明度的影响。
DST_OUT
[Da * (1 - Sa), Dc * (1 - Sa)],两者不相交的地方绘制目标对象,相交处根据源对象alpha进行过滤,完全不透明处则完全过滤,完全透明则不过滤。(亲测正确)
DST_OVER
[Sa + (1 - Sa)*Da, Rc = Dc + (1 - Da)*Sc],目标对象绘制在源对象的上方。
SRC
[Sa, Sc],只保留源对象的alpha和color,因此绘制出来只有源对象。
SRC_ATOP
[Da, Sc * Da + (1 - Sa) * Dc],两者相交处绘制源对象,不相交的地方绘制目标对象,并且相交处的效果会受到源对象和目标对象alpha的影响。
SRC_IN
[Sa * Da, Sc * Da],两者相交处绘制源对象,不相交的地方不进行绘制,并且相交处的效果会受到源对象对应地方透明度的影响。
SRC_OUT
[Sa * (1 - Da), Sc * (1 - Da)],两者不相交的地方绘制源对象,相交处根据目标对象alpha进行过滤,完全不透明处则完全过滤,完全透明则不过滤。(亲测正确)
SRC_OVER
[Sa + (1 - Sa)*Da, Rc = Sc + (1 - Sa)*Dc],源对象绘制在目标对象的上方。
DARKEN
[Sa + Da - SaDa, Sc(1 - Da) + Dc*(1 - Sa) + min(Sc, Dc)],顾名思义,效果会变暗。进行对应像素比较,取较暗值(即较小值),如果色值相同则进行混合;如果两个对象都完全不透明,取较暗值,否则使用上面算法进行计算,受到源对象和目标对象对应色值和alpha值影响。结果复合对象的alpha值会变大。XOR[Sa + Da - 2 * Sa * Da, Sc * (1 - Da) + (1 - Sa) * Dc],不相交的地方按原样绘制源对象和目标对象,相交的地方受到对应alpha和颜色值影响,按公式进行计算,如果都完全不透明则相交处完全不绘制。LIGHTEN[Sa + Da - SaDa, Sc(1 - Da) + Dc*(1 - Sa) + max(Sc, Dc)],顾名思义,效果会变亮。进行对应像素比较,取较亮值(即较大值),如果色值相同则进行混合;如果两个对象都完全不透明,取较亮值,否则使用上面算法进行计算,受到源对象和目标对象对应色值和alpha值影响。
MULTIPLY
[Sa * Da, Sc * Dc],正片叠底,即查看每个通道中的颜色信息,目标色与源色复合。结果色总是较暗的颜色。任何颜色与黑色复合产生黑色,任何颜色与白色复合保持不变。(这个理论貌似和现实生活的颜色混合的结果不一致,现实生活中黄色和白色混合会是黄白色而不是白色)。
SCREEN
[Sa + Da - Sa * Da, Sc + Dc - Sc * Dc],滤色模式,这个模式与我们所用的显示屏原理相同,因此也被翻译成屏幕模式;保留两个图层中较白的部分,较暗的部分被遮盖,图层中纯黑的部分变成完全透明,纯白部分完全不透明,其他的颜色根据颜色级别产生半透明的效果。
ADD
Saturate(S + D),饱和度叠加
OVERLAY
算法同时进行进行 Multiply(正片叠底)混合还是 Screen(屏幕)混合,是进行 Multiply混合还是 Screen混合,取决于目标对象的颜色值,目标对象颜色的高光与阴影部分的亮度等细节会被保留。
这18个模式终于介绍完了,再次感谢这篇文章的作者。
path属性
android:strokeLineCap:顾名思义,设置线条的帽子,round圆角、square正方形、butt臀,默认是butt;
android:strokeLineJoin:线条拐弯处的样式,round圆角、bevel斜角、miter斜切尖角,默认是miter;
android:strokeMiterLimit:android:strokeLineJoin为miter的时候这个属性才发挥作用。设置miter斜切尖角长度(用miter_length表示)与线条宽度(用line_width表示)比例值的上限,默认是4,strokeMiterLimit = miter_length / line_width,这个属性设定了这个比例的最大值,超过这个值的尖角不再显示尖角而是bevel斜角。
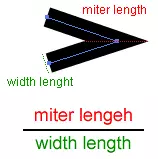
图5
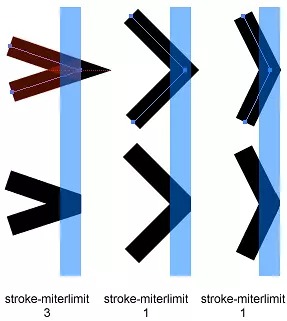
图6
如果你希望尖角多一些,就把这个属性设置大一些。在特别尖的拐弯处的点,点的这个比例可能大与strokeMiterLimit,那么就不显示尖角效果而是类似bevel斜角的效果,这样看起来不是很突兀,比较美观。
图5和图6来自
文章
;
android:trimPathStart:从路径起始位置截断路径的比率,取值范围0-1,默认0;
android:trimPathEnd:从路径结束位置截断路径的比率,取值范围0-1,默认1;
android:trimPathOffset:设置路径截取的偏移比例,取值范围0-1,默认0;
利用android:trimPathStart和android:trimPathEnd可以做一些入场和出场动画,链接android:fillType:API 24才引入的这个属性,取值nonZero和evenOdd,默认nonZero。
关于android:fillType这个属性,需要花点篇幅讨论下。讨论这个属性之前,先看下代码及其对应的效果:
1 |
|

