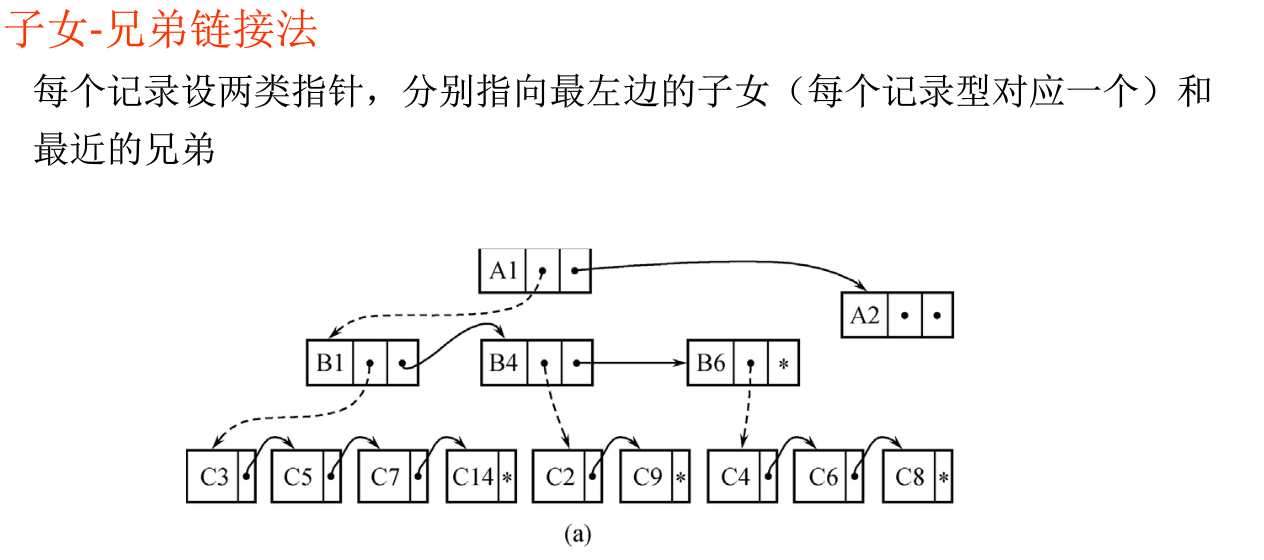
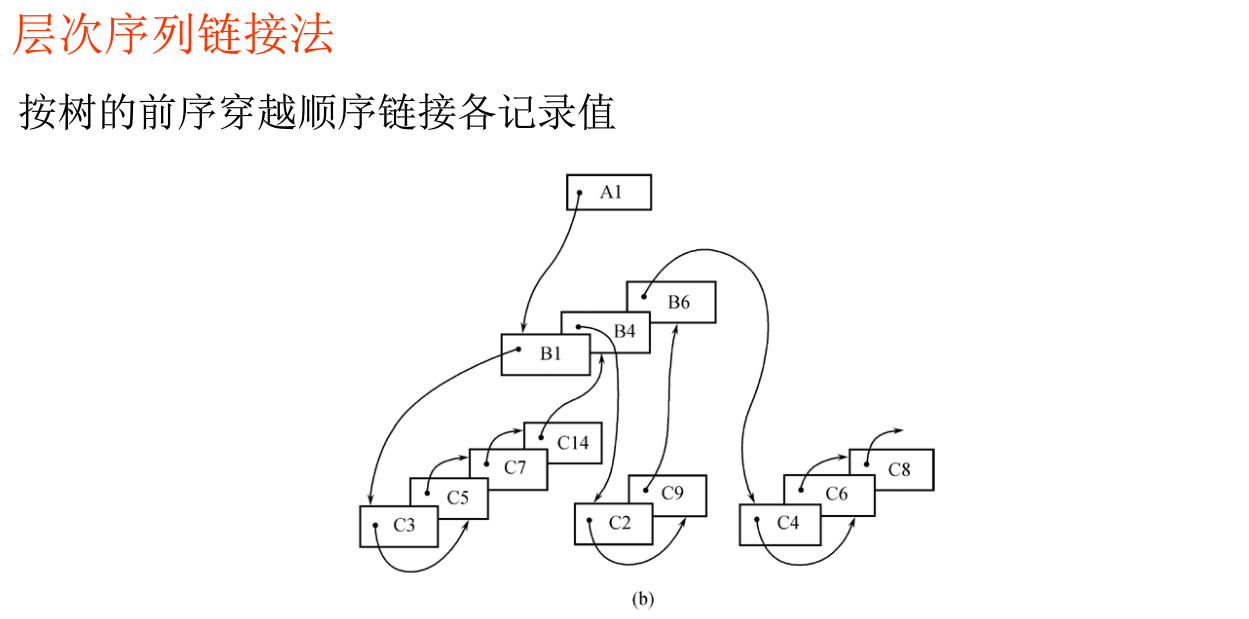
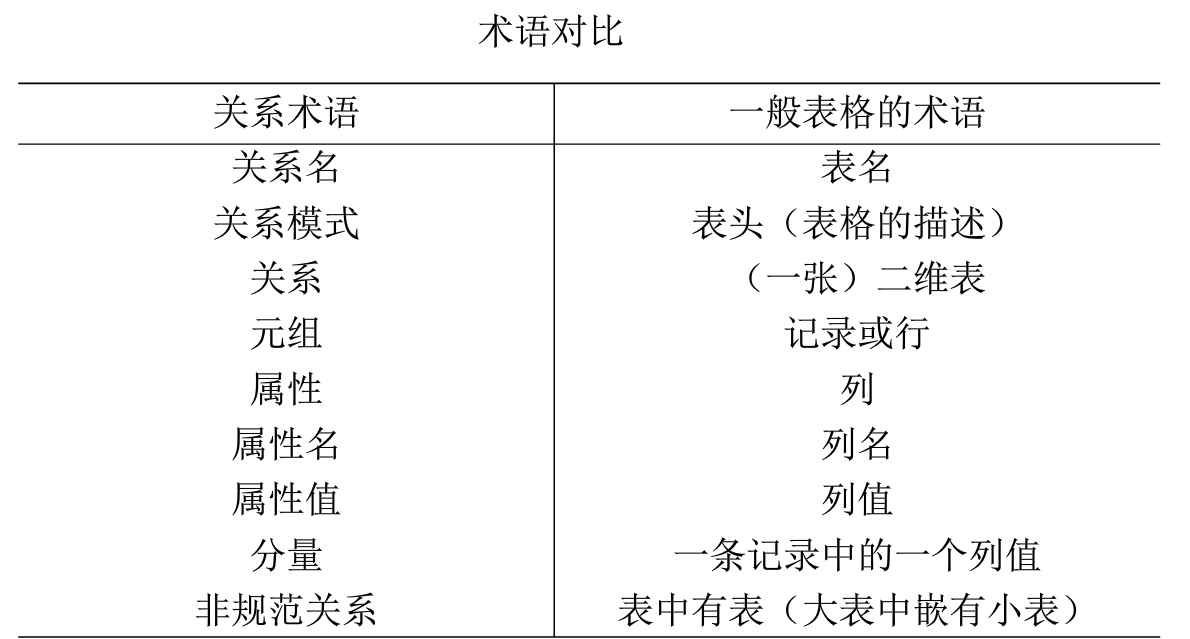
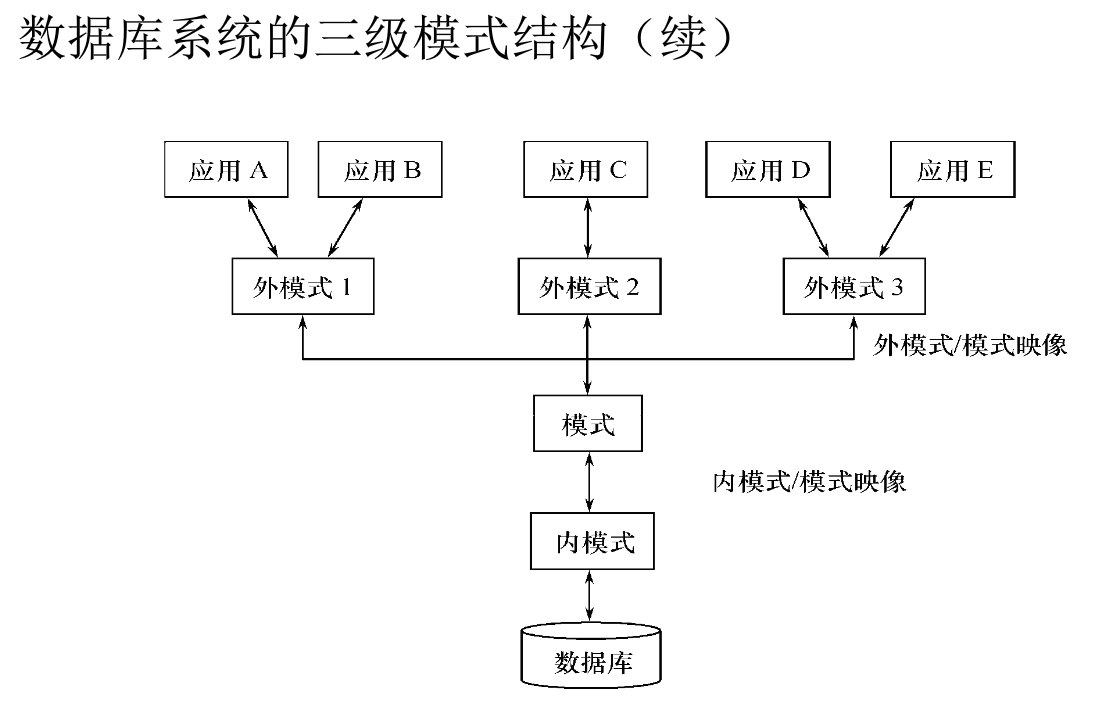
1、java的一些特点
1、简单:Java源自于C++,但做了很多的简化。例如,取消了多重继承、指针、自动地内存分配和垃回收。
2、面向对象:C语言是过程化的语句,把程序看做是对数据进行加工变换。Java是面向对象的语言,用对象来模拟现实世界。对象中包含了数据和操作数据的方法。
3、分布式:Java程序可以在多台计算机上协同计算。可以基于Java RMI,Java RPC编写分布式应用程序
4、解释性:Java的源程序被编译成字节码,在Java虚拟机上运行。Write once, run anywhere,因此效率不如C++。
5、健壮性:Java取消了指针,对数组下标越界进行检查,具有运行时的异常处理功能。
6、安全性:从网络上下载的Applet程序,在Java的安全机制保护下,不会破坏本地系统。
7、与体系结构无关:由于Java是解释性的,可以在任何操作系统上运行。(Write once, run anywhere)
8、可移植性:Java程序无需重新编译就可以在不同的平台上运行。在java语言中没有针对平台的特征,例如整数在不同平台上是长度相同的。(Write once, run anywhere)【java的源代码通过javac编译成字节码.class文件,使用java解释执行机器码(通过JVM)】。由于字节码不面向任何具体平台,只面向JVM,所以具有高移植性。
9、高性能:基于Java的分布式计算环境能够应付高并发的服务请求。Java程序已经可以和C++程序媲美。
10、多线程:Java支持多线程编程,在同一时间执行多个任务。
这里的引用调用和c++中的引用调用完全一样。
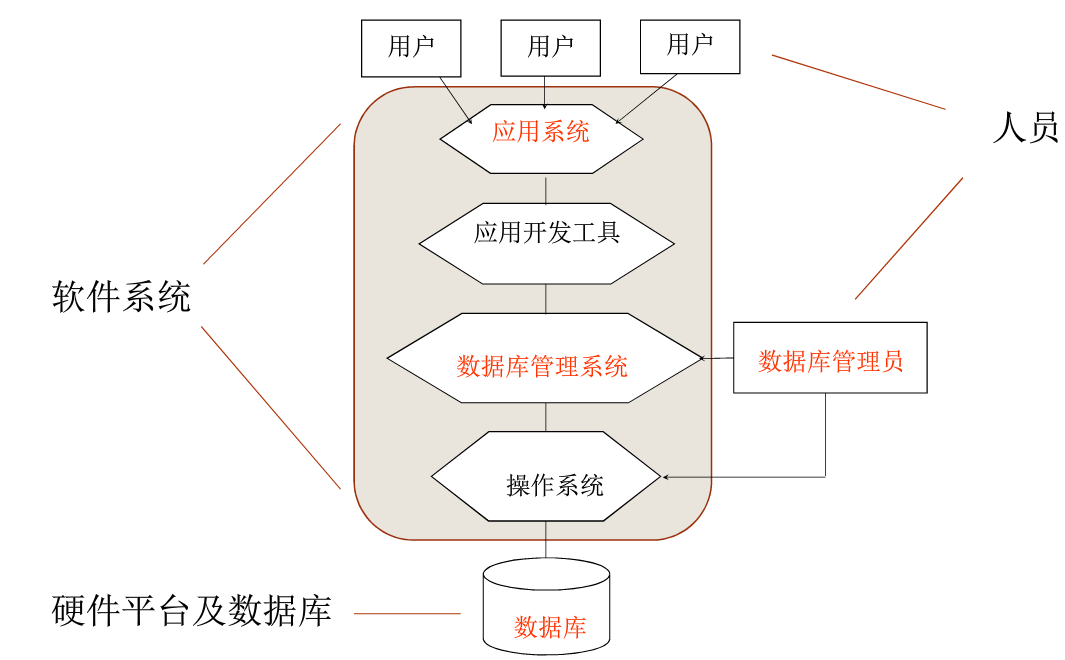
1.1 jvm、jdk、jre 1.1.1 JVM Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。
什么是字节码?采用字节码的好处是什么?