图7
代码中有两条path,前者的fillType是默认的noneZero,后者的fillType是evenOdd,除了这两个属性外,其余属性一模一样(name属性和M指令的起始位置为了显示的区别,忽略好吧😄)。两者的效果图如图7所示。fillType的原理是什么呢?为啥会导致这样的效果呢?
这里需要提一点,代码中每一条path都绘制了两个圆,四个圆的每一个圆都是通过两条a指令绘制完成的,如果你不清楚a指令的参数,请仔细看完Android矢量图I–VectorDrawable基础这篇文章并搞明白a指令后再回来看本文。这8条a指令的第5个参数都是1表示顺时针,请记住都是顺时针,因为fillType属性值noneZero跟path的方向有很大关系。
首先来看下默认的noneZero值。多看维基百科,那里的解释最权威。有一个多边形C,我们判断是否要对C的子多边形C1形成的一块区域进行填充,那么先定义一个变量value=0,根据value的值来决定是否对C1进行填充;在这个C1区域内任意选择一个点P,从这个点P向任意方向发射一条无限长的直线L,但是这个方向需要直线L与C1至少有一个交点,然后找出直线L与C所有的交点,每个交点处的方向是顺时针value++,顺时针value–,如果最后的value不是0,那么就对C1填充,否则不填充。
如果你不明白上面粗体文字的含义,那就根据上面代码名字为noneZero这个path来分析下。这条path包含4个a指令,其实也就是4个形状为弧线的子path:弧线AB、弧线BA、弧线CD、弧线DC,相应地我们就要判断四块区域(outer_a、outer_b、inner_a、inner_b)是否要进行fill(填充,这里的填充默认是填充内部)。对于区域outer_a,我们在其内部选择任意一点P,从P发射一条无限长直线,直线需要与子多边形弧线AB相交至少一个点,该点是P1,直线与多边形C的交点是P1,是顺时针,value=P1=1,不为0,该区域填充;对于区域inner_a,我们在其内部选择任意一点R,从R发射一条无限长直线,直线需要与子多边形弧线CD相交至少一个点,该点是R1,直线与多边形C的交点是R1和R2,value=R1+R1=1+1=2,不为0,该区域填充。如图8所示,
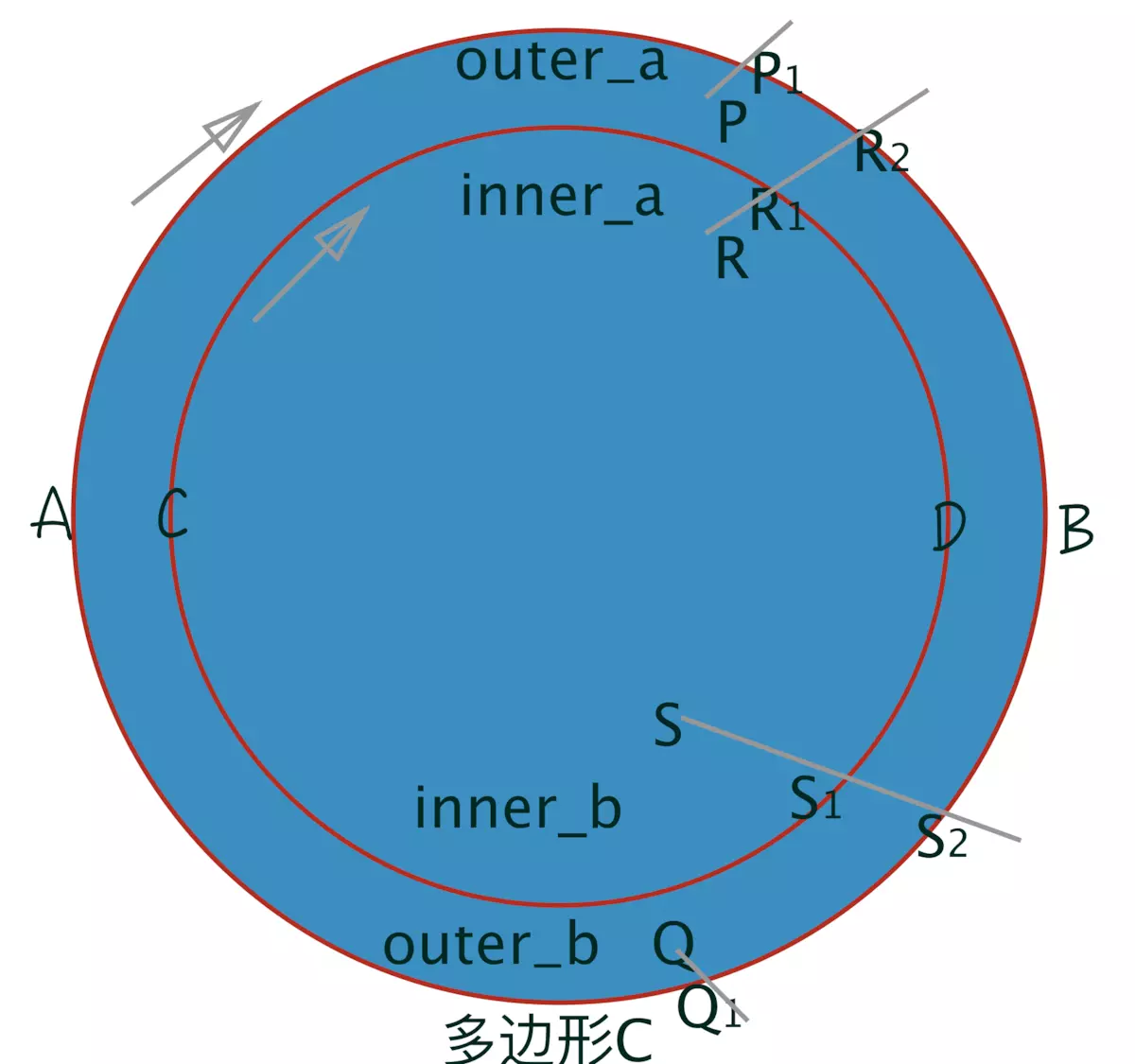
图8
为了加深下印象,再来举个例子。看下面的代码:
1 |
|
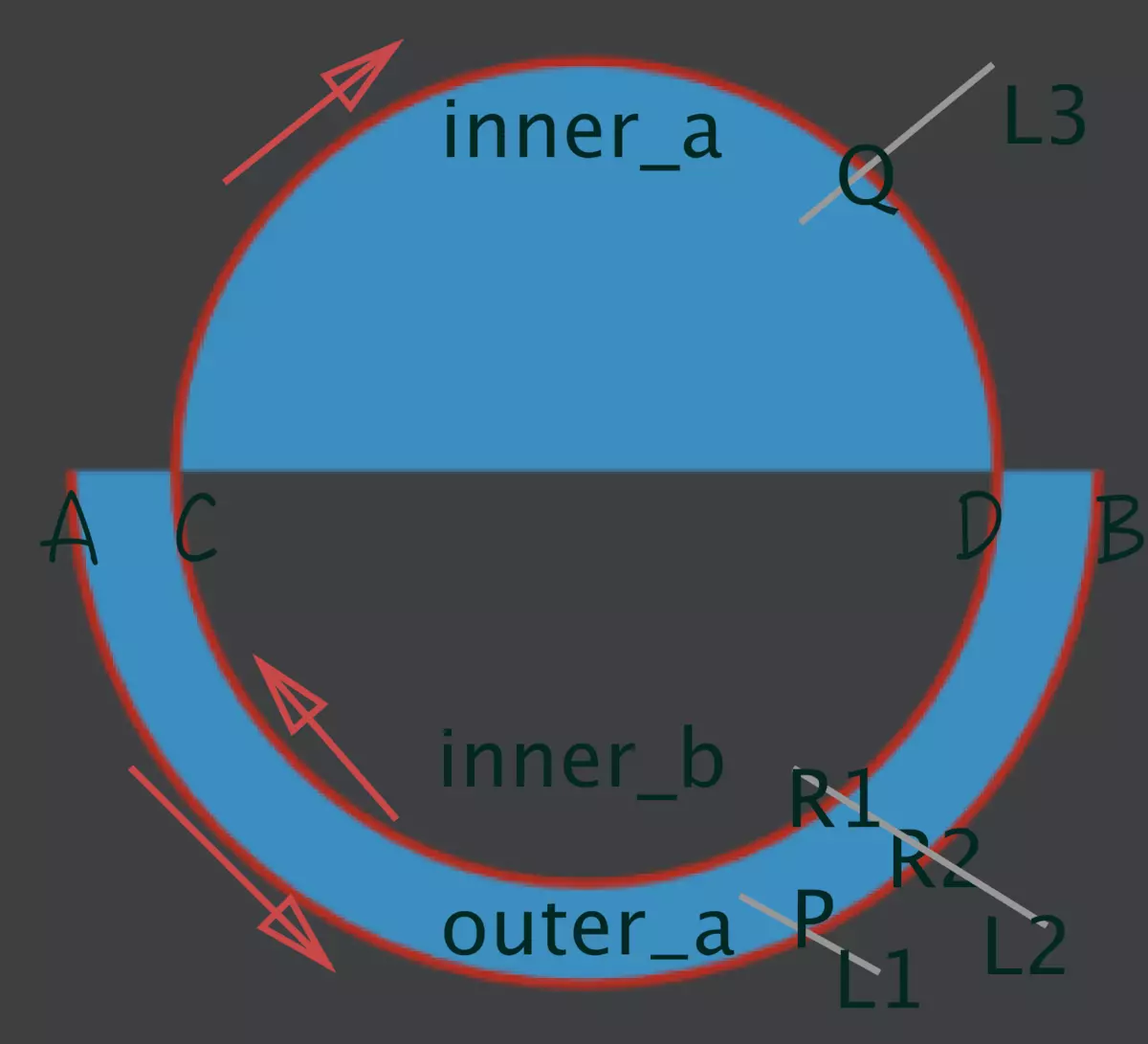
图9
你运行上面的代码,不出问题的矢量图应该如图9所示。代码首先从A到B逆时针绘制椭圆弧,然后从C到D顺时针绘制椭圆弧,最后从D到C顺时针绘制椭圆弧。最终的多边形C包含三个子区域outer_a、inner_a、inner_b。对于outer_a,其value=P=-1,非0那就填充;对于inner_a,其value=Q1=1,非0那就填充;对于inner_b,其value=R1+R2=1+(-1)=0,0那就不填充。
如果你已经明白了noneZero,那么evenOdd就非常非常简单了,先看维基百科,它与指针方向没有关系了,一句话你就能明白:如果虚拟直线与多边形C的交点数目为奇数就填充内部,偶数就不填充内部。如果还不明白,就举个例子,看代码:
1 |
|
上面代码的结果也是如图9所示,那么拿图9来解释:对于outer_a,其只有一个交点P,奇数那就填充;对于inner_a,其只有一个交点Q,奇数那就填充;对于inner_b,有两个交点R1和R2,偶数那就不填充。
怀着紧张的心情,fillType属性终于介绍了完了,真害怕写错而误导读者,如果有错误的地方或者有更好的分析方法,请大神批评指正。这里有两篇文章,帮助理解fillType:文章1、文章2。再说一点,如果你是用tint属性对矢量图进行调色,注意fillType属性值会对结果造成同样的影响。
最后,你如果查看Paint类的内部类FillType的源码,会发现还有另外两种fillType:
1 | /** |
对这另外两种fillType,Google程序员的注释已经解释的很清楚了,我就不解释了,否则可能越解释越乱,越乱越糊涂。
mipmap
我们创建新项目时,它会帮助我们自动生成六个文件夹(密度不同):
- drawable-ldpi (low:120dip)
- drawable
- drawable-mdpi (medium:160dip)
- drawable-hdpi (high :240dip)
- drawable-xhdpi (xhigh :320dip)
- drawable-xxhdpi (xxhigh:480dip)
一般的做法是,将图片等资源放在drawable-hdip中,将一些和XML文件相关的内容(图片选择器、文字颜色选择器、自定义形状等)放在drawable中。
Google推荐:像素使用dip,文字使用sp。并且没有推荐图片放在mipmap中。
在mdip文件夹,1dip=1px。
关于dp,dip,sp,pt,px的区别,可参考:附录一。
关于图片在不同目录下的显示举例,可参考:附录二。
官方解释:
mipmap——用于存放原生图片(图ic_launcher.png),缩放上有性能优化;
drawable——存放图片、xml,和Eclipse没有区别;
附录一
dip : device independent pixels(设备独立像素). 不同设备有不同的显示效果,这个和设备硬件有关,一般我们为了支持WVGA、HVGA和QVGA 推荐使用这个,不依赖像素。
dp : 和dip相同。
px : pixels(像素),一个像素通常被视为图像的最小的完整采样,不同设备显示效果相同,一般我们HVGA代表320x480像素,这个用的比较多。
pt : point,是一个标准的长度单位,1pt=1/72英寸,用于印刷业,非常简单易用。
sp : scaled pixels(放大像素). 主要用于字体显示best for textsize。
in :(英寸):长度单位。
分辨率 :分为显示分辨率(屏幕分辨率)和图像分辨率。
显示分辨率:屏幕图像的精密度,是指显示器所能显示的像素有多少。显示器可 显示的像素越多,画面就越精细。显示分辨率一定的情况下,显示屏越小图像越清晰,反之,显示屏大小固定时,显示分辨率越高图像越清晰。
图象分辨率 :单位英寸中所包含的像素点数。
换算公式
1 | public static float applyDimension(int unit, float value, |
附录二
mdpi与hdpi是2:3的关系
mdpi与xhdpi是1:2的关系
ldpi 与mdpi是3:4的关系dp与px换算公式:
pixs =dips * (densityDpi/160).
dips=(pixs*160)/densityDpi
现在假设,在一个项目中,你将一张60px60px的图片放到mdpi中,它的大小是6060;
若把它拿到hdpi中,那么它的大小应该是40*40,图片缩小。
结论:
mipmap仅仅用于应用启动图标,可以根据不同分辨率进行优化。其他的图标资源,还是要放到drawable文件夹中。
layout
android-布局介绍
布局
一.基本理论
Android六大基本布局分别是
线性布局LinearLayout、表格布局TableLayout、相对布局RelativeLayout、
层布局FrameLayout、绝对布局AbsoluteLayout、网格布局GridLayout。
其中,表格布局是线性布局的子类。
在手机程序设计中,绝对布局基本上不用,用得相对较多的是线性布局和相对布局。
学习基本布局要理解两个比较基础概念的图:
(一)Android布局管理器的类图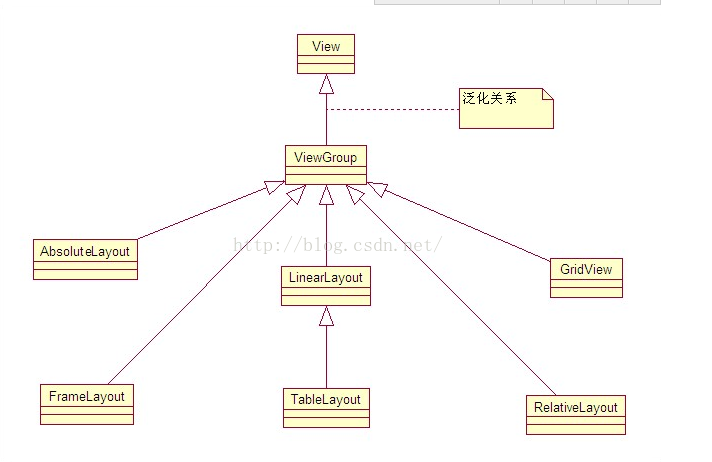
上面这个类图只是说了六大基本布局的关系,其实ViewGroup还有其他一些布局管理器。
这里要理解一点就是布局也是布局管理器,因为布局里面还可以添加布局。
(二)Android布局的XML关系图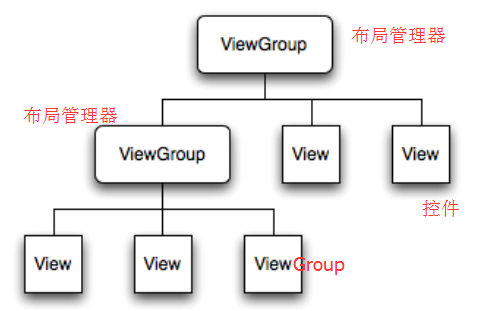
布局管理器里面既可以添加多个布局管理器又可以添加多个控件,而控件里面不能在添加布局或控件了。
二.各个布局的使用
(一)线性布局
线性布局在开发中使用最多,具有垂直方向与水平方向的布局方式,通过设置属性“android:orientation”控制方向,属性值垂直(vertical)和水平(horizontal),默认水平方向。
- android:gravity:内部控件对齐方式,常用属性值有center、center_vertical、center_horizontal、top、bottom、left、right等。
这个属性在布局组件RelativeLayout、TableLayout中也有使用,FrameLayout、AbsoluteLayout则没有这个属性。 - center:居中显示,这里并不是表示显示在LinearLayout的中心,当LinearLayout线性方向为垂直方向时,center表示水平居中,但是并不能垂直居中,此时等同于center_horizontal的作用;同样当线性方向为水平方向时,center表示垂直居中,等同于center_vertical。
- top、bottom、left、right顾名思义为内部控件居顶、低、左、右布局。
这里要与android:layout_gravity区分开,layout_gravity是用来设置自身相对于父元素的布局。 - android:layout_weight:权重,用来分配当前控件在剩余空间的大小。
使用权重一般要把分配该权重方向的长度设置为零,比如在水平方向分配权重,就把width设置为零。
(二)RelativeLayout
相对布局可以让子控件相对于兄弟控件或父控件进行布局,可以设置子控件相对于兄弟控件或父控件进行上下左右对齐。
RelativeLayout能替换一些嵌套视图,当我们用LinearLayout来实现一个简单的布局但又使用了过多的嵌套时,就可以考虑使用RelativeLayout重新布局。
相对布局就是一定要加Id才能管理。
RelativeLayout中子控件常用属性:
- 相对于父控件,例如:android:layout_alignParentTop=“true”
android:layout_alignParentTop 控件的顶部与父控件的顶部对齐;
android:layout_alignParentBottom 控件的底部与父控件的底部对齐;
android:layout_alignParentLeft 控件的左部与父控件的左部对齐;
android:layout_alignParentRight 控件的右部与父控件的右部对齐; - 相对给定Id控件,例如:android:layout_above=“@id/**”
android:layout_above 控件的底部置于给定ID的控件之上;
android:layout_below 控件的底部置于给定ID的控件之下;
android:layout_toLeftOf 控件的右边缘与给定ID的控件左边缘对齐;
android:layout_toRightOf 控件的左边缘与给定ID的控件右边缘对齐;
android:layout_alignBaseline 控件的baseline与给定ID的baseline对齐;
android:layout_alignTop 控件的顶部边缘与给定ID的顶部边缘对齐;
android:layout_alignBottom 控件的底部边缘与给定ID的底部边缘对齐;
android:layout_alignLeft 控件的左边缘与给定ID的左边缘对齐;
android:layout_alignRight 控件的右边缘与给定ID的右边缘对齐; - 居中,例如:android:layout_centerInParent=“true”
android:layout_centerHorizontal 水平居中;
android:layout_centerVertical 垂直居中;
android:layout_centerInParent 父控件的中央;
(三)FrameLayout
帧布局或叫层布局,从屏幕左上角按照层次堆叠方式布局,后面的控件覆盖前面的控件。
该布局在开发中设计地图经常用到,因为是按层次方式布局,我们需要实现层面显示的样式时就可以
采用这种布局方式,比如我们要实现一个类似百度地图的布局,我们移动的标志是在一个图层的上面。
在普通功能的软件设计中用得也不多。层布局主要应用就是地图方面。
(四)AbsoluteLayout
绝对布局中将所有的子元素通过设置android:layout_x 和 android:layout_y属性,将子元素的坐标位置固定下来,即坐标(android:layout_x, android:layout_y) ,layout_x用来表示横坐标,layout_y用来表示纵坐标。屏幕左上角为坐标(0,0),横向往右为正方,纵向往下为正方。实际应用中,这种布局用的比较少,因为Android终端一般机型比较多,各自的屏幕大小。分辨率等可能都不一样,如果用绝对布局,可能导致在有的终端上显示不全等。
(五)TableLayout
表格布局,适用于多行多列的布局格式,每个TableLayout是由多个TableRow组成,一个TableRow就表示TableLayout中的每一行,这一行可以由多个子元素组成。实际上TableLayout和TableRow都是LineLayout线性布局的子类。但是TableRow的参数android:orientation属性值固定为horizontal,且android:layout_width=MATCH_PARENT,android:layout_height=WRAP_CONTENT。所以TableRow实际是一个横向的线性布局,且所以子元素宽度和高度一致。
- ++注意:在TableLayout中,单元格可以为空,但是不能跨列,意思是只能不能有相邻的单元格为空。++
TableLayout常用属性:
- android:shrinkColumns:设置可收缩的列,内容过多就收缩显示到第二行
- android:stretchColumns:设置可伸展的列,将空白区域填充满整个列
- android:collapseColumns:设置要隐藏的列
列的索引从0开始,shrinkColumns和stretchColumns可以同时设置。
子控件常用属性:
- android:layout_column:第几列
- android:layout_span:占据列数
屏幕中心是一个类似Material布局,底部是一个页面切换的导航栏。底部布局通过设置android:stretchColumns=”0,1,2,3″来让四个按钮同样大小显示并填充到整个宽度,中心区域主要使用android:stretchColumns=”0,1,2″填充显示以及android:layout_span=”2″控制大内容跨列显示。
(六)GridLayout(网格布局)
作为android 4.0 后新增的一个布局,与前面介绍过的TableLayout(表格布局)其实有点大同小异;
不过新增了一些东东
- 跟LinearLayout(线性布局)一样,他可以设置容器中组件的对齐方式
- 容器中的组件可以跨多行也可以跨多列(相比TableLayout直接放组件,占一行相比较)
常用属性:
排列对齐:
- 设置组件的排列方式: android:orientation=”” vertical(竖直,默认)或者horizontal(水平)
- 设置组件的对齐方式: android:layout_gravity=”” center,left,right,buttom
设置布局为几行几列:
- 设置有多少行: android:rowCount=”4” //设置网格布局有4行
- 设置有多少列: android:columnCount=”4” //设置网格布局有4列
设置某个组件位于几行几列
注:都是从0开始算的哦!
- 组件在第几行: android:layout_row = “1” //设置组件位于第二行
- 组件在第几列: android:layout_column = “2” //设置该组件位于第三列
设置某个组件横跨几行几列:
- 横跨几行: android:layout_rowSpan = “2” //纵向横跨2行
- 横跨几列: android:layout_columnSpan = “3” //横向横跨2列
这里要说明一点:
通过android:layout_rowSpan和android:layout_columnSpan设置表明组件横越的行数与列数
再通过:android:layout_gravity = “fill” 设置表明组件填满所横越的整行或者整列
用法总结:
- GridLayout使用虚细线将布局划分为行,列和单元格,同时也支持在行,列上进行交错排列
- 使用流程:
step 1. 先定义组件的对其方式 android:orientation 水平或者竖直
step 2. 设置组件所在的行或者列,记得是从0开始算的
step 3. 设置组件横跨几行或者几列;设置完毕后,需要在设置一个填充:android:layout_gravity = “fill”
可能遇到的问题:
当读者将布局设置为GridLayout时,会出现 莫名其妙的报错,
如果代码语法逻辑没有错的话,就可能是配置文件 AndroidManifest.xml 的问题了
因为GridLayout是android 4.0 后才推出的,API Level 为 14
只需要将配置文件中的 MinSDK改成14或者以上版本 即可,保存,问题就解决了!
除上面讲过之外常用的几个布局的属性:
- layout_margin
用于设置控件边缘相对于父控件的边距
android:layout_marginLeft
android:layout_marginRight
android:layout_marginTop
android:layout_marginBottom - layout_padding
用于设置控件内容相对于控件边缘的边距
android:layout_paddingLeft
android:layout_paddingRight
android:layout_paddingTop
android:layout_paddingBottom - layout_width/height
用于设置控件的高度和宽度
wrap_content 内容包裹,表示这个控件的里面文字大小填充
fill_parent 跟随父窗口
match_parent - gravity
用于设置View组件里面内容的对齐方式
top bottom left right center等 - android:layout_gravity
用于设置Container组件的对齐方式
android:layout_alignTop 本元素的上边缘和某元素的的上边缘对齐
android:layout_alignLeft 本元素的左边缘和某元素的的左边缘对齐
android:layout_alignBottom 本元素的下边缘和某元素的的下边缘对齐
android:layout_alignRight 本元素的右边缘和某元素的的右边缘对齐
1、约束布局ConstraintLayout
1、介绍
约束布局ConstraintLayout 是一个ViewGroup,可以在Api9以上的Android系统使用它,它的出现主要是为了解决布局嵌套过多的问题,以灵活的方式定位和调整小部件。从 Android Studio 2.3 起,官方的模板默认使用 ConstraintLayout。
2、为什么要用ConstraintLayout
在开发过程中经常能遇到一些复杂的UI,可能会出现布局嵌套过多的问题,嵌套得越多,设备绘制视图所需的时间和计算功耗也就越多。简单举个例子:

假设现在要写一个这样的布局,可能有人会这么写:
首先是一个垂直的LinearLayout,里面放两个水平的LinearLayout,然后在水平的LinearLayout里面放TextView。这样的写法就嵌套了两层LinearLayout。

有些人考虑到了嵌套布局带来的风险,所以用一个RelativeLayout来装下所有的控件。那么问题来了,既然用RelativeLayout可以解决问题,为什么还要使用ConstraintLayout呢?因为ConstraintLayout使用起来比RelativeLayout更灵活,性能更出色!还有一点就是ConstraintLayout可以按照比例约束控件位置和尺寸,能够更好地适配屏幕大小不同的机型。
3.如何使用ConstraintLayout
3.1 添加依赖
首先我们需要在app/build.gradle文件中添加ConstraintLayout的依赖,如下所示。
1 | implementation 'com.android.support.constraint:constraint-layout:1.1.3' |
3.2 相对定位
相对定位是部件对于另一个位置的约束,这么说可能有点抽象,举个例子:
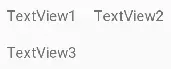
如图所示,TextView2在TextView1的右边,TextView3在TextView1的下面,这个时候在布局文件里面应该这样写:
1 | <TextView |
上面代码中在TextView2里用到了app:layout_constraintLeft_toRightOf=”@+id/TextView1”这个属性,他的意思是把TextView2的左边约束到TextView1的右边,如下图所示:

同理TextView3在TextView1的下面,就需要用到app:layout_constraintTop_toBottomOf=”@+id/TextView1”,即把TextView3的上面约束到TextView1的下面。
下面来看看相对定位的常用属性:
- layout_constraintLeft_toLeftOf
- layout_constraintLeft_toRightOf
- layout_constraintRight_toLeftOf
- layout_constraintRight_toRightOf
- layout_constraintTop_toTopOf
- layout_constraintTop_toBottomOf
- layout_constraintBottom_toTopOf
- layout_constraintBottom_toBottomOf
- layout_constraintBaseline_toBaselineOf
- layout_constraintStart_toEndOf
- layout_constraintStart_toStartOf
- layout_constraintEnd_toStartOf
- layout_constraintEnd_toEndOf
上面属性中有一个比较有趣的layout_constraintBaseline_toBaselineOf
Baseline指的是文本基线,举个例子:
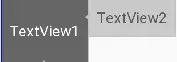
如图所示,两个TextView的高度不一致,但是又希望他们文本对齐,这个时候就可以使用layout_constraintBaseline_toBaselineOf,代码如下:
1 | <TextView |
效果如下:

ConstraintLayout相对定位的用法跟RelativeLayout还是比较相似的,下面用一个图来总结相对定位:
3.3 角度定位
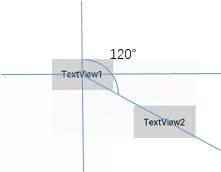
角度定位指的是可以用一个角度和一个距离来约束两个空间的中心。举个例子:
1 | <TextView |
上面例子中的TextView2用到了3个属性:
app:layout_constraintCircle=”@+id/TextView1”
app:layout_constraintCircleAngle=”120”(角度)
app:layout_constraintCircleRadius=”150dp”(距离)
指的是TextView2的中心在TextView1的中心的120度,距离为150dp,效果如下:
3.4 边距
- 3.4.1 常用margin
ConstraintLayout的边距常用属性如下:
android:layout_marginStart
android:layout_marginEnd
android:layout_marginLeft
android:layout_marginTop
android:layout_marginRight
android:layout_marginBottom
看起来跟别的布局没有什么差别,但实际上控件在ConstraintLayout里面要实现margin,必须先约束该控件在ConstraintLayout里的位置,举个例子:
1 | <android.support.constraint.ConstraintLayout |
如果在别的布局里,TextView1的位置应该是距离边框的左边和上面有一个10dp的边距,但是在ConstraintLayout里,是不生效的,因为没有约束TextView1在布局里的位置。正确的写法如下:
1 | <android.support.constraint.ConstraintLayout |
把TextView1的左边和上边约束到parent的左边和上边,这样margin就会生效,效果如下:

在使用margin的时候要注意两点:
控件必须在布局里约束一个相对位置
margin只能大于等于0
- 3.4.2 goneMargin
goneMargin主要用于约束的控件可见性被设置为gone的时候使用的margin值,属性如下:
layout_goneMarginStart
layout_goneMarginEnd
layout_goneMarginLeft
layout_goneMarginTop
layout_goneMarginRight
layout_goneMarginBottom
举个例子:
假设TextView2的左边约束在TextView1的右边,并给TextView2设一个app:layout_goneMarginLeft=”10dp”,代码如下:
1 | <android.support.constraint.ConstraintLayout |
效果如下,TextView2在TextView1的右边,且没有边距。

这个时候把TextView1的可见性设为gone,效果如下:
TextView1消失后,TextView2有一个距离左边10dp的边距。
3.5 居中和偏移
在RelativeLayout中,把控件放在布局中间的方法是把layout_centerInParent设为true,而在ConstraintLayout中的写法是:
1 | app:layout_constraintBottom_toBottomOf="parent" |
意思是把控件的上下左右约束在布局的上下左右,这样就能把控件放在布局的中间了。同理RelativeLayout中的水平居中layout_centerHorizontal相当于在ConstraintLayout约束控件的左右为parent的左右;RelativeLayout中的垂直居中layout_centerVertical相当于在ConstraintLayout约束控件的上下为parent的上下。
由于ConstraintLayout中的居中已经为控件约束了一个相对位置,所以可以使用margin,如下所示:
1 | <TextView |
效果如下:

上面TextView1在水平居中后使用layout_marginLeft=”100dp”向右偏移了100dp。除了这种偏移外,ConstraintLayout还提供了另外一种偏移的属性:
layout_constraintHorizontal_bias 水平偏移
layout_constraintVertical_bias 垂直偏移
举个例子:
1 | <TextView |
效果如下:

假如现在要实现水平偏移,给TextView1的layout_constraintHorizontal_bias赋一个范围为 0-1 的值,假如赋值为0,则TextView1在布局的最左侧,假如赋值为1,则TextView1在布局的最右侧,假如假如赋值为0.5,则水平居中,假如假如赋值为0.3,则更倾向于左侧。
垂直偏移同理。
3.6 尺寸约束
控件的尺寸可以通过四种不同方式指定:
- 使用指定的尺寸
- 使用wrap_content,让控件自己计算大小
当控件的高度或宽度为wrap_content时,可以使用下列属性来控制最大、最小的高度或宽度:
android:minWidth 最小的宽度
android:minHeight 最小的高度
android:maxWidth 最大的宽度
android:maxHeight 最大的高度
注意!当ConstraintLayout为1.1版本以下时,使用这些属性需要加上强制约束,如下所示:
app:constrainedWidth=”true”
app:constrainedHeight=”true” - 使用 0dp (MATCH_CONSTRAINT)
官方不推荐在ConstraintLayout中使用match_parent,可以设置 0dp (MATCH_CONSTRAINT) 配合约束代替match_parent,举个例子:
1 | <TextView |
宽度设为0dp,左右两边约束parent的左右两边,并设置左边边距为50dp,效果如下:

- 宽高比
当宽或高至少有一个尺寸被设置为0dp时,可以通过属性layout_constraintDimensionRatio设置宽高比,举个例子:
1 | <TextView |
宽设置为0dp,宽高比设置为1:1,这个时候TextView1是一个正方形,效果如下:

除此之外,在设置宽高比的值的时候,还可以在前面加W或H,分别指定宽度或高度限制。 例如:
app:layout_constraintDimensionRatio=”H,2:3”指的是 高:宽=2:3
app:layout_constraintDimensionRatio=”W,2:3”指的是 宽:高=2:3
3.7 链
如果两个或以上控件通过下图的方式约束在一起,就可以认为是他们是一条链(图为横向的链,纵向同理)。
用代码表示:
1 | <TextView |
3个TextView相互约束,两端两个TextView分别与parent约束,成为一条链,效果如下:

一条链的第一个控件是这条链的链头,我们可以在链头中设置 layout_constraintHorizontal_chainStyle来改变整条链的样式。chains提供了3种样式,分别是:
CHAIN_SPREAD —— 展开元素 (默认);
CHAIN_SPREAD_INSIDE —— 展开元素,但链的两端贴近parent;
CHAIN_PACKED —— 链的元素将被打包在一起。
如图所示:

上面的例子创建了一个样式链,除了样式链外,还可以创建一个权重链。
可以留意到上面所用到的3个TextView宽度都为wrap_content,如果我们把宽度都设为0dp,这个时候可以在每个TextView中设置横向权重layout_constraintHorizontal_weight(constraintVertical为纵向)来创建一个权重链,如下所示:
1 | <TextView |
效果如下:

4.辅助工具
4.1 Optimizer
当我们使用 MATCH_CONSTRAINT 时,ConstraintLayout 将对控件进行 2 次测量,ConstraintLayout在1.1中可以通过设置 layout_optimizationLevel 进行优化,可设置的值有:
none:无优化
standard:仅优化直接约束和屏障约束(默认)
direct:优化直接约束
barrier:优化屏障约束
chain:优化链约束
dimensions:优化尺寸测量
4.2 Barrier
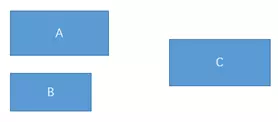
假设有3个控件ABC,C在AB的右边,但是AB的宽是不固定的,这个时候C无论约束在A的右边或者B的右边都不对。当出现这种情况可以用Barrier来解决。Barrier可以在多个控件的一侧建立一个屏障,如下所示:
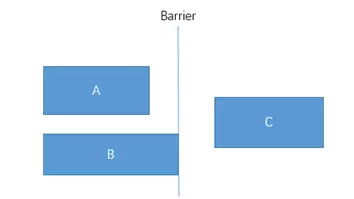
这个时候C只要约束在Barrier的右边就可以了,代码如下:
1 | <TextView |
app:barrierDirection为屏障所在的位置,可设置的值有:bottom、end、left、right、start、top
app:constraint_referenced_ids为屏障引用的控件,可设置多个(用“,”隔开)
4.3 Group
Group可以把多个控件归为一组,方便隐藏或显示一组控件,举个例子:
1 | <TextView |

现在有3个并排的TextView,用Group把TextView1和TextView3归为一组,再设置这组控件的可见性,如下所示:
1 | <android.support.constraint.Group |
效果如下:

4.4 Placeholder
Placeholder指的是占位符。在Placeholder中可使用setContent()设置另一个控件的id,使这个控件移动到占位符的位置。举个例子:
1 | <android.support.constraint.Placeholder |
新建一个Placeholder约束在屏幕的左上角,新建一个TextView约束在屏幕的右上角,在Placeholder中设置 app:content=”@+id/textview”,这时TextView会跑到屏幕的左上角。效果如下:

4.5 Guideline
Guildline像辅助线一样,在预览的时候帮助你完成布局(不会显示在界面上)。
Guildline的主要属性:
android:orientation 垂直vertical,水平horizontal
layout_constraintGuide_begin 开始位置
layout_constraintGuide_end 结束位置
layout_constraintGuide_percent 距离顶部的百分比(orientation = horizontal时则为距离左边)
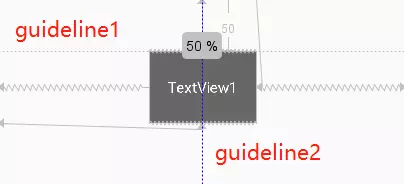
举个例子:
1 | <android.support.constraint.Guideline |
guideline1为水平辅助线,开始位置是距离顶部50dp,guideline2位垂直辅助线,开始位置为屏幕宽的0.5(中点位置),效果如下:
其他文章:https://www.jianshu.com/p/958887ed4f5f
2、AppbarLayout控件
AppbarLayout是Material Design的一个控件,目的是为了实现一些酷炫到爆的效果,比如之前的折叠导航栏可以费劲心血的写出来,现在利用Appbarlayout非常容易的就可以实现出来,当然需要配合其他几个来控件实现。
用法:
实现toolbar的收缩和扩展需要用到:
CoordinatorLayout和AppbarLayout的配合, 以及实现了NestedScrollView的布局或控件.AppbarLayout是一种支持响应滚动手势的app bar布局, CollapsingToolbarLayout则是专门用来实现子布局内不同元素响应滚动细节的布局.
与AppbarLayout组合的滚动布局(RecyclerView, NestedScrollView等),需要设置 app:layout_behavior = “@string/appbar_scrolling_view_behavior” .没有设置的话, AppbarLayout将不会响应滚动布局的滚动事件.
例如:
1 |
|
先看下效果再来解释为什么.
可以看到:
- 随着文本往上滚动, 顶部的toolbar也往上滚动, 直到消失.
- 随着文本往下滚动, 一直滚到文本的第一行露出来, toolbar也逐渐露出来
解释:
从上面的布局中可以看到, 其实在整个父布局CoordinatorLayout下面, 是有2个子布局
- AppbarLayout
- NestedScrollView
NestedScrollView先放一放, 我们来看AppbarLayout.
AppBarLayout 继承自LinearLayout,布局方向为垂直方向。所以你可以把它当成垂直布局的LinearLayout来使用。AppBarLayout是在LinearLayou上加了一些材料设计的概念,它可以让你定制当某个可滚动View的滚动手势发生变化时,其内部的子View实现何种动作。
【CoordinatorLayout允许behavior协调子view】
注意:
上面提到的”某个可滚动View”, 可以理解为某个ScrollView. 就是说,当某个ScrollView发生滚动时,你可以定制你的“顶部栏”应该执行哪些动作(如跟着一起滚动、保持不动等等)。
这里某个ScrollView就是NestedScrollView或者实现了NestedScrollView机制的其它控件, 如RecyclerView. 它有一个布局行为Layout_Behavior:
1 | app:layout_behavior="@string/appbar_scrolling_view_behavior" |
这是一个系统behavior, 从字面意思就可以看到, 是为appbar设置滚动动作的一个behavior. 没有这个属性的话, Appbar就是死的, 有了它就有了灵魂.
我们可以通过给Appbar下的子View添加app:layout_scrollFlags来设置各子View执行的动作. scrollFlags可以设置的动作如下:
(1) scroll: 值设为scroll的View会跟随滚动事件一起发生移动。就是当指定的ScrollView发生滚动时,该View也跟随一起滚动,就好像这个View也是属于这个ScrollView一样。
上面这个效果就是设置了scroll之后的.
(2) enterAlways: 值设为enterAlways的View,当任何时候ScrollView往下滚动时,该View会直接往下滚动。而不用考虑ScrollView是否在滚动到最顶部还是哪里.
我们把layout_scrollFlags改动如下:
1 | app:layout_scrollFlags="scroll|enterAlways" |
效果如下:

(3) exitUntilCollapsed:值设为exitUntilCollapsed的View,当这个View要往上逐渐“消逝”时,会一直往上滑动,直到剩下的的高度达到它的最小高度后,再响应ScrollView的内部滑动事件。
怎么理解呢?简单解释:在ScrollView往上滑动时,首先是View把滑动事件“夺走”,由View去执行滑动,直到滑动最小高度后,把这个滑动事件“还”回去,让ScrollView内部去上滑。
把属性改下再看效果
1 | <android.support.v7.widget.Toolbar |
(4) enterAlwaysCollapsed:是enterAlways的附加选项,一般跟enterAlways一起使用,它是指,View在往下“出现”的时候,首先是enterAlways效果,当View的高度达到最小高度时,View就暂时不去往下滚动,直到ScrollView滑动到顶部不再滑动时,View再继续往下滑动,直到滑到View的顶部结束
这个得把高度加大点才好实验. 来看:
1 | <android.support.v7.widget.Toolbar |
Attention:
其实toolbar的默认最小高度minHeight就是"?attr/actionBarSize" , 很多时候可以不用设置. 而且从图上可以看出, 其实这里有个缺陷, 就是title的位置和toolbar上的图标行脱离了, 即使在布局里添加了 android:gravity="bottom|start", 在toolbar滚动的时候, title还在, 图标滚动到隐藏了.
后面讲解的CollapsingToolbarLayout可以解决这个问题, 这里先丢出来.
(5) snap:简单理解,就是Child View滚动比例的一个吸附效果。也就是说,Child View不会存在局部显示的情况,滚动Child View的部分高度,当我们松开手指时,Child View要么向上全部滚出屏幕,要么向下全部滚进屏幕,有点类似ViewPager的左右滑动
引入CollapsingToolbarLayout
CollapsingToolbarLayout是用来对Toolbar进行再次包装的ViewGroup,主要是用于实现折叠(其实就是看起来像伸缩)的App Bar效果。它需要放在。CollapsingToolbarLayout主要包括几个功能(参照了官方网站上内容,略加自己的理解进行解释):AppBarLayout布局里面,并且作为AppBarLayout的直接子
(1) 折叠Title(Collapsing title):当布局内容全部显示出来时,title是最大的,但是随着View逐步移出屏幕顶部,title变得越来越小。你可以通过调用setTitle方法来设置title。
(2)内容纱布(Content scrim):根据滚动的位置是否到达一个阀值,来决定是否对View“盖上纱布”。可以通过setContentScrim(Drawable)来设置纱布的图片. 默认contentScrim是colorPrimary的色值
(3)状态栏纱布(Status bar scrim):根据滚动位置是否到达一个阀值决定是否对状态栏“盖上纱布”,你可以通过setStatusBarScrim(Drawable)来设置纱布图片,但是只能在LOLLIPOP设备上面有作用。默认statusBarScrim是colorPrimaryDark的色值.
(4)视差滚动子View(Parallax scrolling children): 子View可以选择在当前的布局当时是否以“视差”的方式来跟随滚动。(PS:其实就是让这个View的滚动的速度比其他正常滚动的View速度稍微慢一点)。将布局参数app:layout_collapseMode设为parallax
(5)将子View位置固定(Pinned position children):子View可以选择是否在全局空间上固定位置,这对于Toolbar来说非常有用,因为当布局在移动时,可以将Toolbar固定位置而不受移动的影响。 将app:layout_collapseMode设为pin。
我们来更改一下布局:
1 |
|
可以看到, 我们把原本属于toolbar的几个属性移到了CollapsingToolbarLayout上. 分别是:
1 | android:theme="@style/ThemeOverlay.AppCompat.Dark.ActionBar" |
同时给toolbar增加了一个折叠模式属性
1 | app:layout_collapseMode="parallax" |
我们来看下效果:
嗯嗯, 折叠模式不对, toolbar的顶部图标没了. 我们改下折叠模式:
1 | app:layout_collapseMode="pin" |
再看效果:
我们把scrollFlags属性改下, 看下对比:
1 | app:layout_scrollFlags="scroll|enterAlways|enterAlwaysCollapsed" |
效果还是蛮不错的, 有了点Google Material Design的感觉了.
上面说CollapsingToolbarLayout是个ViewGroup, 那么肯定还可以添加控件. 那么我们在里面添加一个ImageView来看看. 更改布局如下:
1 |
|
来看下效果:
嗯, 有了点意思, 但不美观, 上部的toolbar和图片不协调. toolbar应该有默认的背景属性, 我们去掉它看看.
1 | <android.support.v7.widget.Toolbar |
再看下效果:
这次真的不错哦, 已经和很多大公司的app相像了. 但是为什么去掉toolbar的background就可以得到透明背景呢? 说句实话, 没找到原因.
不过我们没有给CollapsingToolbarLayout设置contentScrim属性哦, 给它加个属性看看.
1 | <android.support.design.widget.CollapsingToolbarLayout |
嗯嗯, 好像还不如没设置这个属性好呢.
什么时候需要contentScrim属性呢?
因为这个布局里面给CollapsingToolbarLayout的layout_scrollFlags设置的是 "scroll|enterAlways|enterAlwaysCollapsed" , toolbar会全部消失的, 所以感觉不是很美观. 如果将layout_scrollFlags属性改为 “scroll|exitUntilCollapsed” , 效果会好点, 适合toolbar还是需要展示的场合.
不管怎么样, 先去掉contentScrim属性吧.
目前有很多APP比较喜欢采用沉浸式设计, 简单点说就是将状态栏和导航栏都设置成透明或半透明的.
我们来把状态栏statusBar设置成透明. 在style主题中的AppTheme里增加一条:
1 | <style name="AppTheme" parent="Theme.AppCompat.Light.NoActionBar"> |
在布局里面, 将ImageView和所有它上面的父View都添加fitsSystemWindows属性.
1 |
|
最后来看下效果:
其实还可以在CollapsingToolbarLayout里设置statusBarScrim为透明色, 不过有点问题, 最顶部的toolbar没有完全隐藏, 还留了一点尾巴.
难道就这个属性就没用吗? 我们把layout_scrollFlags改成 “scroll|exitUntilCollapsed” 看看:
这个时候toolbar不用隐藏, 所以还是美美的.
AppbarLayout整个做成沉浸式之后, 状态栏的图标可能会受到封面图片颜色过浅的影响, 可以给其加一个渐变的不透明层.
渐变遮罩设置方法:
在res/drawable文件夹下新建一个名为status_gradient的xml资源文件, 代码如下:
1 |
|
布局中, 在ImageView下面增加一个View, 背景设为上面的渐变遮罩.
1 | <!-- 在顶部增加一个渐变遮罩, 防止出现status bar 状态栏看不清 --> |
给遮罩设置折叠模式: app:layout_collapseMode=”pin” , 折叠到顶部后定住. 来看下效果.

上图是展开状态的对比, 后面的是没有添加遮罩的效果, 前面是添加了遮罩的效果. 下图是添加了遮罩折叠后的效果. 有点黑暗系影片的感觉哦.
FloatingActionButton再次表演
作为Google Material Design的一个重要控件, FloatingActionButton怎么可能不在AppbarLayout中起点作用呢. 我们在布局中加一个悬浮按钮, 让它的锚点挂载Appbar的右下角. 这样这个悬浮按钮就和Appbar关联起来了.
1 | <android.support.design.widget.CoordinatorLayout |
我们来看下效果.
好吧, 美美的Toolbar完成了, 有点Google Material Design扑面而来的感觉了
使用FloatingActionButton其实非常简单只需要在布局文件中引入控件即可,不过它的属性有点多,我们先来介绍一下它的属性。
- android:src:FAB中显示的图标.
- app:backgroundTint:正常的背景颜色 ,这里是ColorStateList类型
- app:rippleColor:按下时的背景颜色
- app:elevation:正常的阴影大小
- app:pressedTranslationZ:按下时的阴影大小
- app:layout_anchor:设置FAB的锚点,即以哪个控件为参照设置位置
- app:layout_anchorGravity:FAB相对于锚点的位置
- app:fabSize:FAB的大小,normal或mini(分别对应56dp和40dp)
- app:borderWidth:边框大小,最好设置成0dp否则会有边框
- android:clickable:一定要设置成true否则没有点击效果
其他方法介绍
addOnOffsetChangedListener当AppbarLayout 的偏移发生改变的时候回调,也就是子View滑动。
getTotalScrollRange返回AppbarLayout 所有子View的滑动范围
removeOnOffsetChangedListener移除监听器
**setExpanded (boolean expanded, boolean animate)**设置AppbarLayout 是展开状态还是折叠状态,animate 参数控制切换到新的状态时是否需要动画
**setExpanded (boolean expanded)**设置AppbarLayout 是展开状态还是折叠状态,默认有动画
但看解释好像不明白,我们详细来看一下这几个方法
1,addOnOffsetChangedListener
这是官方的解释,其实很明白了
Called when theAppBarLayout’s layout offset has been changed. This allows child views to implement custom behavior based on the offset (for instance pinning a view at a certain y value).
在AppBarLayout的布局偏移量发生改变时被调用。这个方法允许子view根据偏移量实现自定义的行为(比如在特定Y值的时候固定住一个View)
下面来举个例子来看一下这个方法能作甚们
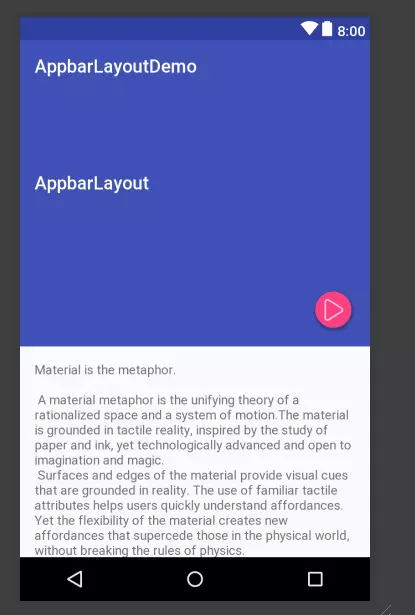
如图我们搞一个这个样子的布局
布局:
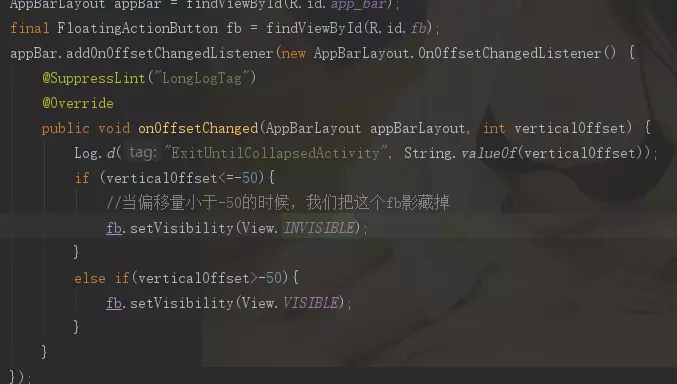
java代码:
日志:
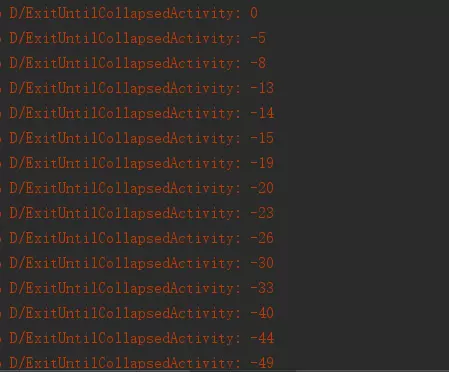
可见当appbarlayout最大的时候偏移量为0,网上滑动的时候,偏移量向负数方向增大,下面是效果图,只是展示了可以做的一些事情,实际项目中可以根据偏移量随意操作,比如可以做个透明度的动画等等
效果图:
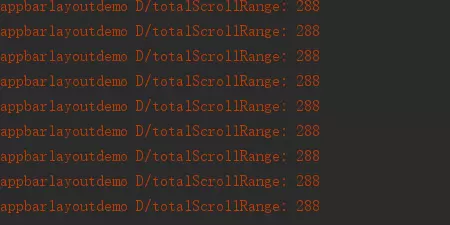
2,getTotalScrollRange,这个方法返货的是一个滑动的范围,也可以理解为党appbarlayout滑动到最小值时候的一个值得绝对值,这个值是不变的,是以appbarlayout为基础的其所有子view的一个范围值,如下,我们在addOnOffsetChangedListener方法中加入以下代码,然后滑动得到的值全都是288。有这个方法,我们可以在addOnOffsetChangedListener方法中做什么事情之前做一个精准的判断。

3,removeOnOffsetChangedListener ,移除监听器,这个没什么好说的,移除掉偏移量监听,某些情况下,你可能需要根据偏移量做些神门事情,但是某些情况下,你有不想做神门,所以只好把他移除掉。
4,setExpanded (boolean expanded, boolean animate)设置AppbarLayout 是展开状态还是折叠状态,animate 参数控制切换到新的状态时是否需要动画
setExpanded (boolean expanded)设置AppbarLayout 是展开状态还是折叠状态,默认有动画
这俩个方法,就像他的解释一样

false为关闭状态,true为展开状态
打开时的状态:

CollapsingToolbarLayout
CollapsingToolbarLayout是对子view的包装,并且实现了折叠app bar效果,使用时,要作为 AppbarLayout 的直接子View。
1,Collapsing title(折叠标题)当布局全部可见的时候,title 是最大的,当布局开始滑出屏幕,title 将变得越来越小,你可以通过setTitle(CharSequence) 来设置要显示的标题。
注意:Toolbar 和CollapsingToolbarLayout 同时设置了title时,不会显示Toolbartitle而是显示CollapsingToolbarLayout 的title,如果要显示Toolbar 的title,你可一在代码中添加如下代码:
collapsingToolbarLayout.setTitle(“”)
注意:你得给CollapsingToolbarLayout设置一个值,你来个wrap_parent是不起作用的,或者你把toolbar设置一个值来撑大CollapsingToolbarLayout也是不可以的
布局:
效果图:

2,Content scrim(内容纱布)当CollapsingToolbarLayout滑动到一个确定的阀值时将显示或者隐藏内容纱布,可以通过setContentScrim(Drawable)来设置纱布的图片。
布局:
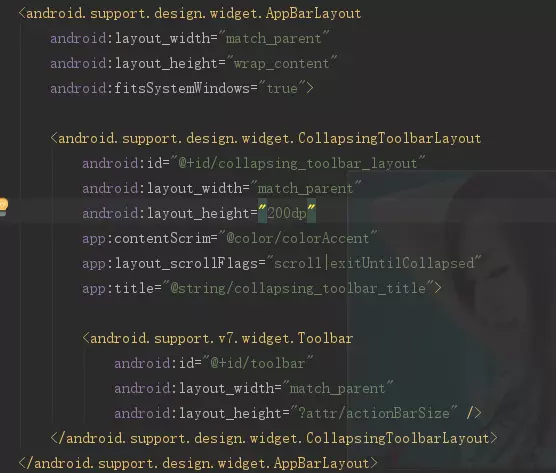
效果图:

3,Status bar scrim(状态栏纱布)当CollapsingToolbarLayout滑动到一个确定的阀值时,状态栏显示或隐藏纱布,你可以通过setStatusBarScrim(Drawable)来设置纱布图片。
4,Pinned position children(固定子View的位置)子View可以固定在全局空间内,这对于实现了折叠并且允许通过滚动布局来固定Toolbar 这种情况非常有用。在xml 中将collapseMode设为pin
布局:
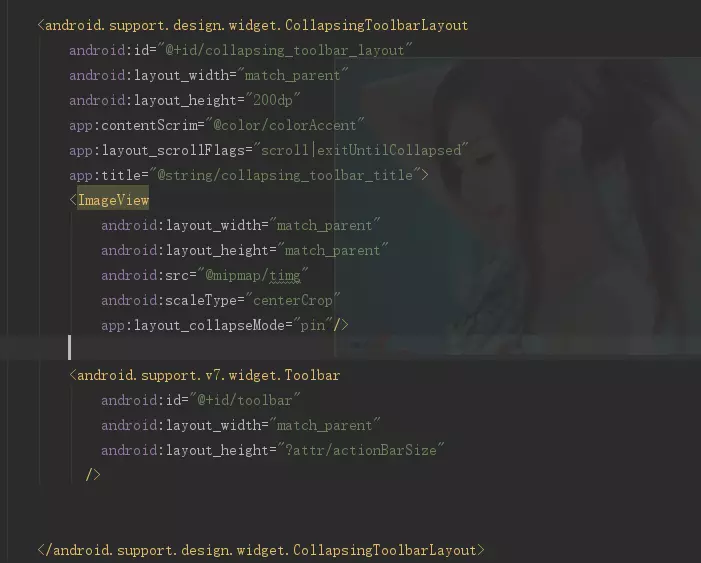
效果图:

5,Parallax scrolling children(有视差地滚动子View)让CollapsingToolbarLayout 的子View 可以有视差的滚动,需要在xml中用 添加如下代码:
app:layout_collapseMode=”parallax”
注意:app:layout_collapseParallaxMultiplier=”0.7” 这个参数是设置视差范围的,0-1,越大视差越大
布局:
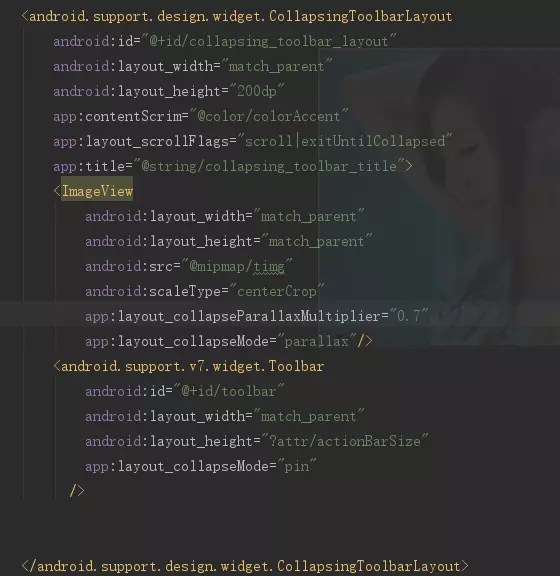
效果图:

以上就是appbarlayout的全部特点,在项目中使用几次就会了,各种scrollFlag与CollapsingToolbarLayout的搭配使用,可以做出很多非常酷炫的效果,基本满足各种需求,如果设计师太鬼畜,那么打她,打她,打她!!!!!!! 打不过?请用behavior,behavior,.behavior!!!
3、DrawerLayout抽屉布局
参照:https://blog.csdn.net/crazy1235/article/details/41696291
1、介绍
导航抽屉显示在屏幕的最左侧,默认情况下是隐藏的,当用户用手指从边缘向另一个滑动的时候,会出现一个隐藏的面板,当点击面板外部或者向原来的方向滑动的时候,抽屉导航就会消失了!
好了,这个抽屉就是DrawerLayout,该类位于V4包中。android.support.v4.widget.DrawerLayout.
2、使用
抽屉导航的实现步骤非常简单。只要配置好带有抽屉导航的布局就可以实现简单的策划菜单。布局代码如下:
1 | <android.support.v4.widget.DrawerLayout xmlns:android="http://schemas.android.com/apk/res/android" |
说明:
- 必须把DrawerLayout作为布局的跟标签。
- 然后在跟标签中添加一个包含内容的视图,就是当抽屉完全隐藏的时候显示的内容布局。
- 添加一个抽屉布局,这个布局可以按照需求自己定义,我的demo中是一个listview。
- 抽屉布局中,需要指定
android:layout_gravity属性,官方说明是用start代替left。不过我试了一下start和left,right和end的效果是一样的。知道是什么区别?(谁知道,请留言告知一下!谢谢!) - 抽屉布局的宽度最好不要超过320dp,这样做为了当抽屉完全显示的时候,不至于把内容布局全部遮挡。
好了,此时在你的activity中设置一下布局文件,就可以实现一个简单的侧滑菜单了,不过菜单是在上面的。

初始化listview
接下来,就要初始化listview了。
1 | mLv = (ListView) findViewById(R.id.id_lv); |
下面,设置抽屉导航的监听事件。添加监听器的时候有三种方式。
1、设置DrawerLayout.DrawerListener作为监听器类,里面包含四个回调函数。
代码如下:
1 | mDrawerLayout.setDrawerListener(new DrawerListener() { |
2、设置DrawerListener的子类SimpleDrawerListener,使用这个类的时候不必实现全部的回调函数,可以根据自己的需要重写相应的方法。
代码如下:
1 | mDrawerLayout.setDrawerListener(new DrawerLayout.SimpleDrawerListener() { |
3、使用DrawerListener的子类ActionBarDrawerToggle。一般与ActionBar结合使用。
代码如下:
1 | mDrawerToggle = new ActionBarDrawerToggle(this, mDrawerLayout, |
DrawerLayout和NavigationView使用(重点)
(一)基本使用
DrawerLayout界面
1 |
|
可以看到我们的最外层是DrawerLayout,包含了两个内容:include为显示内容区域,NavigationView为侧边抽屉栏。
NavigationView有两个app属性,分别为app:headerLayout和app:menu,headerLayout用于显示头部的布局(可选),menu用于建立MenuItem选项的菜单。
headerLayout就是正常的layout布局文件,我们查看下menu.xml
1 |
|
menu可以分组,group的android:checkableBehavior属性设置为single可以设置该组为单选
Activity主题必须设置先这两个属性
1 | <style name="AppTheme.NoActionBar"> |
未设置Activity主题会爆出错误信息:
1 | vCaused by: java.lang.IllegalStateException: This Activity |
设置主题为android:theme=”@style/AppTheme.NoActionBar”
效果图:

(二)、监听和关闭NavigationView
NavigationView监听通过navigationView.setNavigationItemSelectedListener(this)方法去监听menu的点击事件
1 |
|
每次点击一个Menu关闭DrawerLayout,方法为drawer.closeDrawer(GravityCompat.START);
通过onBackPressed方法,当点击返回按钮的时候,如果DrawerLayout是打开状态则关闭
1 |
|
(三)、NavigationView在Toolbar下方
大多数的APP都是使用NavigationView都是全屏的,当我们想让NavigationView在Toolbar下方的时候应该怎么做呢
xml布局如下图,DrawerLayout在Toolbar的下方
1 | <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" |
效果如图:
NavigationView在Toolbar下方.gif
(四)、Toolbar上不显示Home旋转开关按钮
上图可以看到我们点击Home旋转开关按钮,显示和隐藏了侧滑菜单。那么如果我们想要不通过按钮点击,只能右划拉出菜单需要怎么做呢。
我们先看下带Home旋转开关按钮的代码是如何写的:
1 | DrawerLayout drawer = (DrawerLayout) findViewById(R.id.drawer_layout); |
这个Home旋转开关按钮实际上是通过ActionBarDrawerToggle代码绑定到toolbar上的,ActionBarDrawerToggle是和DrawerLayout搭配使用的,它可以改变android.R.id.home返回图标,监听drawer的显示和隐藏。ActionBarDrawerToggle的syncState()方法会和Toolbar关联,将图标放入到Toolbar上。
进入ActionBarDrawerToggle构造器可以看到一个不传Toolbar参数的构造器
1 | public ActionBarDrawerToggle(Activity activity, DrawerLayout drawerLayout, |
那么不带Home旋转开关按钮的代码如下
1 | //这是不带Home旋转开关按钮 |
当然我们把上面带Home旋转开关按钮的代码删除也是可以的。
效果如图:
Toolbar上不显示Home旋转开关按钮.gif
(五)、不使用NavigationView,使用DrawerLayout+其他布局
APP实际开发中往往不能完全按照Materialdesign的规则来,如网易云音乐的侧滑,底部还有两个按钮。这时候我们可以通过+其他布局来实现特殊的侧滑布局。
我们可以参考鸿杨大神的博客
[Android 自己实现 NavigationView Design Support Library(1)]
我们自己实现个简单的,DrawerLayout包裹了一个FrameLayout和一个RelativeLayout,FrameLayout是我们的显示内容区域,RelativeLayout是我们的侧边栏布局。
1 | <android.support.v4.widget.DrawerLayout |
如果需要监听DrawerLayout的侧滑状态监听,那么代码如下:
1 | mDrawerLayout = (DrawerLayout) findViewById(R.id.drawer_layout); |
效果图如下:

ActionBarDrawerToggle
ActionBarDrawerToggle 是 DrawerLayout.DrawerListener实现。和 NavigationDrawer 搭配使用,推荐用这个方法,符合Android design规范。
作用:
1.改变android.R.id.home返回图标。
2.Drawer拉出、隐藏,带有android.R.id.home动画效果。
3.监听Drawer拉出、隐藏;
ActionBarDrawerToggle 是在actionBar监视DrawerLayout的状态变化
所以不要设置activity为无标题:
1 | //requestWindowFeature(Window.FEATURE_NO_TITLE); |
实现:
绑定DrawerLayout,
设置DrawLayout切换按钮R.drawable.ic_drawer
实现两个方法:
onDrawerClosed
onDrawerOpened
监视抽屉的打开和关闭。
1 | /** |
必须注意ActionBarDrawerToggle的使用必须在
onPostCreate() and onConfigurationChanged()之间
1 | /** |
更详细的例子
1 | ActionBarDrawerToggle 是 DrawerLayout.DrawerListener 实现。和 NavigationDrawer 搭配使用,推荐用这个方法,符合Android design规范。 |
demo:
效果图:

布局文件最外层使用DrawerLayout
只可以有两个子布局
1 |
|
NavigationView
NavigationView侧滑菜单,可以自行填充头部布局和菜单布局,还可以再添加任意布局
在需要使用的页面添加如下代码
1 | public class HomeActivity extends BaseActivity { |
4、CoordinatorLayout
Broadcast
广播机制简介
Android的广播机制非常灵活,Android的每一个应用程序都可以对自己感兴趣的广播进行注册,这样该程序就只会接收到自己所关心的广播内容,这些广播可能是来自系统的,也可能是来自于其他应用程序的。
Android提供了一套完整的API,允许应用程序自由地发送和接收广播。发送广播借助Intent,而接收广播的方法利用广播接收器Broadcast Receiver。
广播(Broadcast)机制用于进程/线程间通信,因此在我们应用程序内发出的广播,其他的应用程序应该也是可以收到的。广播分为广播发送和广播接收两个过程,其中广播接收者BroadcastReceiver便是Android四大组件之一。
BroadcastReceiver分为两类:
- 静态广播接收者:通过AndroidManifest.xml的标签来申明的BroadcastReceiver。
- 动态广播接收者:通过AMS.registerReceiver()方式注册的BroadcastReceiver,动态注册更为灵活,可在不需要时通过unregisterReceiver()取消注册。
从广播发送方式可分为三类:
- 普通广播:通过Context.sendBroadcast()发送,可并行处理
- 有序广播:通过Context.sendOrderedBroadcast()发送,串行处理
- Sticky广播:通过Context.sendStickyBroadcast()发送
广播的分类
按照发送的方式分类
标准广播
一种完全异步执行的广播。在广播发出之后,所有的广播接收器几乎都会在同一时刻接收到这条广播信息,因此他们之间没有任何先后顺序可言。这种广播的效率会比较高,但同时也意味着它是无法被截断的。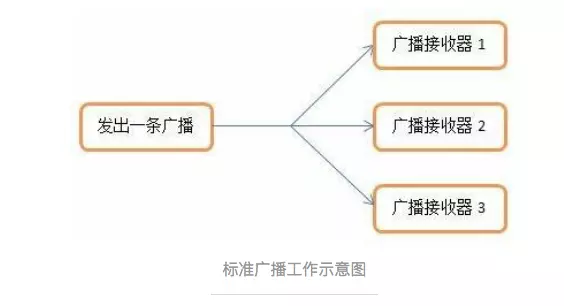
发送标准广播(异步,无序)
1 | sendBroadcast(intent); |
有序广播
一种同步执行的广播,在广播发出之后,同一时刻只会有一个广播接收器能够收到这条广播信息,当这个广播接收器中的逻辑执行完毕后,广播才会继续传递。此时的广播是有先后顺序的,优先级别高的广播接收器就可以先收到广播信息,并且前面的广播接收器还可以截断正在传递的广播,这样后面的广播接收器就无法收到广播信息了。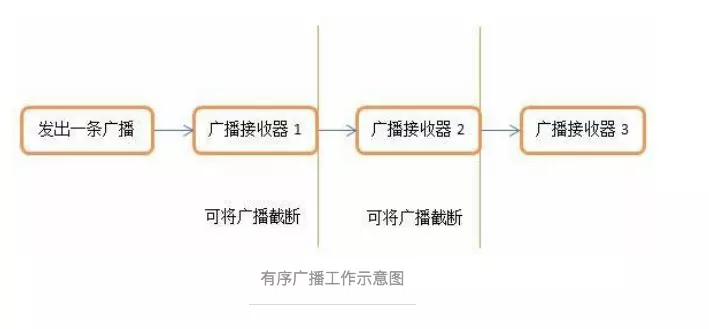
发送有序广播(同步,有序)
1 | sendOrderedBroadcast(intent,null); |
按照注册的方式分类
动态注册广播
顾名思义,就是在代码中注册的。
静态注册广播
动态注册要求程序必须在运行时才能进行,有一定的局限性,如果我们需要在程序还没启动的时候就可以接收到注册的广播,就需要静态注册了。主要是在AndroidManifest中进行注册。
按照定义的方式分类
系统广播
Android系统中内置了多个系统广播,每个系统广播都具有特定的intent-filter,其中主要包括具体的action,系统广播发出后,将被相应的BroadcastReceiver接收。系统广播在系统内部当特定事件发生时,由系统自动发出。
自定义广播
由应用程序开发者自己定义的广播
标准广播
有序广播
接收系统广播
Android 内置了很多系统级别的广播,我们可以在应用程序中通过监听这些广播来得到各种系统的状态信息。比如手机开机完成后会发出一条广播,电池的电量发生变化会发出一条广播,时间或时区发生改变也会发出一条广播等。而想要接收到这些广播,需要使用广播接收器。
实现一个广播接收器
1 | public class MyBroadcastReceiver extends BroadcastReceiver { |
主要就是继承一个BroadcastReceiver,重写onReceive方法,当有广播来的时候,onReceive()方法就会得到执行。在其中实现自己的业务逻辑就可以了。
动态注册监听网络变化
动态注册:代码中注册。
动态注册:调用Context的registerReceiver函数注册BroadcastReceiver; 当应用程序不再需要监听广播时,则需要调用unregisterReceiver函数进行反注册
静态注册:AndroidManifest.xml注册
例如:
1 | public class MainActivity extends AppCompatActivity { |
- 创建广播过滤器 new IntentFilter() ,添加一个值为android.net.conn.CONNECTIVIT_CHANGE的action,之所以添加这个值,是因为当网络状态发生变化的时候,系统发出的正是一条值为android.net.conn.CONNECTIVITY_CHANGE的广播。
- 创建广播接收者NetworkChangeReceiver,并重写onReceive方法,每当网络状态发生变化的时候,onReceive方法就会得到执行,这里只是简单地使用Toast提示一段文本信息。
- 调用registerReceiver方法进行注册,将广播接收者和过滤者的实例都传进去,就可以监听网络变化的状态了。
- 动态注册的广播接收器一定要取消注册才行:在onDestory()方法中调用ungisterReceiver()方法来实现。
- 首先注册完成的时候会收到一条广播,然后修改下网络状态,又会受到一条广播,就 Toast提醒网络状态发生了变化。
注意事项
1. 发送异步广播(标准广播,无序) 使用sendBroadcast(intent)方法; 而发送同步广播(有序广播) 使用sendOrderedBroadcast(intent,null)方法;
2. 动态注册的广播接收器一定都要取消注册才行,这里我们是在 onDestroy()方法中通过调用unregisterReceiver()方法来实现的。
3. 动态注册 的广播接收器可以自由地控制注册与注销,在灵活性方面有很大的优势,但它也存在着一个缺点,即必须要在程序启动之后才能接收到广播,因为注册的逻辑是写在 onCreate()方法中的。
只是提醒网络是否发生变化并不太人性化,还要准确地告诉用户当前是有网络还是没有网络,因此我们还需要对上面的代码进行优化,修改onReceive中的代码:
1 | class NetworkChangeReceiver extends BroadcastReceiver { |
- 在onReceive方法中,首先通过getSystemService方法得到ConnectivityManager的实例,这是系统服务类,专门用于管理网络连接的。
- ==然后调用它的getActiveNetworkInfo方法可以得到NetworkInfor实例==。
- 接着调用NetworkInfo的isAvailable方法,就可以判断出当前是否有网络了。
- 添加访问网络状态的权限(6.0就要动态注册了,后面讲):
1 | <uses-permission android:name="android.permission.ACCESS_NETWORK_STATE" /> |
静态注册实现开机启动
动态注册的广播接收器虽然可以自由地控制注册和注销,但是必须在程序启动之后才能接收到广播。如果想让程序在未启动的情况下就能接收到广播,就需要静态注册了。现在我们让程序接收一条开机广播,当收到这个条广播时就可以在onReceive()方法里执行相应的逻辑,从而实现开机启动的功能。
在程序包->New—>Other->Broadcast Receiver新建广播接收器,可选 Exported属性表示是否允许这个广播接收器接收本程序以外的广播,Enabled属性表示是否启用这个广播接收器。
新建的广播接收器,会由Android Studio自动帮你在AndroidManifest中注册。
代码:
1 | <manifest xmlns:android="http://schemas.android.com/apk/res/android" |
静态的广播接收器一定要在AndroidManifest.xml中注册才可以使用,不过由于先前是使用AS快捷方式创建的广播接收器,因此注册这一步已经被自动完成了。会发现application标签内多了如下代码:
1 | <receiver |
说明:在标签内出现了一个新的标签,所有静态的广播接收器都是在这里进行注册的。它的用法其实和标签很相似,都是通过android:name来指定具体注册哪一个广播接收器,而 enaled和exported属性则是根据我们刚才勾选的状态自动生成的。
1 | <receiver |
几个相关解释:
android:exported
此BroadcastReceiver能否接收其他App发出的广播(其默认值是由receiver中有无intent-filter决定的,如果有intent-filter,默认值为true,否则为false);
android:name
此broadcastReceiver类名;
android:permission
如果设置,具有相应权限的广播发送方发送的广播才能被此broadcastReceiver所接收;
android:process
broadcastReceiver运行所处的进程。默认为App的进程。可以指定独立的进程(Android四大组件都可以通过此属性指定自己的独立进程);
不过目前BootCompleteReceiver还是不能接收到开机广播的,还需要对广播进行限定,添加广播过滤器和申请权限。
1 | <receiver |
1 | <uses-permission android:name="android.permission.RECEIVE_BOOT_COMPLETED"/> |
- 由于Android系统启动完成后会发出一条值为android.permission.RECEIVE_BOOT_COMPLETED的广播,因此我们 标签里添加了相应的action。
- 监听系统开机广播也是需要声明权限的,我们使用标签又加入一条android.permission.RECEIVE_BOOT_COMPLETED权限。
将模拟器重新启动就可以收到开机广播了。
需要额外注意的是,不要在onReceive()方法中添加过多的逻辑或者进行任何的耗时操作,因为在广播接收器中是不允许开启线程的,当onReceive方法运行较长时间而没有结束时,程序就会报错。所以广播接收器更多的是扮演一种打开程序其他组件的角色,比如创建一条状态栏通知,或者启动一个服务等。
发送广播
根据广播的发送方式,可以将其分为以下几种类型:
- Normal Broadcast:普通广播
- Ordered broadcast:有序广播
- Sticky Broadcast:粘性广播 (在 android 5.0/api 21中deprecated,不再推荐使用,相应的还有粘性有序广播,同样已经deprecated)
发送标准广播
标准广播的主要特点为:
- 同级别接收先后是随机的(无序的)
- 级别低的后接收到广播
- 接收器不能截断广播的继续传播,也不能处理广播
- 同级别动态注册(代码中注册)高于静态注册(AndroidManifest中注册)
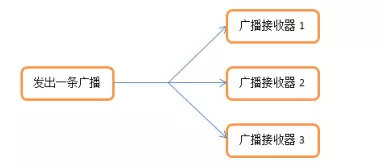
Context类提供两个方法可以用于发送普通广播:
sendBroadcast(Intent intent);
**sendBroadcast(Intent intent, String receiverPermission);**【第一个参数是intent,第二个参数是一个与权限有关的字符串】
差别是第二个设置权限。
发给特定的用户:
sendBroadcastAsUser(Intent intent, UserHandle user);
sendBroadcastAsUser(Intent intent, UserHandle user, String receiverPermission);
发送有序广播
有序广播(Ordered broadcasts)则是一种同步执行的广播,在广播发出之后,同一时刻只会有一个广播接收器能够收到这条广播消息,当这个广播接收器中的逻辑执行完毕后,广播才会继续传递。所以此时的广播接收器是有先后顺序的,优先级高的广播接收器就可以先收到广播消息,并且前面的广播接收器还可以截断正在传递的广播,这样后面的广播接收器就无法收到广播消息了,只是其的主要发送方式变为:sendOrderedBroadcast(intent, receiverPermission, …)。
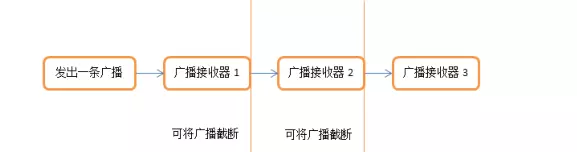
1>多个具当前已经注册且有效的BroadcastReceiver接收有序广播时,是按照先后顺序接收的,先后顺序判定标准遵循为:将当前系统中所有有效的动态注册和静态注册的BroadcastReceiver按照priority属性值从大到小排序,对于具有相同的priority的动态广播和静态广播,动态广播会排在前面。
2>先接收的BroadcastReceiver可以对此有序广播进行截断,使后面的BroadcastReceiver不再接收到此广播,也可以对广播进行修改,使后面的BroadcastReceiver接收到广播后解析得到错误的参数值。当然,一般情况下,不建议对有序广播进行此类操作,尤其是针对系统中的有序广播。
有序广播的主要特点:
同级别接收是随机的(结合下一条)
同级别动态注册(代码中注册)高于静态注册(AndroidManifest中注册)
排序规则为:将当前系统中所有有效的动态注册和静态注册的BroadcastReceiver按照priority属性值从大到小排序
先接收的BroadcastReceiver可以对此有序广播进行截断,使后面的BroadcastReceiver不再接收到此广播,也可以对广播进行修改,使后面的BroadcastReceiver接收到广播后解析得到错误的参数值。当然,一般情况下,不建议对有序广播进行此类操作,尤其是针对系统中的有序广播。实现截断的代码为:
1 | abortBroadcast(); |
发送本地广播
前面涉及的都是系统的全局广播。容易引起安全性的问题。
本地广播就只能在应用程序的内部进行传递,广播接收器也只能接收来自本应用程序发出的广播。
发送本地广播主要使用LocalBroadcastManager来对广播进行管理,并提供了发送广播和注册广播接收器的方法
代码实现:
1 | public class MainActivity extends Activity { |
对于LocalBroadcastManager方式发送的应用内广播,只能通过LocalBroadcastManager动态注册的ContextReceiver才有可能接收到(静态注册或其他方式动态注册的ContextReceiver是接收不到的)。
本地广播是无法通过静态注册的方式来接收的,因为静态注册主要就是为了让程序在未启动的情况下也能收到广播,而发送本地广播时,我们的程序肯定已经启动了。
本地广播的优势:
- 可以明确知道正在发送的广播不会离开我们的程序,不需要担心机密数据泄漏的问题。
- 其他的程序无法将广播发送到我们程序的内部,不需要担心会有安全漏洞的隐患。
- 发送本地广播比起发送系统全局广播将会更加高效。
广播的安全性问题
由前文阐述可知,Android中的广播可以跨进程甚至跨App直接通信,且exported属性在有intent-filter的情况下默认值是true,由此将可能出现的安全隐患如下:
- 其他App可能会针对性的发出与当前App intent-filter相匹配的广播,由此导致当前App不断接收到广播并处理;
- 其他App可以注册与当前App一致的intent-filter用于接收广播,获取广播具体信息。
无论哪种情形,这些安全隐患都确实是存在的。由此,业界常见的一些增加安全性的方案包括:
- 对于同一App内部发送和接收广播,将exported属性人为设置成false,使得非本App内部发出的此广播不被接收;
- 在广播发送和接收时,都增加上相应的permission,用于权限验证;
- 发送广播时,指定特定广播接收器所在的包名,具体是通过intent.setPackage(packageName)指定,这样此广播将只会发送到此包中的App内与之相匹配的有效广播接收器中。
- 采用LocalBroadcastManager的方式
Adapter
Android adapter
简单来说:适配器是用来帮助数据以合适的形式显示在view中给用户看的。
Android中Adapter类其实就是把数据源绑定到指定的View上,然后再返回该View,(eg:而返回来的这个View就是ListView中的某一 行item。)这里返回来的View正是由我们的Adapter中的getView方法返回的。(这样就会容易理解数据是怎样一条一条显示在ListView 中的。)
Adapter是连接后端数据和前端显示的适配器接口,是数据和UI(View)之间一个重要的纽带。在常见的View(ListView,GridView)等地方都需要用到Adapter。如下图直观的表达了Data、Adapter、View三者的关系:

Android中的adapter
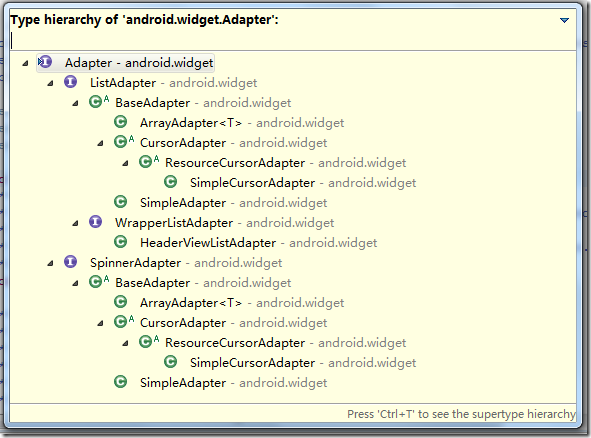
在我们使用过程中可以根据自己的需求实现接口或者继承类进行一定的扩展。比较常用的有 BaseAdapter,SimpleAdapter,ArrayAdapter,SimpleCursorAdapter等。
- BaseAdapter是一个抽象类,继承它需要实现较多的方法,所以也就具有较高的灵活性;
- ArrayAdapter支持泛型操作,最为简单,只能展示一行字。
- SimpleAdapter有最好的扩充性,可以自定义出各种效果。
- SimpleCursorAdapter可以适用于简单的纯文字型ListView,它需要Cursor的字段和UI的id对应起来。如需要实现更复杂的UI也可以重写其他方法。可以认为是SimpleAdapter对数据库的简单结合,可以方便地把数据库的内容以列表的形式展示出来。
ArrayAdapter(数组适配器)
只能显示一行文本数据
https://www.cnblogs.com/huolan/p/5126794.html
布局文件
1 |
|
Java文件
1 | package com.example.test3; |
效果图:
ArrayAdapter的参数说明:
第一个参数:context上下文对象
第二个参数:每一个item的样式,可以使用系统提供,也可以自定义就是一个TextView
第三个参数:数据源,要显示的数据
系统提供的item的样式,可以试一试:
simple_list_item1:单独的一行文本框
simple_list_item2:有两个文本框组成
simple_list_item_checked每项都是由一个已选中的列表项
simple_list_item_multiple_choice:都带有一个复选框
simple_list_item_single_choice:都带有一个单选框
SimpleAdapter
simpleAdapter的扩展性最好,可以定义各种各样的布局出来,可以放上ImageView(图片),还可以放上Button(按钮),CheckBox(复选框)等等。
使用的样例:
1 |
|
实现的item样例:
1 |
|
java文件
1 | package com.example.test3; |
效果图:

simpleAdapter中五个参数的
第一个参数:上下文对象
第二个参数:数据源是含有Map的一个集合(使用simpleAdapter的数据用一般都是HashMap构成的List,list的每一节对应ListView的每一行。)
第三个参数:每一个item的布局文件
第四个参数:new String[]{}数组,数组的里面的每一项要与第二个参数中的存入map集合的的key值一样,一一对应
第五个参数:new int[]{}数组,数组里面的第三个参数中的item里面的控件id。
BaseAdapter
使用ViewHolder来优化。减少findViewById的使用
就是一个持有者的类,他里面一般没有方法,只有属性,作用就是一个临时的储存器,把你getView方法中每次返回的View存起来,可以下次再用。这样做的好处就是不必每次都到布局文件中去拿到你的View,提高了效率。
https://www.jianshu.com/p/46d7ef09cb88
baseAdapter的逗比式、普通式、文艺式链接:
https://www.jianshu.com/p/112ccd04c5ff
逗比式:没有使用到ListView的缓存机制,每需要显示一个item布局,就会创建一个新的View对象
普通式:利用了ListView的缓存特性,如果没有缓存(convertView)才创建新的View
ListView的显示和缓存机制:
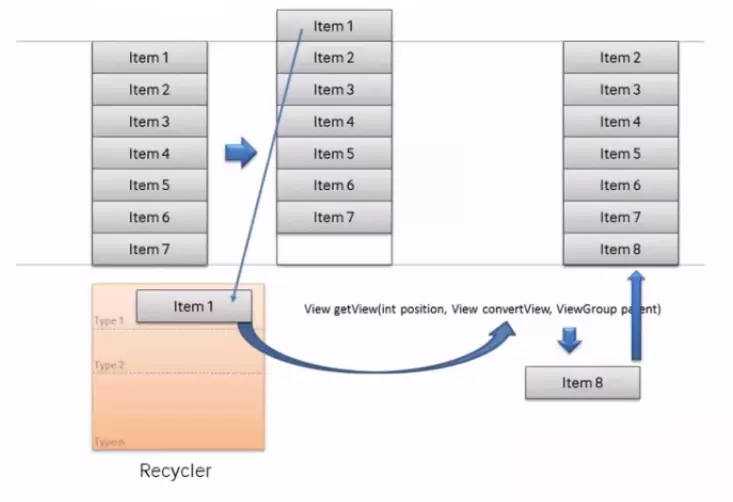
文艺式:使用到了ViewHolder。使用convertView中的setTag方法(他是给View对象的一个标签,标签可以是任何内容)屏幕中有多少view就会创建多少与之对应的viewholder类。循环的时候,就不用findviewby了,因为之前已经findviewby过了 并且存储在viewholder类中。
详细介绍的viewholder和缓存机制是怎么协同的:https://blog.csdn.net/MoDuRooKie/article/details/80198431
Tag不像ID是用标示view的。Tag从本质上来讲是就是相关联的view的额外的信息。它们经常用来存储一些view的数据,这样做非常方便而不用存入另外的单独结构。
setTag方法:https://blog.csdn.net/grandgrandpa/article/details/82964251
Activity
Activity概述
活动代表了一个具有用户界面的单一屏幕,如 Java 的窗口或者帧。Android 的活动是 ContextThemeWrapper 类的子类。
它是一种可以包含用户界面组件,主要用于和用户进行交互。
AndroidManifest文件
AndroidManifest.xml 是每个android程序中必须的文件。它位于整个项目的根目录,描述了package中暴露的组件(activities, services, 等等),他们各自的实现类,各种能被处理的数据和启动位置。 除了能声明程序中的Activities, ContentProviders, Services, 和Intent Receivers,还能指定permissions和instrumentation(安全控制和测试)
活动与任务
Android将这些活动保持在同一个任务(task)中以维持用户的体验。简单地讲,任务是用户体验上的一个“应用程序”,是排成堆栈的一组相关活动。栈底的活动(根活动)是起始活动——一般来讲,它是用户在应用程序启动器(也称应用程序列表,下同)中选择的一个活动。栈顶的活动是正在运行的活动——它关注用户的行为(操作)。当一个活动启动另一个,新的活动被压入栈顶,变为正在运行的活动。前面那个活动保存在栈中。当用户点击返回按钮时,当前活动从栈顶中弹出,且前面那个活动恢复成为正在运行的活动。
一个任务的所有活动作为一个整体运行。整个任务(整个活动栈)可置于前台或发送到后台。例如,假设当前任务有四个活动在栈中——三个活动在当前活动下面。用户按下HOME键,切换到程序启动器,并选择一个新的应用程序(实际上是一个新的任务)。当前任务进入后台,新任务的根活动将显示。接着,过了一会,用户回到主屏幕并再次选择之前的应用程序(之前的任务)。那个任务栈中的所有四个活动都变为前台运行。当用户按下返回键时,不是离开当前任务回到之前任务的根活动。相反,栈顶的活动被移除且栈中的下一个活动将显示。
上面所描述的是活动和任务的默认行为,但是有方法来改变所有这些行为。活动与任务之间的联系及任务中活动的行为,是由启动活动的Intent对象的标志(flags)和清单文件中活动
菜单menu
https://www.cnblogs.com/HDK2016/p/8038908.html
https://blog.csdn.net/aiynmimi/article/details/54964945
菜单的分类
菜单是Android应用中非常重要且常见的组成部分,主要可以分为三类:选项菜单、上下文菜单/上下文操作模式以及弹出菜单。它们的主要区别如下:
选项菜单是一个应用的主菜单项,用于放置对应用产生全局影响的操作,如搜索/设置。
上下文菜单是用户长按某一元素时出现的浮动菜单。它提供的操作将影响所选内容,主要应用于列表中的每一项元素(如长按列表项弹出删除对话框)。上下文操作模式将在屏幕顶部栏(菜单栏)显示影响所选内容的操作选项,并允许用户选择多项,一般用于对列表类型的数据进行批量操作。
弹出菜单以垂直列表形式显示一系列操作选项,一般由某一控件触发,弹出菜单将显示在对应控件的上方或下方。它适用于提供与特定内容相关的大量操作。
选项菜单
当用户单击设备上的菜单按钮(Menu),触发事件弹出的菜单就是选项菜单。
效果图:


实现过程讲解:
在Activity中重写onCreateOptionsMenu()来创建选项菜单,在中包含了getMenuInflater().inflate(R.menu.main,menu),R.menu.main是res的menu文件夹下的xml文件是放菜单的文件夹;
实现代码:
设置菜单项可以通过两种方法
1.通过在XML文件中添加控件来实现
在R.menu.main的xml文件中,添加item控件来添加设置菜单项;
1 | <menu xmlns:android="http://schemas.android.com/apk/res/android" |
其中:showAsAction主要是针对这个菜单的显示起作用的,它有三个可选项
always:总是显示在界面上
never:不显示在界面上,只让出现在右边的三个点中
ifRoom:如果有位置才显示,不然就出现在右边的三个点中
java代码和设置监听:
1 | public boolean onCreateOptionsMenu(Menu menu) { |
2、通过动态代码实现
1 | menu.add(groupId,itemId,order,title), |
menu的用法类似于ArrayList,可以调用add方法来加载如
//API大于等于11 时 Item图标不显示
menu.add(1,100,1,”菜单一”);
menu.add(1,101,1,”菜单二”);
menu.add(1,102,1,”菜单三”);
add方法返回的是item,可以赋值给item,再调用item的setTitle与setIcon(在API>=11时,是不显示图标的)来设置item。
代码如下:
1 | public boolean onCreateOptionsMenu(Menu menu) { |
上下文菜单(context menu)
当用户长按Activity页面时,弹出的菜单我们称为上下文菜单。我们经常在Windows中用鼠标右键单击弹出的菜单就是上下文菜单。
ContextMenu与OptionMenu的区别:
1、OptionMenu对应的是activity,一个activity只能拥有一个选项菜单;
2、ContextMenu对应的是view,每个view都可以设置上下文菜单;
3、一般情况下ContextMenu常用语ListView或者GridView
实现步骤:
(1)首先给View注册上下文菜单registerForContextMenu()this.registerForContextMenu(contextView);
(2)添加上下文菜单的内容onCreateContextMenu()
效果图:

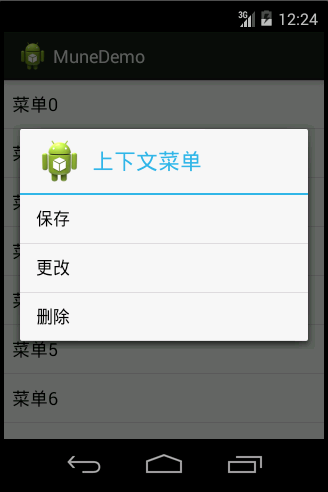
代码:
1 | <FrameLayout xmlns:android="http://schemas.android.com/apk/res/android" |
1 | protected void onCreate(Bundle savedInstanceState) { |
注:何为上下文菜单:Windows操作系统中任何地方右击鼠标会出现俗称的“右键菜单”,其实就是指上下文菜单。因为上下文菜单根据鼠标位置来判断弹出什么的菜单(如桌面右击显示个性化菜单,文件右击则显示针对文件操作删除等的菜单)也就是根据上下文来判断如何弹出和弹出哪种菜单,所以称为上下文菜单。手机上就是长按会弹出选项
子菜单(Sub Menu)
就是将功能相同的操作分组显示,他作用在OptionsMenu上,是OptionsMenu的二级菜单
实现步骤:
(1)重写onCreateOptionsMenu()方法
(2)点击事件,重写onOptionsItemSelected()方法
注意:
(1)SubMenu.add(groupId, itemId, order, title);
因为每个SubMenu有一个groupId,所以需要使用这个groupId区别是点击了那个子菜单
(2)APP的样式会影响子菜单的显示风格
效果图:
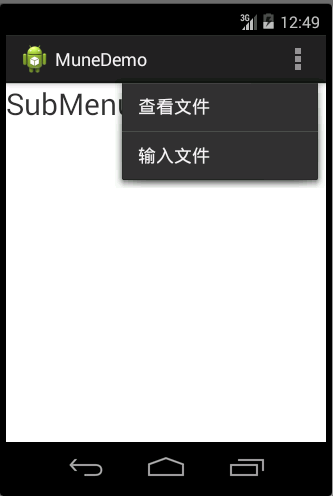
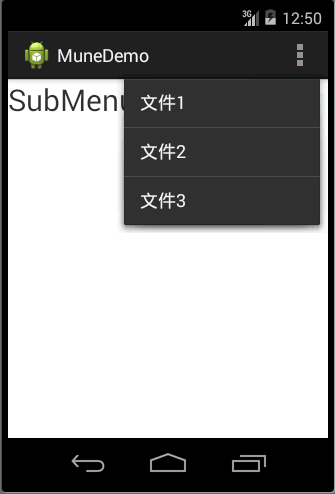
代码:
1 | <FrameLayout xmlns:android="http://schemas.android.com/apk/res/android" |
1 |
|
menu的属性解释
android:id
定义资源ID,它是个唯一值,使用“@+id/name”格式可以给这个菜单项创建一个新的资源ID,“+”号指示要创建一个新的ID。android:title
字符串资源,它用字符串资源或原始的字符串来定义菜单的标题。android:titleCondensed
字符串资源。它用字符串资源或原始的字符串来定义一个简要的标题,以便在普通的标题太长时来使用。android:icon
可绘制资源,它定义了一个菜单项所要使用的图标。android:onClick
方法名。在这个菜单项被点击时,会调用这个方法。在Activity中,这个方法必须用public关键字来声明,并且只接受一个MenuItem对象,这个对象指明了被点击的菜单项。这个方法会优先标准的回调方法:onOptionsItemSelected()。
警告:如果要使用ProGuard(或类似的工具)来混淆代码,就要确保不要重名这个属性所指定的方法,因为这样能够破坏功能。
这个属性在API级别11中被引入。android:showAsAction
关键词。它定义这个项目作为操作栏中的操作项的显示时机和方式。只用Activity包含了一个ActionBar对象时,菜单项才能够作为操作项来显示。这个属性在API级别11中被引入,有效值如下:
值 说明
ifRoom 如果有针对这个项目的空间,则只会把它放到操作栏中
withText 操作项也要包含文本(通过android:title属性来定义的)。可以把这个值与其他的Flag设置放到一起,通过管道符“|”来分离它们。
never 这个项目不会放到操作栏中
always
始终包这个项目放到操作栏中。要避免使用这个设置,除非在操作栏中始终显示这个项目是非常关键的。设置多个项目作为始终显示的操作项会导
致操作栏中其他的UI溢出。
icollapseActiionView 它定义了跟这个操作项关联的可折叠的操作View对象(用android:actionViewLayout来声明)。这个关键词在API级别14中被引入。android:actionViewLayout
它引用一个布局资源,这个布局要用于操作窗口。更多的信息请参照“操作栏”开发指南。这个属性在API级别11中被引入。android:actionViewClass
类名。它定义了操作窗口要使用的View对象的完整的类名。例如,“android.widget.SearchView”说明操作窗口要使用的SearchView类。
警告:如果要使用ProGuard(或类似的工具)来混淆代码,就要确保不要重名这个属性所指定的方法,因为这样能够破坏功能。
这个属性在API级别11中被引入。android:actionProviderClass类名,它是操作项目所使用的ActionProvider类的完整的类名。例如,“android.widget.ShareActionProvider”说明要使用
ShareActionProvider类。
警告:如果要使用ProGuard(或类似的工具)来混淆代码,就要确保不要重名这个属性所指定的方法,因为这样能够破坏功能。
这个属性在API级别14中被引入。android:alphabeticShortcut
字符,定义一个字符快捷键android:numericShortcut
数字值,定义一个数字快捷键android:checkable
布尔值,如果菜单项是可以复选的,那么就设置为true。android:checked
布尔值,如果复选菜单项默认是被选择的,那么就设置为true。android:visible
布尔值,如果菜单项默认是可见的,那么就设置为true。android:enabled
布尔值,如果菜单项目默认是可用的,那么就设置为true。android:menuCategory
关键词。它的值对应了定义菜单项优先级的CATEGORE_*常量,有效值如下:
值 说明
Container 菜单项是容器的一部分
system 菜单项是由系统提供的。
secondary 提供给用户的辅助选择的菜单项(很少使用)
alternative 基于当前显示的数据来选择操作的菜单项。android:orderInCategory
整数值,它定义菜单项在菜单组中的重要性的顺序。
Group
<group>
它定义了一个菜单组(它是一个具有共同特征的菜单项的组合,如菜单项的可见性、可用性或可复选性)。它要包含多个<item>元素,而且必须是<menu>元素的子元素。
属性(ATTRIBUTES):
android:id
资源ID。它是资源的唯一标识。使用“@+id/name”格式给菜单项创建一个新的资源ID。“+”号指示应该给这个元素创建一个新的资源ID。android:checkableBeharior
关键词。针对菜单组的可复选行为的类型。有效值如下:
值 说明
none 没有可复选性
all 组内的所有的项目都被复选(使用复选框)
single 仅有一个项目能够被复选(使用单选按钮)android:visible布尔值,如果菜单组是可见的,就设置为true。
android:enabled
布尔值,如果菜单组是可用的,就设置为true。android:menuCategory
关键词。它的值对应了Menu类的CATEGORY_*常量,定义了菜单组的优先级。有效值如下:
值 说明
container 菜单组是容器的一部分
system 菜单组是由系统提供的。
secondary 提供给用户的辅助选择的菜单组(很少使用)
alternative 基于当前显示的数据来选择操作的菜单组。android:orderInCategory
整数值,它定义了分类中菜单项目的默认顺序。
使用XML定义menu
理论上而言,使用XML和Java代码都可以创建Menu。但是在实际开发中,往往通过XML文件定义Menu,这样做有以下几个好处:
- 使用XML可以获得更清晰的菜单结构
- 将菜单内容与应用的逻辑代码分离
- 可以使用应用资源框架,为不同的平台版本、屏幕尺寸创建最合适的菜单(如对drawable、string等系统资源的使用)
要定义Menu,我们首先需要在res文件夹下新建menu文件夹,它将用于存储与Menu相关的所有XML文件。
我们可以使用
最大流
最大流
有一个源结点和一个汇点,从源结点向汇点“运输”货物。在不违反任何路径容量限制的条件下,从源结点到汇点运送货物的最大速率是多少——这一问题的抽象称为最大流问题
流具有三个需要注意的点!!
1、对于图中非s和t的普通结点,流进量等于流出量
2、我们非常关心总运输流量,比如这个下水道系统,究竟从s点到t点最多能运输多少立方米的水?我们把它记成|f|,这个|f|极其重要,是我们研究的目的所在。
3、当然,每条边是有运输上限的,就像某条公路车流是有上限的一样,若运输量无穷无尽,我们的研究也就没有意义了。我们将从u点到v点的运输上限,或者说是运载能力记为c(u,v)。对于从u点到v点的流量,记作f(u,v)。显然对所有边(u,v)我们有f(u,v)<=c(u,v)。
参考文章
流网络
流网络G=(V,E)是一个有向图,其中每条边(u,v)∈E均有一个非负能量c(u,v)≥0。如果(u,v)∉E,则假定c(u,v)=0。流网络中有两个特点的顶点,源点s和汇点t,假定每个顶点均处于从源点到汇点的某条路径上,就是说,对每个顶点v∈V,存在一条路径s->v->t,因此图G是连通图,且|E|≥|V|-1。
带权有向图:网络
结点:表示城市
有向边:表示运输路径和物流的方向
权重:表示运量限制
流:一条从源点到汇点的路径即路径上的流量——这种用来表示”流(flow)”的图称为“流网络”
流网络遵循以下基本性质:
(1)流量守恒:除源结点和汇点外,其它结点上物料只是“流过”,即物料进入的速率等于离开的速率;
(2)物料的生成速率和接收速率恒定且足够快、足够多,满足需要(包括源结点的输出和所有结点的输入);
(3)每条边上的容量是物料通过该边的最大速率,不能突破
流网络是一个有向图,边上定义有容量函数c:
(1) 有一个源结点s和汇点t;
(2) 有向边表示流向;
(3) 每条边上有一个非负的容量值;如果(u,v)∉E,则假定c(u,v)=0;
(4) 如果边集合E中包含(u,v)边,则图中不包含其反向边(u,v);
(5) 图中不允许有自循环;
(6) 流网络是连通图,每个结点都在从s到t的某条路径上;
(7) 除源结点外,每个结点至少有一条流入的边;
(8) 除汇点外,每个结点至少有一条流出的边;
(9) |E|>=|V|-1
标准流网络:
(1)无反向边:也称为反向平行边。一个有向图中,(v,u)、(u,v)互为反向平行边
(2)只有单一的源结点和汇点。
非标准流网络:
不满足上述要求的流网络是非标准的流网络。对于非标准的流网络可转化为标准流网络。
方法:
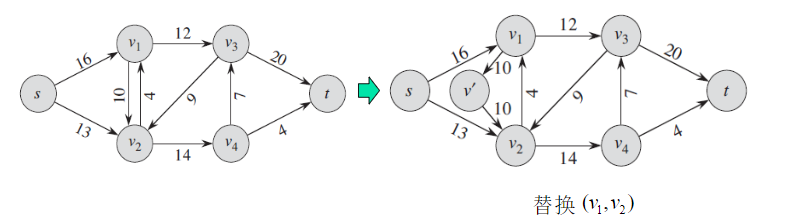
1)添加反向平行边
2)多个源结点和多个汇点。加入一个超级源结点s。加入一个超级汇点t。
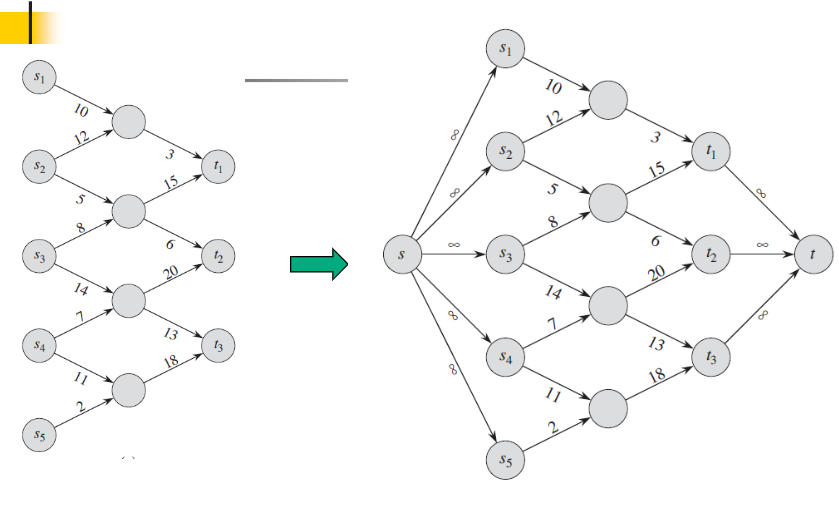
Ford-Fulkerson方法
通过不断增加可行流值的方式找到最大流:
(1)从流值为0的初始流开始;
(2)通过某种方法,对流值进行增加;
(3)当确认无法再增加流值时,就得到最大流;
首先这个算法有个重要的工具:残存网络。残存网络其实就是具有残存容量的图。算法导论上有个普遍公式来定义残存容量: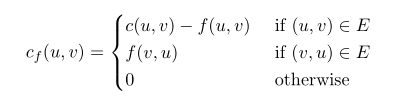
翻译一下公式,说明的就是对于两点间的残存容量定义为:
1.如果这两点连线原来就是原图的边,那么它的残存容量等于运载上限-运输流量。(就是目前你还能增加的流量的量)
2.如果这两点的反向连线是原图的边,那么它的残存容量等于那条边的运输流量。(表示目前用的运输流量,一旦该运输流量等于运载上限,运算结束)
3.其他情况是0,当做没连通。
接下来我们看看残存网络对我们的帮助:
1.残存网络中没有从s到t的路径时,最大流等于最小割容量。(没有路径就说明s到t的连线有一段已经达到了最大运载上限了,就是残存容量为0)
2.残存网络中有从s到t的路径时,最大流不等于最小割容量。
最大流算法应用:寻找最大二分匹配
所有结点对的最短路径
所有结点对的最短路径
问题:有一个带权有向图 G = (V, E),V 为图的顶点集合,E 为边的集合,权重函数为 w:E → R,该函数将边映射到实数值上。我们希望找到,对于所有结点对 u,v∈V,一条从结点 u 到结点 v 的最短路径,使得结点 u 到结点 v 的路径所有边的权重之和最小。
简单来说,我们考虑的问题是如何找到一个图中所有结点之间的最短路径。
用单源最短路径算法求解:
执行|V|次单源最短路径算法,每次使用一个不同的结点作为源点,从而可以求出每个结点到其他所有结点的最短路径。
- 如果所有的边的权重为非负值,用Dijkstra算法:
- 用线性数组实现最小优先队列:O(V^3^+VE)=O(V^3^);
- 用二叉堆实现最小优先队列:O(VElgV);(对稀疏图较好)
- 用斐波那契堆实现最小优先队列:O(V^2^lgV+VE);
- 如果有权重为负值边,用Bellman-Ford算法:
- 一般的运行时间:O(V^2^E);
- 对稠密图,运行时间为O(V^4^)。
允许存在权重为负值的边,但不能包含权重为负值的环路
邻接矩阵
邻接矩阵是表示一个图的常用存储表示。它用两个数组分别存储数据元素(顶点)的信息和数据元素之间的关系(边或弧)的信息。
$$
W_{ij}=\begin{cases}0 &&&&&&if&i=j\有向边(i,j)的权重 &&&&&&if&i\not=j&and(i,j)\in E\NIL &&&&&&if&i\not=j&and(i,j)\notin E\\end{cases}
$$
最短路径和矩阵乘法
步骤一:分析最优解结构
一条最短路径的所有子路径都是最短路径
每条路径都是最短路径
步骤二:所有结点对最短路径的递归解
设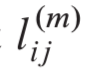
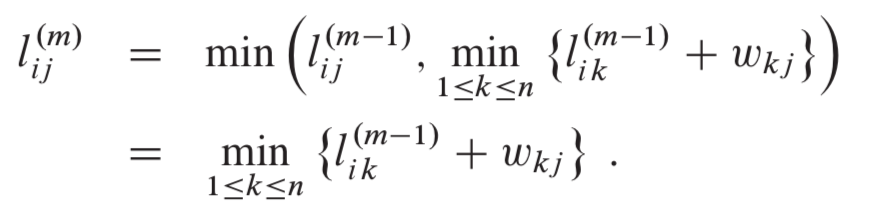
如果图G不包含权重为负值的环路,则对于每一对结点i和j,如果δ(i,j)<∞,则从i到j之间存在一条最短路径。并且,由于最短路径是简单路径,其中至多包含n-1条边,因此有:
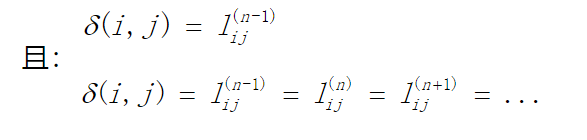
步骤三:自底向上计算最短路径权重
步骤三改进:重复平方
步骤四:构建最优解
计算最短路径权重 - Floyd-Warshall 算法
采取的是动态规划策略
算法的时间复杂度Θ(V^3^)。
算法允许图中存在负权重的边,但不能存在权重为负值的环路
Floyd 算法考虑的是一条路径上的中间结点。对于任意结点对 i,j∈V,考虑从结点 i 到结点 j 的所有中间结点均取自集合 {1, 2, …, k} 的路径(该集合是 V ={1,2,3·····,n}的一个子集),并且设 p 为最短路径。
含义:
p是简单路径,且p的中间结点都不大于k。
p从i到j,仅经过集合{1,2,…,k}中的结点,但,
- 不一定经过其中的每一个结点,且与顺序无关;
- 也可能不存在这样的路径,此时p的权重等于∞
从任意节点i到任意节点j的最短路径不外乎2种可能,1是直接从i到j,2是从i经过若干个节点k到j。所以,算法假设Dis(i,j)为节点u到节点v的最短路径的距离,对于每一个节点k,算法检查Dis(i,k) + Dis(k,j) < Dis(i,j)是否成立,如果成立,证明从i到k再到j的路径比i直接到j的路径短,便设置Dis(i,j) = Dis(i,k) + Dis(k,j),这样一来,当遍历完所有节点k,Dis(i,j)中记录的便是i到j的最短路径的距离。
有两种情况:
- 如果结点 k 不是路径 p 上的中间结点,则路径 p 上的所有中间结点都属于集合 {1, 2, …, k - 1}。
- 如果结点 k 是路径 p 上的中间结点,则可将路径 p 分解为两条路径,分别是结点 i 到结点 k 和结点 k 到结点 j 的路径。
简单来说,就是中间结点选自集合 {1,2,…,k - 1} 的时候的所有结点对的最短路径权重已经知道了,接下来的考虑的中间结点从集合 1,2,…,k - 1,k} 选的时候最短路径权重是多少,只需要考虑路径经过结点 k 的时候权重变化就行了,k 可将 i 到 j 的路径分为两条路径,分别是结点 i 到结点 k 和结点 k 到结点 j 的路径,而这两个的最短路径权重已经知道的(i 到 k 的最短路径的中间结点只能从集合 {1,2,…,k - 1} 选),同理 k 到 j),所以最新的权重选择经过 k 与不经过 k 时的权重较小的那个就行。
递归解
设$$d^{(k)}_{ij}$$表示从结点 i 到结点 j 的所有中间结点全部取自集合 {1,2,…,k} 的一条最短路径的权重。
k = 0 时,表示结点 i 到结点 j 的路径没有任何中间结点,因此$$d^{(0)}{ij} = w{ij} $$。
状态转移方程:
$$
d^{(k)}{ij} = \begin{cases} w{ij} & \text {if $k = 0$} \min(d^{(k-1)}{ij}, d^{(k-1)}{ik}+ d^{(k-1)}_{kj}) & \text {if $k\geq1$ }\end{cases}
$$
而因为任何路径的中间结点都属于集合{1,2,…,n},所以k=n时,$$d^{(n)}_{ij}$$给出所有可能的从结点i到结点j的中间结点均取自集合{1,2,…,n}的一条最短路径的权重,也就是从结点i到结点j的最短路径的权重。
所以对所有的$$i,j\in V$$,有:
$$
d^{(n)}_{ij}=δ(i,j)
$$
自底向上计算最短路径权重
1 | private void floyd(Graph G, int dist) |
构建最短路径
思路:给定一个前驱矩阵 $$\prod$$,再利用递归的思想即可输出结点 i 到结点 j 的最短路径。
前驱矩阵
定义:给出的是从结点 i 到结点 j 的最短路径上结点 j 的前驱结点,i=j 或者从 i 到 j 不存在路径时为 NIL。
$$\pi^{(k)}_{ij}$$为从结点i到结点j的一条所有中间结点都取自集合{1,2, …, k}的最短路径上j的前驱结点。
怎么得到前驱矩阵?一种方法是计算权重矩阵 dist 的同时计算前驱矩阵 ∏。具体来说,与 floyd 算法思路类似,分为两种情况:
当 k = 0 时,从 i 到 j 的最短路径没有中间结点,所以,
$$
\pi^{(0)}{ij} = \begin{cases} NIL & \text {if $i = j\ or\ w{ij} = NIL$ } \i & \text {if $i \ne j\ or\ w_{ij} < NIL$ }\end{cases}
$$
当 k≥1时
$$
\pi^{(k)}{ij} = \begin{cases}\pi^{(k-1)}{ij} & \text {if $d^{(k-1)}{ij} \leq d^{(k-1)}{ik} + d^{(k-1)}{kj}$ } \ \pi^{(k-1)}{kj} & \text {if $d^{(k-1)}{ij} > d^{(k-1)}{ik} + d^{(k-1)}_{kj}$ }\end{cases}
$$
若不经过k:
此时求从结点i到结点j的所有中间结点都取自集合{1,2,…,k}的最短路径上的j的前驱等价于求从结点i到结点j的所有中间结点都取自集合{1,2,…,k-1}的最短路径上的j的前驱。
若经过k:
此时求从结点i到结点j的所有中间结点都取自集合{1,2,…,k}的最短路径上的j的前驱等价于求从结点k到结点j的所有中间结点都取自集合{1,2,…,k-1}的最短路径上的j的前驱。
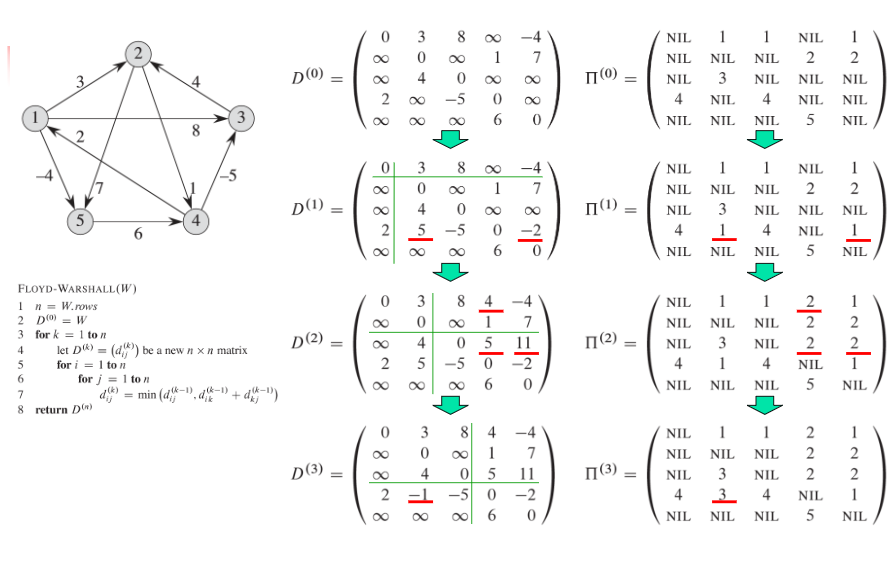
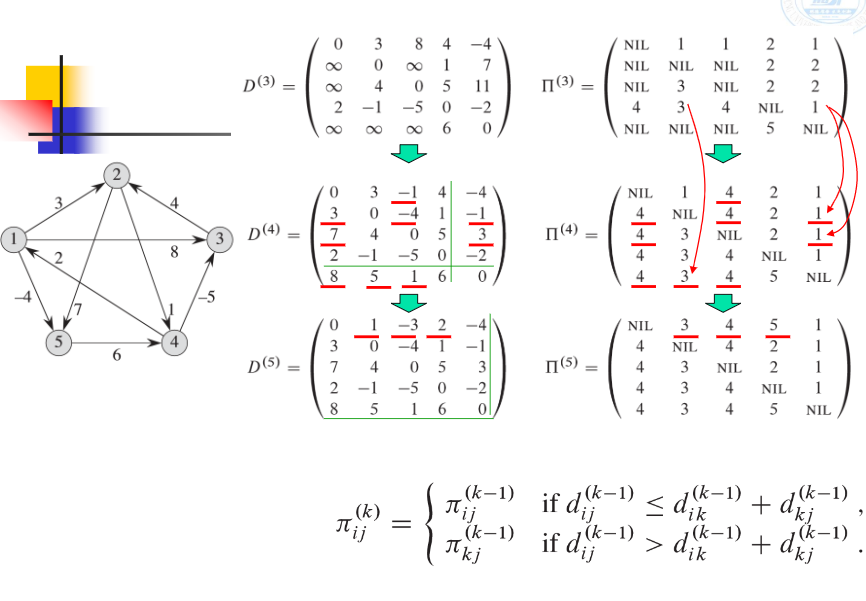
用于稀疏图的Johnson算法
在稀疏图中求每对结点之间的最短路径权重。
对稀疏图,Johnson算法优于Floyd-Warshall算法,时间复杂度可达O(V^2^lgV+VE)。
- Johnson算法使用的方式相当于给每个边都加了一个权重,使得所有边都为非负数,这样就能对每个边使用较为高效的Dijkstra算法。
- 注意的是不能简单的给每个边加相同的值然后使得所有边都变成非负数,原因为假设从a->b有两条路径,一条权重为1+1,一条为2,本应权重和相等;如果都加1,则变成了2+2和3,不一致了,就会导致更新了不该更新的边。
- Johnson比较巧妙的引入了h函数来解决这个问题,通过这个函数进行每个边的重新赋值权重
算法描述
- 给定图 G = (V, E),增加一个新的顶点 s,使 s 指向图 G 中的所有顶点都建立连接,设新的图为 G’;
- 对图 G’ 中顶点 s 使用 Bellman-Ford 算法计算单源最短路径,得到结果 h[] = {h[0], h[1], .. h[V-1]};
- 对原图 G 中的所有边进行 “re-weight”,即对于每个边 (u, v),其新的权值为 w(u, v) + (h[u] - h[v]);
- 移除新增的顶点 s,对每个顶点运行 Dijkstra 算法求得最短路径;
算法证明
最小生成树
最小生成树
关于图的几个概念定义:
- 连通图:在无向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该无向图为连通图。
- 强连通图:在有向图中,若任意两个顶点vivi与vjvj都有路径相通,则称该有向图为强连通图。
- 连通网:在连通图中,若图的边具有一定的意义,每一条边都对应着一个数,称为权;权代表着连接连个顶点的代价,称这种连通图叫做连通网。
- 生成树:一个连通图的生成树是指一个连通子图,它含有图中全部n个顶点,但只有足以构成一棵树的n-1条边。一颗有n个顶点的生成树有且仅有n-1条边,如果生成树中再添加一条边,则必定成环。
- 最小生成树:在连通网的所有生成树中,所有边的代价和最小的生成树,称为最小生成树。
最小生成树并不一定唯一
最小生成树的形成
MST性质
假设N = (V,{ E })是一个连通网,U 是顶点集V的一个非空子集。若(u , v )是一条具有最小权值(代价)的边,其中u∈U, v∈V - U,则必存在一棵包含边(u,v)的最小生成树。
证明:
剪枝-粘贴法
假设网N的任何一棵最小生成树都不包含(u,v)。设T是连通网上的一棵最小生成树,当将边(u,v)加入到T中时,由生成树的定义,T中必存在一条包含(u,v)的回路。另一方面,由于T是生成树,则在T上必存在另一条边(u’,v’),其中u’∈U,v’∈V - U,且u和u’之间,v和v’之间均有路径相通。删去边(u’,v’),便可消除上述回路,同时得到另一棵生成树T’。因为(u,v)的代价不高于(u’,v’),则T’的代价亦不高于T,T’是包含(u,v)的一棵最小生成树,和假设矛盾。
贪心策略设计(MST性质)
每个时刻,该方法生长最小生成树的一条边,并在整个策略的实施过程中,管理一个遵守下述循环不变式的边的集合A:在每遍循环之前,A是某棵最小生成树的一个子集。
循环不变式:在每遍循环之前,A是某棵最小生成树的一个子集。
处理策略:每一步,我们选择一条边不违反循环不变式的边(u,v)加入集合A,即A∪{(u,v)}仍是某棵最小生成树的子集。
这样的边称为“安全边”,因为在集合A中加入它不会破坏A的循环不变式。
Kruskal算法(贪心算法)
初始最小生成树边数为0,每迭代一次就选择一条满足条件的最小代价边,加入到最小生成树的边集合里。
- 把图中的所有边按代价从小到大排序;
- 把图中的n个顶点看成独立的n棵树组成的森林;
- 按权值从小到大选择边,所选的边连接的两个顶点u
i,vi(ui,vi,应属于两颗不同的树),则成为最小生成树的一条边,并将这两颗树合并作为一颗树。 - 重复(3),直到所有顶点都在一颗树内或者有n-1条边为止。
- 注意:不能生成环
Kruskal算法的时间为:O(E lgE)。
如果再注意到|E|<|V|2,则有lg|E|=O(lgV),所以Kruskal算法的时间可表示为O(E lgV)。
Prim算法(贪心算法)
此算法可以称为“加点法”,每次迭代选择代价最小的边(已经加到最小生成树的点可以连接的边中选择)对应的点,加入到最小生成树中。算法从某一个顶点s开始,逐渐长大覆盖整个连通网的所有顶点。
- 图的所有顶点集合为V;初始令集合u={s},v=V−u;
- 在两个集合u,v能够组成的边中,选择一条代价最小的边(u
0,v0),加入到最小生成树中,并把v0并入到集合u中。 - 重复上述步骤,直到最小生成树有n-1条边或者n个顶点为止。
- 注意不能生成环
由于不断向集合u中加点,所以最小代价边必须同步更新;需要建立一个辅助数组closedge,用来维护集合v中每个顶点与集合u中最小代价边信息,
Prim算法的运行时间依赖于最小优先队列Q的具体实现。
可用二叉最小优先队列的方式实现。
每次EXTRACT-MIN的时间是O(lgV)。
EXTRACT-MIN的总时间是O(V lgV)。
其它时间:第11行的赋值操作共需O(E lgV)。
Prim算法的时间为:O(V lgV+E lgV)=O(E lgV)。
从渐进意义上看,Kruskal和Prim算法具有相同的运行时间