在 Java 中,JVM 可以理解的代码就叫做字节码(即扩展名为 .class 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
Java 程序从源代码到运行一般有下面 3 步:
我们需要格外注意的是 .class->机器码 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 JIT 编译器,而 JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 Java 是编译与解释共存的语言。
HotSpot 采用了惰性评估(Lazy Evaluation)的做法,根据二八定律,消耗大部分系统资源的只有那一小部分的代码(热点代码),而这也就是 JIT 所需要编译的部分。JVM 会根据代码每次被执行的情况收集信息并相应地做出一些优化,因此执行的次数越多,它的速度就越快。JDK 9 引入了一种新的编译模式 AOT(Ahead of Time Compilation),它是直接将字节码编译成机器码,这样就避免了 JIT 预热等各方面的开销。JDK 支持分层编译和 AOT 协作使用。但是 ,AOT 编译器的编译质量是肯定比不上 JIT 编译器的。
总结:
Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。
1.1.2 JDK 和 JRE JDK 是 Java Development Kit 缩写,它是功能齐全的 Java SDK。它拥有 JRE 所拥有的一切,还有编译器(javac)和工具(如 javadoc 和 jdb)。它能够创建和编译程序。
JRE 是 Java 运行时环境。它是运行已编译 Java 程序所需的所有内容的集合,包括 Java 虚拟机(JVM),Java 类库,java 命令和其他的一些基础构件。但是,它不能用于创建新程序。
如果你只是为了运行一下 Java 程序的话,那么你只需要安装 JRE 就可以了。如果你需要进行一些 Java 编程方面的工作,那么你就需要安装 JDK 了。但是,这不是绝对的。有时,即使您不打算在计算机上进行任何 Java 开发,仍然需要安装 JDK。例如,如果要使用 JSP 部署 Web 应用程序,那么从技术上讲,您只是在应用程序服务器中运行 Java 程序。那你为什么需要 JDK 呢?因为应用程序服务器会将 JSP 转换为 Java servlet,并且需要使用 JDK 来编译 servlet。
1.2 java和C++的区别
都是面向对象的语言,都支持封装、继承和多态
Java 不提供指针来直接访问内存,程序内存更加安全
Java 的类是单继承的,C++ 支持多重继承;虽然 Java 的类不可以多继承,但是接口可以多继承。
Java 有自动内存管理垃圾回收机制(GC),不需要程序员手动释放无用内存
在 C 语言中,字符串或字符数组最后都会有一个额外的字符'\0'来表示结束。但是,Java 语言中没有结束符这一概念。 这是一个值得深度思考的问题,具体原因推荐看这篇文章: https://blog.csdn.net/sszgg2006/article/details/49148189
1.3 为什么说 Java 语言“编译与解释并存”? 高级编程语言按照程序的执行方式分为编译型和解释型两种。
编译型语言是指编译器针对特定的操作系统将源代码一次性翻译成可被该平台执行的机器码;
解释型语言是指解释器对源程序逐行解释成特定平台的机器码并立即执行。
Java 语言既具有编译型语言的特征,也具有解释型语言的特征,因为 Java 程序要经过先编译,后解释两个步骤,由 Java 编写的程序需要先经过编译步骤,生成字节码(*.class 文件),这种字节码必须由 Java 解释器来解释执行。因此,我们可以认为 Java 语言编译与解释并存。
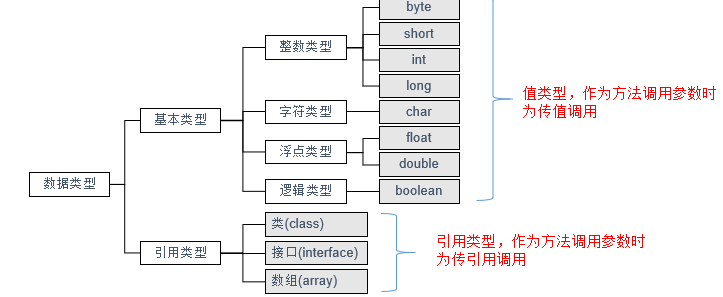
2、java语法 2.1 基本数据类型 boolean 只有两个值:true、false,可以使用 1 bit 来存储,但是具体大小没有明确规定。JVM 会在编译时期将 boolean 类型的数据转换为 int,使用 1 来表示 true,0 表示 false。JVM 支持 boolean 数组,但是是通过读写 byte 数组来实现的。
2.1.1 包装类型 基本类型都有对应的包装类型,基本类型与其对应的包装类型之间的赋值使用自动装箱与拆箱完成。
1 2 Integer x = 2 ; int y = x;
2.1.2 缓存池 Java 基本类型的包装类的大部分都实现了常量池技术,即 Byte,Short,Integer,Long,Character,Boolean;前面 4 种包装类默认创建了数值[-128,127] 的相应类型的缓存数据,Character 创建了数值在[0,127]范围的缓存数据,Boolean 直接返回 True Or False。如果超出对应范围仍然会去创建新的对象。
new Integer(123) 与 Integer.valueOf(123) 的区别在于:
new Integer(123) 每次都会新建一个对象;
Integer.valueOf(123) 会使用缓存池中的对象 ,多次调用会取得同一个对象的引用。
1 2 3 4 5 6 Integer x = new Integer (123 );Integer y = new Integer (123 );System.out.println(x == y); Integer z = Integer.valueOf(123 );Integer k = Integer.valueOf(123 );System.out.println(z == k);
valueOf() 方法的实现比较简单,就是先判断值是否在缓存池中,如果在的话就直接返回缓存池的内容。
1 2 3 4 5 public static Integer valueOf (int i) { if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer (i); }
编译器会在自动装箱过程调用 valueOf() 方法,因此多个值相同且值在缓存池范围内的 Integer 实例使用自动装箱来创建,那么就会引用相同的对象。
1 2 3 Integer m = 123 ;Integer n = 123 ;System.out.println(m == n);
在使用这些基本类型对应的包装类型时,如果该数值范围在缓冲池范围内,就可以直接使用缓冲池中的对象。
两种浮点数类型的包装类 Float,Double 并没有实现常量池技术。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 Integer i1 = 40 ; Integer i2 = 40 ; Integer i3 = 0 ; Integer i4 = new Integer (40 ); Integer i5 = new Integer (40 ); Integer i6 = new Integer (0 ); System.out.println("i1=i2 " + (i1 == i2)); System.out.println("i1=i2+i3 " + (i1 == i2 + i3)); System.out.println("i1=i4 " + (i1 == i4)); System.out.println("i4=i5 " + (i4 == i5)); System.out.println("i4=i5+i6 " + (i4 == i5 + i6)); System.out.println("40=i5+i6 " + (40 == i5 + i6));
StackOverflow : Differences between new Integer(123), Integer.valueOf(123) and just 123
2.1.3 switch 从 Java 7 开始,可以在 switch 条件判断语句中使用 String 对象。
switch 不支持 long、float、double,是因为 switch 的设计初衷是对那些只有少数几个值的类型进行等值判断,如果值过于复杂,那么还是用 if 比较合适。
2.2 函数 2.2.1 值传递
一个方法可以修改传递引用所对应的变量值,而不能修改传递值调用所对应的变量值。
Java 程序设计语言总是采用按值调用。
对基本数据类型的调用是按值调用。和C/C++中按值调用一样 对对象的引用————本质上是将对象的地址以值的方式传递到形参中。
2.2.2 方法的重载、重写(覆盖)、隐藏 重写:前提是继承 ,子类中定义的方法与父类中的方法具有相同的方法名字、相同的参数列表、相同的返回类型(允许子类中方法的返回值是父类中方法返回值的子类),即相同的方法签名和返回类型,至于方法修饰符,需要范围相同或者比父类的范围大即可;
父类私有实例方法不能被子类覆盖
静态方法不能被覆盖,只能被隐藏
覆盖特性:一旦父类中的实例方法被子类覆盖,同时用父类型的引用变量引用了子类对象,这时不能通过这个父类型引用变量去访问被覆盖的父类方法(即这时被覆盖的父类方法不可再被发现)。因为实例方法具有多态性(晚期绑定)【强制转换都不行】
重载:同一个类中的多个方法具有相同的名字,但这些方法具有不同的参数列表或者有不同的返回类型(不管是实例方法还是静态方法)。
重写与重载之间的区别
区别点
重载方法
重写方法
参数列表
必须修改
一定不能修改
返回类型
可以修改
一定不能修改
异常
可以修改
可以减少或删除,一定不能抛出新的或者更广的异常
访问
可以修改
一定不能做更严格的限制(可以降低限制)
重写是基类与派生类之间多态性的一种表现,重载可以理解成多态的具体表现形式。【方法重载是一个类的多态性表现,而方法重写是派生类与基类的一种多态性表现。】
方法隐藏:发生在父类和子类之间,前提是继承。子类中定义的方法与父类中的方法具有相同的方法名字、相同的参数列表、相同的返回类型(也允许子类中方法的返回类型是父类中方法返回类型的子类)
方法隐藏:静态方法。如果子类中存在静态方法staticA的方法签名与父类中静态方法staticB的相同,则称staticA隐藏了staticB。
隐藏特性:指父类的变量(实例变量、静态变量)和静态方法在子类被重新定义,但由于类的变量和静态方法没有多态性,因此通过父类型引用变量访问的一定是父类变量、静态方法(即被隐藏的可再发现)。【可以通过强制类型转换】
2.2.2.1 继承和覆盖的关系 1.构造函数:
2.方法覆盖:
3.成员覆盖:当子类覆盖父类的成员变量时,父类方法使用的是父类的成员变量,子类方法使用的是子类的成员变量
2.2.3 深拷贝和浅拷贝
2.2.3.1 深拷贝 参考文章
实现Cloneable接口,然后覆写Object类中的clone方法。
Object的clone()方法是浅拷贝的。
在java语言中,使用new操作创建一个对象与使用clone方法复制一个对象有什么不同?
使用new操作创建对象本意是分配内存。程序只领到new操作符时,首先去看new操作符后面的类型,因为知道了类型,才能知道要分配多大的内存空间。分配完内存之后,再调用构造函数,填充对象的各个域,这就叫对象的初始化。对象初始化完毕后,可以把引用发布到外部,在外部就可以使用这个引用操纵这个对象。
clone在第一步和new相似的,都是分配内存的,调用clone方法时,分配的内存和源对象(即调用clone方法的对象)相同,然后在使用原对象中对应的各个域,填充新对象的域 ,填充完成之后,clone方法返回,一个新的相同对象就能被创建,同样这个新对象的引用发布到外部。因为clone没有调用构造函数,所以其对象的域的引用地址还是没有变的,也就是浅拷贝。
如果想要深拷贝一个对象, 这个对象必须要实现Cloneable接口,实现clone方法,并且在clone方法内部,把该对象引用的其他对象也要clone一份 , 这就要求这个被引用的对象必须也要实现Cloneable接口并且实现clone方法。
【有一个问题就是:要是想彻底实现深拷贝,需要把引用链上的每一级对象都显式的拷贝,很麻烦】
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 class Person implements Cloneable { String name; int age; Person(String name,int age){ this .name=name; this .age=age; } @Override public Object clone () { try { return super .clone(); }catch (CloneNotSupportedException e){ return null ; } } } class Animal implements Cloneable { Person host; int age; Animal(Person person,int age){ this .host=person; this .age=age; } @Override public Object clone () { try { Animal animal=(Animal) super .clone(); animal.host=(Person)host.clone(); return animal; }catch (CloneNotSupportedException e){ return null ; } } } public class Main { public static void main (String[] args) { Person person1=new Person ("cxh" ,26 ); Person person2=(Person)person1.clone(); System.out.println("----------------浅拷贝--------------" ); System.out.println("person1和person2的name内存地址是否相同:" +(person1.name==person2.name)); System.out.println("----------------深拷贝--------------" ); Animal animal1=new Animal (new Person ("cxh" ,26 ),3 ); Animal animal2=(Animal) animal1.clone(); System.out.println("animal1和animal2的host内存地址是否相同:" +(animal1.host==animal2.host)); } } 输出: ----------------浅拷贝-------------- person1和person2的name内存地址是否相同:true ----------------深拷贝-------------- animal1和animal2的host内存地址是否相同:false Process finished with exit code 0
2.2.3.2 Serializable接口 通过序列化方式实现深拷贝:先将要拷贝对象写入到内存中的字节流中,然后再从这个字节流中读出刚刚存储的信息,作为一个新对象返回,那么这个新对象和原对象就不存在任何地址上的共享,自然实现了深拷贝。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 import java.io.*; class CloneUtil public static <T extends Serializable> T clone(T obj){ T cloneObj=null ; try { ByteArrayOutputStream baos=new ByteArrayOutputStream (); ObjectOutputStream oos=new ObjectOutputStream (baos); oos.writeObject(obj); oos.close(); ByteArrayInputStream bais=new ByteArrayInputStream (baos.toByteArray()); ObjectInputStream ois=new ObjectInputStream (bais); cloneObj=(T)ois.readObject(); ois.close(); }catch (Exception e){ e.printStackTrace(); } return cloneObj; } } class Person implements Serializable String name; int age; Person(String name,int age){ this .name=name; this .age=age; } } class Animal implements Serializable Person host; int age; Animal(Person person,int age){ this .host=person; this .age=age; } } public class Main public static void main(String [] args) { System.out.println("----------------深拷贝--------------" ); Animal animal1=new Animal (new Person ("cxh" ,26 ),3 ); Animal animal2=CloneUtil.clone(animal1); System.out.println("animal1和animal2的host内存地址是否相同:" +(animal1.host==animal2.host)); } } 输出: ----------------深拷贝-------------- animal1和animal2的host内存地址是否相同:false
2.2.3.3 深浅拷贝存在的问题 浅拷贝:对象值拷贝,对于拷贝而言,拷贝出来的对象仍然保留原对象的所有引用
2.3 关键字 2.3.1 final关键字 final修饰类:表示这个类不能被继承。
final修饰方法:父类的final方法是不可以被子类继承重写的。
如果父类中的final方法是public修饰的,子类可以继承到此方法,子类会重写此方法,将会导致编译出错
如果父类中的final方法是private修饰的,子类继承不到此方法,这时子类可以定义一个和父类中的final方法相同的方法,因为这个方法是属于子类重新定义的,所以编译不会出错
final修饰变量:final成员变量表示常量,一但被赋值,值不可以再被改变
对于基本类型,final 使数值不变;
对于引用类型,final 使其在初始化之后不能再指向其他对象,但是对象的内容是可以改变的。
2.3.2 static关键字 static关键字作用:在没有创建对象的情况下来调用方法/变量
static修饰的方法或变量不需要依赖对象进行访问,只要类被加载了就可以
static修饰方法:静态方法;
static修饰变量:静态变量,静态变量可以被所有对象共享。但是不能修饰局部变量
JVM只为静态分配一次内存,在加载类的过程中完成静态变量的内存分配。对于实例变量,每创建一个实例,JVM就为实例变量分配一次内存。放在方法区中(方法区包含所有的class和static变量)【和堆一样,被所有线程共享】
static修饰代码块::只会在类加载的时候执行一次。
final和static关键字
final强调的是不能改变,不能继承和重写 ;
static强调的是只有一个 ,可以直接使用 ,可以在初始化进行改变。它把某些和具体对象无关的东西剥离出来。
只能访问所属类的静态字段和静态方法,方法中不能有 this 和 super 关键字,因此这两个关键字与具体对象关联。
1 2 3 4 5 6 7 8 9 10 11 public class A { private static int x; private int y; public static void func1 () { int a = x; } }
final static 和static final关键字
static final和final static没什么区别,一般static写在前面。
static修饰的属性强调它们只有一个,final修饰的属性表明是一个常数(创建后不能被修改)。static final修饰的属性表示一旦给值,就不可修改,并且可以通过类名访问。
static final也可以修饰方法,表示该方法不能重写,可以在不new对象的情况下调用
2.4 String String 被声明为 final,因此它不可被继承。(Integer 等包装类也不能被继承)
不可变的好处:
1. 可以缓存 hash 值
因为 String 的 hash 值经常被使用,例如 String 用做 HashMap 的 key。不可变的特性可以使得 hash 值也不可变,因此只需要进行一次计算。
2. String Pool 的需要
如果一个 String 对象已经被创建过了,那么就会从 String Pool 中取得引用。只有 String 是不可变的,才可能使用 String Pool。
3. 安全性
String 经常作为参数,String 不可变性可以保证参数不可变。例如在作为网络连接参数的情况下如果 String 是可变的,那么在网络连接过程中,String 被改变,改变 String 的那一方以为现在连接的是其它主机,而实际情况却不一定是。
4. 线程安全
String 不可变性天生具备线程安全,可以在多个线程中安全地使用。
2.4.1 String, StringBuffer and StringBuilder 可变性:
String 不可变
使用 final 关键字修饰字符数组来保存字符串,private final char value[]
StringBuffer 和 StringBuilder 可变
继承自 AbstractStringBuilder类,在AbstractStringBuilder 中也是使用字符数组保存字符串char[]value但是没有用 final关键字修饰
线程安全性:
String 不可变,因此是线程安全的
StringBuilder 不是线程安全的
StringBuffer 是线程安全的,内部使用 synchronized 进行同步
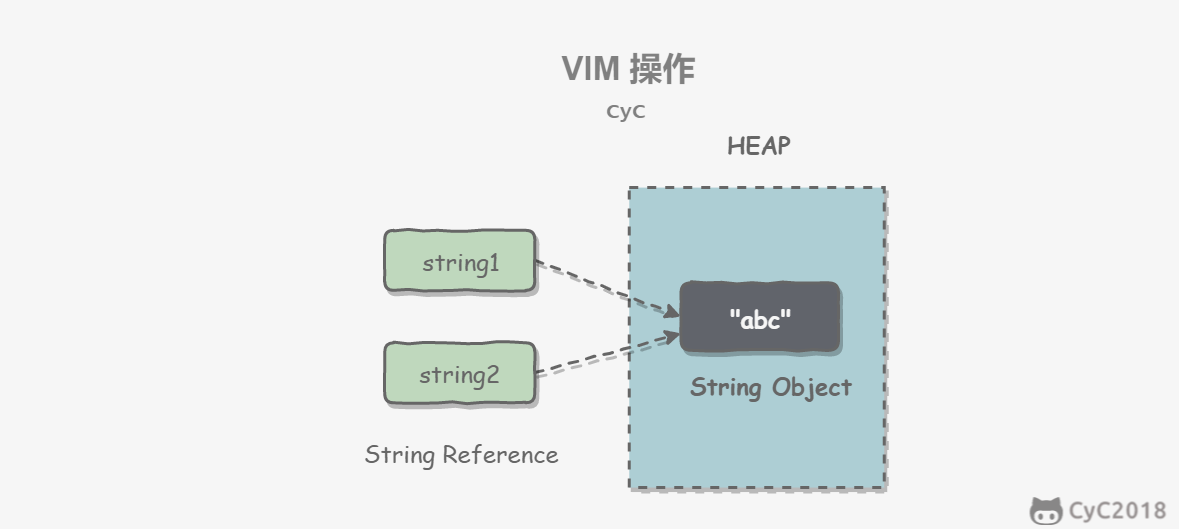
2.4.2 String Pool 字符串常量池(String Pool)保存着所有字符串字面量(literal strings),这些字面量在编译时期就确定。不仅如此,还可以使用 String 的 intern() 方法在运行过程将字符串添加到 String Pool 中。
当一个字符串调用 intern() 方法时,如果 String Pool 中已经存在一个字符串和该字符串值相等(使用 equals() 方法进行确定),那么就会返回 String Pool 中字符串的引用;否则,就会在 String Pool 中添加一个新的字符串,并返回这个新字符串的引用。
下面示例中,s1 和 s2 采用 new String() 的方式新建了两个不同字符串,而 s3 和 s4 是通过 s1.intern() 和 s2.intern() 方法取得同一个字符串引用。intern() 首先把 “aaa” 放到 String Pool 中,然后返回这个字符串引用,因此 s3 和 s4 引用的是同一个字符串。
1 2 3 4 5 6 String s1 = new String ("aaa" );String s2 = new String ("aaa" );System.out.println(s1 == s2); String s3 = s1.intern();String s4 = s2.intern();System.out.println(s3 == s4);
如果是采用 “bbb” 这种字面量的形式创建字符串,会自动地将字符串放入 String Pool 中。
1 2 3 String s5 = "bbb" ;String s6 = "bbb" ;System.out.println(s5 == s6);
在 Java 7 之前,String Pool 被放在运行时常量池中,它属于永久代。而在 Java 7,String Pool 被移到堆中。这是因为永久代的空间有限,在大量使用字符串的场景下会导致 OutOfMemoryError 错误。
2.4.3 new String(“abc”)问题 使用这种方式一共会创建两个字符串对象(前提是 String Pool 中还没有 “abc” 字符串对象)。
“abc” 属于字符串字面量,因此编译时期会在 String Pool 中创建一个字符串对象,指向这个 “abc” 字符串字面量;
而使用 new 的方式会在堆中创建一个字符串对象。
2.5 Object 通用方法 Object 类是一个特殊的类,是所有类的父类。它主要提供了以下 11 个方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public final native Class<?> getClass()public native int hashCode () public boolean equals (Object obj) protected native Object clone () throws CloneNotSupportedExceptionpublic String toString () public final native void notify () public final native void notifyAll () public final native void wait (long timeout) throws InterruptedExceptionpublic final void wait (long timeout, int nanos) throws InterruptedExceptionpublic final void wait () throws InterruptedExceptionprotected void finalize () throws Throwable { }
2.5.1 equals()和==(重要) == : 它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象(基本数据类型==比较的是值,引用数据类型==比较的是内存地址)。
equals() : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
情况 1:类没有覆盖 equals() 方法。则通过 equals() 比较该类的两个对象时,等价于通过“==”比较这两个对象。
情况 2:类覆盖了 equals() 方法。一般,我们都覆盖 equals() 方法来比较两个对象的内容是否相等;若它们的内容相等,则返回 true (即,认为这两个对象相等)。
String 中的 equals 方法是被重写过的,因为 object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。
当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象。
2.5.2 equals()和hashcode(重要) 2.5.3 clone() clone() 是 Object 的 protected 方法,它不是 public,一个类不显式去重写 clone(),其它类就不能直接去调用该类实例的 clone() 方法。
Cloneable 接口只是规定,如果一个类没有实现 Cloneable 接口又调用了 clone() 方法,就会抛出 CloneNotSupportedException。
2.6 类 2.6.1 成员变量与局部变量的区别有哪些?
从语法形式上看:成员变量是属于类的,而局部变量是在代码块或方法中定义的变量或是方法的参数;成员变量可以被 public,private,static 等修饰符所修饰,而局部变量不能被访问控制修饰符及 static 所修饰;但是,成员变量和局部变量都能被 final 所修饰。
从变量在内存中的存储方式来看:如果成员变量是使用static修饰的,那么这个成员变量是属于类的 ,如果没有使用static修饰,这个成员变量是属于实例的 。而对象存在于堆内存,局部变量则存在于栈内存。
从变量在内存中的生存时间上看:成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动消失。
成员变量如果没有被赋初值:则会自动以类型的默认值而赋值(一种情况例外:被 final 修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值。
2.6.2 new运算符 new 运算符,new 创建对象实例(对象实例在堆内存中 ),对象引用指向对象实例(对象引用存放在栈内存中 )。
在java语言中,使用new操作创建一个对象与使用clone方法复制一个对象有什么不同?
使用new操作创建对象本意是分配内存。程序只领到new操作符时,首先去看new操作符后面的类型,因为知道了类型,才能知道要分配多大的内存空间。分配完内存之后,再调用构造函数,填充对象的各个域,这就叫对象的初始化。对象初始化完毕后,可以把引用发布到外部,在外部就可以使用这个引用操纵这个对象。
clone在第一步和new相似的,都是分配内存的,调用clone方法时,分配的内存和源对象(即调用clone方法的对象)相同,然后在使用原对象中对应的各个域,填充新对象的域 ,填充完成之后,clone方法返回,一个新的相同对象就能被创建,同样这个新对象的引用发布到外部。因为clone没有调用构造函数,所以其对象的域的引用地址还是没有变的,也就是浅拷贝。
2.6.3 对象的相等与指向他们的引用相等,两者有什么不同? 对象的相等,比的是内存中存放的内容是否相等。而引用相等,比较的是他们指向的内存地址是否相等。
2.6.4 内部类 是在一个类的内部定义的类。仅能被其外部类使用,但是又不想暴露的类,我们一般都会定义为内部类。
内部类作用:如果一个类A仅仅被某一个类B使用,且A无需暴露出去,可以把A作为B的内部类实现,内部类也可以避免名字冲突:因为外部类多了一层名字空间的限定。例如类Wrapper1、Wrapper2可以定义同名的内部类A而不会导致冲突
2.6.4.1 内部静态类和内部实例类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 class Wrapper { private int x=0 ; private static int z = 0 ; static class A { int y=0 ; static int q=0 ; int g () { return ++q + ++y + ++z; } } class B { int y=0 ; static int q=0 ; public int g ( ) { x++; y++;z++; return x+y; } public int getX () {return x;} } } public static void main (String[] args) { Wrapper w = new Wrapper (); Wrapper.A a = new Wrapper .A(); Wrapper.A b = new Wrapper .A(); a.g(); Wrapper.B c = w.new B (); c.y=0 ; c.g(); System.out.println(c.getX()); }
2.6.4.2 方法内部类 顾名思义,就是定义在外部类的方法中的内部类。
方法内部类只在该方法内可以使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Outer { private static String msg="hello world!" ; public void fun (int num) { class Inner { public void print () { System.out.println("msg = " +msg); System.out.println("num = " +num); } } new Inner ().print(); } } public class TestDemo { public static void main (String args[]) { new Outer ().fun(100 ); } }
由于方法内部类不能在外部类的方法以外的地方使用,因此方法内部类不能使用访问控制符和 static 修饰符。
2.6.4.3 匿名内部类 没有名字的内部类。所以匿名内部类不可能有构造函数(没有类名),不能创建对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class Anonymous { public void test (Product p) { System.out.println(p.getName()+"--------" +p.getPrice()); } public static void main (String [ ] args ) { Anonymous as= new Anonymous (); as.test(new Product ( ) { public double getPrice ( ) { return 8888 ; } public String getName ( ) { return "I can do it " ; } }); } }
主要是方便偷懒。
2.6.5 枚举类 1.所有枚举类型都是Enum类的子类。例如:public enum color{a,b}
2.这些枚举类型继承了enum类的方法。
3.可以在枚举类型中添加一些构造器、方法和域。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public enum Color { RED("红色" , 1 ), GREEN("绿色" , 2 ), BLANK("白色" , 3 ), YELLO("黄色" , 4 ); private String name ; private int index ; private Color ( String name , int index ) { this .name = name ; this .index = index ; } public String getName () { return name; } public void setName (String name) { this .name = name; } public int getIndex () { return index; } public void setIndex (intindex) { this .index = index; } }
3、三大特征 3.1 继承 关于继承如下 3 点请记住:
子类拥有父类对象所有的属性和方法(包括私有属性和私有方法),但是父类中的私有属性和方法子类是无法访问,只是拥有 。
子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
子类可以用自己的方式实现父类的方法。
3.1.1 接口和抽象类 3.1.1.1 抽象类 抽象类的使用原则如下:
abstract 关键字,和哪些关键字不能共存。final: 被final修饰的类不能有子类(不能被继承)。而被abstract修饰的类一定是一个父类(一定要被继承)。private: 抽象类中的私有的抽象方法,不被子类所知,就无法被复写。static: 如果static可以修饰抽象方法,那么连对象都省了,直接类名调用就可以了。
抽象类的成员特点:
成员变量:既可以是变量也可以是常量
构造方法:用于子类访问父类的初始化
成员方法:既可以是抽象的,也可以是非抽象的【只有实例方法才能成为抽象方法】
抽象类的成员方法特性:
A:抽象方法,强制要求子类去做的事情
B:非抽象方法 子类继承的事情,提高代码复用性
3.1.1.2 接口 接口是公共静态常量和公共抽象实例方法 的集合。接口是能力、规范、协议的反映。
接口中的所有数据字段隐含为public static final
接口体中的所有方法隐含为public abstract
接口不是类:
(1)不能定义构造函数;
注意事项:
接口不能实例化,因为接口是比抽象类抽象程度更高的类型
一个类如果实现了某个接口,必须重写该接口中的所有方法
接口中所有方法都公有的抽象方法
接口中的所有字段必须都是公有的静态常量
接口本身也是一种数据类型
接口只是为实现它的类定义了规范,保证实现类方法签名和接口中对应方法一致。
通过接口可以实现多继承
一个接口中最好只定义一个方法,防止接口污染
存在的意义:
1、重要性 :在Java语言中, abstract class 和interface 是支持抽象类定义的两种机制。正是由于这两种机制的存在,才赋予了Java强大的 面向对象能力。
2、简单、规范性 :如果一个项目比较庞大,那么就需要一个能理清所有业务的架构师来定义一些主要的接口,这些接口不仅告诉开发人员你需要实现那些业务,而且也将命名规范限制住了(防止一些开发人员随便命名导致别的程序员无法看明白)。
3、维护、拓展性 :比如你要做一个画板程序,其中里面有一个面板类,主要负责绘画功能,然后你就这样定义了这个类。
4、安全、严密性 :接口是实现软件松耦合的重要手段,它描叙了系统对外的所有服务,而不涉及任何具体的实现细节。这样就比较安全、严密一些(一般软件服务商考虑的比较多)。
3.1.1.3 抽象类和接口比较
接口是隐式抽象的,当声明一个接口的时候,不必使用abstract关键字
接口中每一个方法也是隐式抽象的,声明时同样不需要abstract关键字
接口中的方法都是公有的
编译时自动为接口里定义的方法添加public abstract修饰符
Java接口里的成员变量只能是public static final共同修饰的,并且必须赋初始值,可以不写public static final,编译的时候会自动添加
1 2 3 4 5 6 7 8 9 public interface Temo { int INT_A = 11 ; public final static int INT_B = 11 ; void sleep () ; public abstract void running () ; void test () ; }
3.1.1.4 接口与抽象类的区别 接口(interface)和抽象类(abstract class)是支持抽象类定义的两种机制。
接口(interface)和抽象类(abstract class)是支持抽象类定义的两种机制。
接口是公开的,不能有私有的方法或变量,接口中的所有方法都没有方法体,通过关键字interface实现。
抽象类是可以有私有方法或私有变量的,通过把类或者类中的方法声明为abstract来表示一个类是抽象类,被声明为抽象的方法不能包含方法体。子类实现方法必须含有相同的或者更低的访问级别(public->protected->private)。抽象类的子类为父类中所有抽象方法的具体实现,否则也是抽象类。
接口可以被看作是抽象类的变体,接口中所有的方法都是抽象的,可以通过接口来间接的实现多重继承 。接口中的成员变量都是static final类型,由于抽象类可以包含部分方法的实现,所以,在一些场合下抽象类比接口更有优势。
接口可以多继承接口 ,抽象类不可以
如果接口声明中提供了extends子句,那么该接口就继承了父接口的方法和常量。被继承的接口称为声明接口的直接父接口。
任何实现该接口的类,必须实现该接口继承的其他接口。
接口需要被子类实现,抽象类是被子类继承(单一继承)
接口中只能有公有的方法和属性而且必须赋初始值 ,抽象类的方法一般是不能用private修饰的【因为子类继承的时候无法覆写,没有意义】
接口中不能存在静态方法,但是属性可以是final,抽象类中方法中可以有静态方法,属性也可以
不允许被扩展的类被称为final类。类中不想被覆盖的方法也可以使用关键字final
接口被用于常用的功能,便于日后维护和添加删除,而抽象类更倾向于充当公共类的角色,不适用于日后重新对立面的代码修改。功能需要累积时用抽象类,不需要累积时用接口。
3.1.1.5 接口与抽象类的相同点
都不能 被实例化
接口的实现类或抽象类的子类都只有实现了接口或抽象类中的方法后 才能实例化。
接口 抽象类
多重继承
一个接口可以继承多个接口
一个类只能继承(extends)一个抽象类
方法
接口不能提供任何代码
抽象类的非抽象函数可以提供完整代码
数据字段
只包含public static final常量,常量必须在声明时初始化。
可以包含实例变量和静态变量以及实例和静态常量。
含义
接口通常用于描述一个类的外围能力,而不是核心特征。类与接口之间的是-able或者can do的关系,有instanceof关系(实现了接口的具体类对象也是接口类型的实例)。
抽象类定义了它的后代的核心特征。例如Person类包含了Student类的核心特征。子类与抽象类之间是is-a的关系,也有instanceof关系(子类对象也是父类实例)。
简洁性
接口中的常量都被假定为public static final,可以省略。不能调用任何方法修改这些常量的初始值。接口中的方法被假定为public abstract。
可以在抽象类中放置共享代码。可以使用方法来修改实例和静态变量的初始值,但不能修改实例和静态常量的初始值。必须用abstract显式声明方法为抽象方法。
添加功能
如果为接口添加一个新的方法,则必须查找所有实现该接口的类,并为他们逐一提供该方法的实现,即使新方法没有被调用。
如果为抽象类提供一个新方法,可以选择提供一个缺省的实现,那么所有已存在的代码不需要修改就可以继续工作,因为新方法没有被调用。
3.1.2 this和super 1、引用构造函数
super(参数):调用父类中的某一个构造函数(应该为构造函数中的第一条语句)。
为什么在实例化子类的对象时,要调用父类的构造器?
子类在继承父类后,获取到父类的属性和方法,这些属性和方法必须先初始化再使用,所以需要先调用父类的构造器。
this(参数):调用本类中另一种形式的构造函数(应该为构造函数中的第一条语句)。
super和this的异同:
super(参数):调用基类中的某一个构造函数(应该为构造函数中的第一条语句)
this(参数):调用本类中另一种形成的构造函数(应该为构造函数中的第一条语句)
super: 它引用当前对象的直接父类中的成员(用来访问直接父类中被隐藏的父类中成员数据或函数,基类与派生类中有相同成员定义时如:super.变量名 super.成员函数据名(实参)
this:它代表当前对象名(在程序中易产生二义性之处,应使用this来指明当前对象;如果函数的形参与类中的成员数据同名,这时需用this来指明成员变量名)
调用super()必须写在子类构造方法的第一行,否则编译不通过。每个子类构造方法的第一条语句,都是隐含地调用super(),如果父类没有这种形式的构造函数,那么在编译的时候就会报错。
super()和this()类似,区别是,==super()从子类中调用父类的构造方法,this()在同一类内调用其它方法。==
super()和this()均需放在构造方法内第一行。
尽管可以用this调用一个构造器,但却不能调用两个。
this和super不能同时出现在一个构造函数里面,因为this必然会调用其它的构造函数,其它的构造函数必然也会有super语句的存在,所以在同一个构造函数里面有相同的语句,就失去了语句的意义,编译器也不会通过。
this()和super()都指的是对象,所以,均不可以在static环境中使用。包括:static变量,static方法,static语句块。
从本质上讲,this是一个指向本对象的指针, 然而super是一个Java关键字。
3.2 多态 多态一般分为两种:重写式多态和重载式多态。重写和重载这两个知识点前面的文章已经详细将结果了,这里就不多说了。
重载式多态,也叫编译时多态 。也就是说这种多态再编译时已经确定好了。重载大家都知道,方法名相同而参数列表不同的一组方法就是重载。在调用这种重载的方法时,通过传入不同的参数最后得到不同的结果。【感觉这就不叫是多态】
重写式多态,也叫运行时多态。这种多态通过动态绑定 (dynamic binding)技术来实现,是指在执行期间判断所引用对象的实际类型,根据其实际的类型调用其相应的方法 。也就是说,只有程序运行起来,你才知道调用的是哪个子类的方法。
其实多态就是父类可以使用其子类的方法(当然,该方法是子类覆写父类的方法)。这就是所谓的动态调用
多态就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定 ,即一个引用变量倒底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。因为在程序运行时才确定具体的类,这样,不用修改源程序代码,就可以让引用变量绑定到各种不同的类实现上,从而导致该引用调用的具体方法随之改变,即不修改程序代码就可以改变程序运行时所绑定的具体代码,让程序可以选择多个运行状态,这就是多态性。
3.2.1 向上转型 子类引用的对象转换为父类类型称为向上转型。通俗地说就是是将子类对象转为父类对象。此处父类对象可以是接口。
转型过程中需要注意的问题
向上转型的好处
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public class Animal { public void eat () { System.out.println("animal eatting..." ); } } public class Cat extends Animal { public void eat () { System.out.println("我吃鱼" ); } } public class Dog extends Animal { public void eat () { System.out.println("我吃骨头" ); } public void run () { System.out.println("我会跑" ); } } public class Main { public static void main (String[] args) { Animal animal = new Cat (); animal.eat(); animal = new Dog (); animal.eat(); } }
1 Animal animal = new Cat ();
成员变量
编译看左边(基类),运行看左边(基类);无论如何都是访问基类的成员变量。
成员方法
编译看左边(基类),运行看右边(派生类),动态绑定。
Static方法
编译看左边(基类),运行看左边(基类)。
只有非静态的成员方法,编译看左边,运行看右边。
这样,我们也可以得出多态的局限:
不能使用派生类特有的成员属性和派生类特有的成员方法。
3.2.2 向下转型
向下转型的前提是父类对象指向的是子类对象(也就是说,在向下转型之前,它得先向上转型)
向下转型只能转型为本类对象(猫是不能变成狗的)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public void eat (Animal a) { if (a instanceof Dog){ Dog d = (Dog)a; d.eat(); d.run(); } if (a instanceof Cat){ Cat c = (Cat)a; c.eat(); System.out.println("我也想跑,但是不会" ); } a.eat(); } eat(new Cat ()); eat(new Cat ()); eat(new Dog ());
3.2.3 动态绑定和静态绑定 o当调用实例方法时,由Java虚拟机动态地决定所调用的方法,称为动态绑定(dynamic binding)或者晚期绑定或者延迟绑定(lazy binding)或者多态。
假定对象o是类C1的实例,C1是C2的子类,C2是C3的子类,…,Cn-1是Cn的子类。也就是说,Cn是最一般的类,C1是最具体的类。在Java中,Cn是Object类。如果调用继承链里子类型C1对象o的方法p,Java虚拟机按照C1、C2、…、Cn的顺序依次查找方法p的实现。一旦找到一个实现,将停止查找,并执行找到的第一个实现(覆盖的实例函数)。
静态绑定是在程序执行前就已经被绑定了(也就是在程序编译过程中就已经知道这个方法是哪个类中的方法)。
java当中的方法只有final、static、private修饰的方法和构造方法是静态绑定的。
private修饰的方法:private修饰的方法是不能被继承的,因此子类无法访问父类中private修饰的方法。所以只能通过父类对象来调用该方法体。因此可以说private方法和定义这个方法的类绑定在了一起。
final修饰的方法:可以被子类继承,但是不能被子类重写(覆盖),所以在子类中调用的实际是父类中定义的final方法。(使用final修饰方法的两个好处:(1)防止方法被覆盖;(2)关闭java中的动态绑定)。
static修饰的方法:可以被子类继承,但是不能被子类重写(覆盖),但是可以被子类隐藏。(这里意思是说如果父类里有一个static方法,它的子类里如果没有对应的方法,那么当子类对象调用这个方法时就会使用父类中的方法,而如果子类中定义了相同的方法,则会调用子类中定义的方法,唯一的不同就是:当子类对象向上类型转换为父类对象时,不论子类中有没有定义这个静态方法,该对象都会使用父类中的静态方法,因此这里说静态方法可以被隐藏而不能被覆盖。这与子类隐藏父类中的成员变量是一样的。隐藏和覆盖的区别在于,子类对象转换成父类对象后,能够访问父类被隐藏的变量和方法,而不能访问父类被覆盖的方法)。
构造方法:构造方法也是不能被继承的(因为子类是通过super方法调用父类的构造函数,或者是jvm自动调用父类的默认构造方法),因此编译时也可以知道这个构造方法方法到底是属于哪个类的。
因此,一个方法被继承,或者是被继承后不能被覆盖,那么这个方法就采用静态绑定
java中重载的方法使用静态绑定,重写的方法使用动态绑定。
3.2.4 多态的一道例子 参考文章
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 class A { public String show (D obj) { return ("A and D" ); } public String show (A obj) { return ("A and A" ); } } class B extends A { public String show (B obj) { return ("B and B" ); } public String show (A obj) { return ("B and A" ); } } class C extends B {} class D extends B {} public class Demo { public static void main (String[] args) { A a1 = new A (); A a2 = new B (); B b = new B (); C c = new C (); D d = new D (); System.out.println("1--" + a1.show(b)); System.out.println("2--" + a1.show(c)); System.out.println("3--" + a1.show(d)); System.out.println("4--" + a2.show(b)); System.out.println("5--" + a2.show(c)); System.out.println("6--" + a2.show(d)); System.out.println("7--" + b.show(b)); System.out.println("8--" + b.show(c)); System.out.println("9--" + b.show(d)); } }
继承链中对象方法的调用的优先级:this.show(O)、super.show(O)、this.show((super)O)、super.show((super)O)
先方法,后对象this.show(O)、super.show(O)、this.show((super)O)、super.show((super)O)
4、java其他知识 4.1 lambda表达式 编译器会把lambda表达式看待成是匿名内部类对象。
Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中,函数式编程思想)。
1 2 3 4 5 6 7 8 9 10 11 12 13 btEnlarge.setOnAction( new EventHandler <ActionEvent>() { @Override public void handle (ActionEvnt e) { }); btEnlarge.setOnAction(e->{ });
java里规定Lambda表达式只能赋值给函数式接口。
lambda 表达式的语法格式如下:
(parameters) -> expression 或 (parameters) ->{ statements; }
【这其中:1.parameters是参数列表,和方法中的参数列表是一个意思。
4.2 初始化模块 初始化块是Java类中可以出现的第四种成员(前三种包括属性、方法、构造函数),分为实例初始化块和静态初始化块。
4.2.1 实例初始化模块 实例初始化模块(instance initialization block,IIB)是一个用大括号括住的语句块,直接嵌套于类体中,不在方法内。
一个类可以有多个初始化模块,模块按照在类中出现的顺序执行
作用:
简单的来说,就是初始化对象,实例初始化块优先于构造函数执行 。
如果多个构造方法共享一段代码,并且每个构造方法不会调用其他构造方法,那么可以把这段公共代码放在初始化模块中。(感觉用处不大)
初始化模块可以简化构造方法
实例初始化模块可以截获异常
1 2 3 4 5 6 7 8 9 10 public class A { private InputStream fs = null ; { try { fs = new FileInputStream (new File (“C:\\1. txt”));} catch (Exception e){ …} } public A () { … } }
实例初始化模块最重要的作用是当我们需要写一个内部匿名类时:匿名类不可能有构造函数,这时可以用实例初始化块来初始化数据成员
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 interface ISay { public abstract void sayHello () ; }public class InstanceInitializationBlockTest { public static void main (String[] args) { ISay say = new ISay () { private final int j; { j = 0 ; } @Override public void sayHello () { System.out.println("Hello" ); } }; say.sayHello(); } }
4.2.2 静态初始化模块 静态初始化模块是由static修饰的初始化模块{},只能访问类的静态成员,并且在JVM的Class Loader将类装入内存时调用。(类的装入和类的实例化是两个不同步骤,首先是将类装入内存,然后再实例化类的对象)。
在类体里直接定义静态变量相当于静态初始化块。
1 2 3 4 5 6 7 8 9 10 public class A { { } static { } public static int i = 0 ; }
一个类可以有多个静态初始化块,类被加载时,这些模块按照在类中出现的顺序执行
初始化模块执行顺序 :
第一次使用类时装入类
如果父类没装入则首先装入父类,这是个递归的过程,直到继承链上所有祖先类全部装入
实例化类的对象
首先构造父类对象,这是个递归过程,直到继承链上所有祖先类的对象构造好
4.3 异常处理 以下三种类型的异常:
1、检查性异常:最具代表的检查性异常是用户错误或问题引起的异常,这是程序员无法预见的。例如要打开一个不存在文件时,一个异常就发生了,这些异常在编译时不能被简单地忽略。
2、运行时异常: 运行时异常是可能被程序员避免的异常。与检查性异常相反,运行时异常可以在编译时被忽略。
3、错误: 错误不是异常,而是脱离程序员控制的问题。错误在代码中通常被忽略。例如,当栈溢出时,一个错误就发生了,它们在编译也检查不到的。
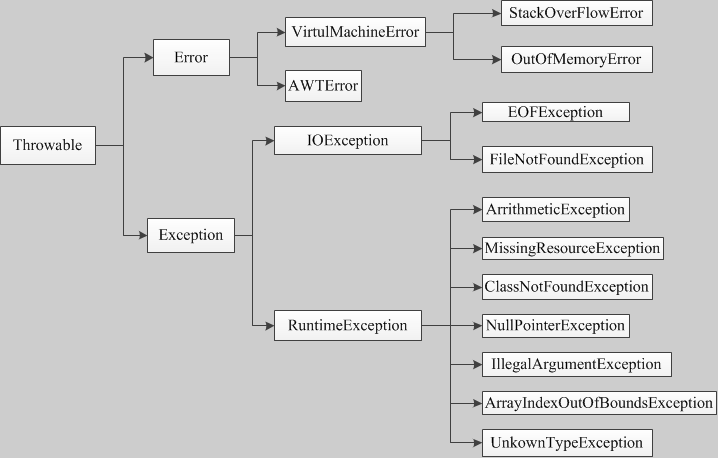
4.3.1 异常的体系结构
在Java API中已经定义了许多异常类,这些异常类分为两大类,错误Error和异常Exception。
可以看出所有异常类型都是内置类Throwable的子类 ,因而Throwable在异常类的层次结构的顶层。
4.3.2 Error和Exception error:表示不希望被程序捕获或者是程序无法处理的错误。
Exception:表示用户程序可能捕捉的异常情况或者说是程序可以处理的异常。
Exception又分为运行时异常(RuntimeException)和非运行时异常。划分的依据是由程序错误导致的异常是RuntimeException;(除了RuntimeException及其子类以外,其他的Exception类及其子类都属于检查异常,当程序中可能出现这类异常,要么使用try-catch语句进行捕获,要么用throws子句抛出,否则编译无法通过。 也可以说RuntimeException异常一定是自己的问题)程序本身没有问题的其他异常是非运行时异常。
【不受检查异常(Error类和RuntimeException类)为编译器不要求强制处理的异常,检查异常则是编译器要求必须处置的异常。】
下面将详细讲述这些异常之间的区别与联系:
Error:Error类对象由 Java 虚拟机生成并抛出,大多数错误与代码编写者所执行的操作无关。例如,Java虚拟机运行错误(Virtual MachineError),当JVM不再有继续执行操作所需的内存资源时,将出现 OutOfMemoryError。这些异常发生时,Java虚拟机(JVM)一般会选择线程终止;还有发生在虚拟机试图执行应用时,如类定义错误(NoClassDefFoundError)、链接错误(LinkageError)。这些错误是不可查的,因为它们在应用程序的控制和处理能力之 外,而且绝大多数是程序运行时不允许出现的状况。对于设计合理的应用程序来说,即使确实发生了错误,本质上也不应该试图去处理它所引起的异常状况。在Java中,错误通常是使用Error的子类描述。
Exception:在Exception分支中有一个重要的子类RuntimeException(运行时异常),该类型的异常自动为你所编写的程序定义ArrayIndexOutOfBoundsException(数组下标越界)、NullPointerException(空指针异常)、ArithmeticException(算术异常)、MissingResourceException(丢失资源)、ClassNotFoundException(找不到类)等异常,这些异常是不检查异常,程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生;而RuntimeException之外的异常我们统称为非运行时异常,类型上属于Exception类及其子类,从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如IOException、SQLException等以及用户自定义的Exception异常,一般情况下不自定义检查异常。
Error和Exception的区别:Error通常是灾难性的致命的错误,是程序无法控制和处理的,当出现这些异常时,Java虚拟机(JVM)一般会选择终止线程;Exception通常情况下是可以被程序处理的,并且在程序中应该尽可能的去处理这些异常。
4.3.3 抛出异常和捕获异常 抛出异常:要理解抛出异常,首先要明白什么是异常情形(exception condition),它是指阻止当前方法或作用域继续执行的问题。其次把异常情形和普通问题相区分,普通问题是指在当前环境下能得到足够的信息,总能处理这个错误。对于异常情形,已经无法继续下去了,因为在当前环境下无法获得必要的信息来解决问题,你所能做的就是从当前环境中跳出,并把问题提交给上一级环境,这就是抛出异常时所发生的事情。抛出异常后,会有几件事随之发生。首先,是像创建普通的java对象一样将使用new在堆上创建一个异常对象 ;然后,当前的执行路径(已经无法继续下去了)被终止,并且从当前环境中弹出对异常对象的引用 。此时,异常处理机制接管程序 ,并开始寻找一个恰当的地方继续执行程序,这个恰当的地方就是异常处理程序或者异常处理器 ,它的任务是将程序从错误状态中恢复,以使程序要么换一种方式运行,要么继续运行下去。
捕获异常:在方法抛出异常之后,运行时系统将转为寻找合适的异常处理器(exception handler) 。潜在的异常处理器是异常发生时依次存留在调用栈中的方法的集合 。当异常处理器所能处理的异常类型与方法抛出的异常类型相符时,即为合适的异常处理器。运行时系统从发生异常的方法开始,依次回查调用栈中的方法,直至找到含有合适异常处理器的方法并执行。当运行时系统遍历调用栈而未找到合适的异常处理器,则运行时系统终止 。同时,意味着Java程序的终止。
对于运行时异常、错误和检查异常,Java技术所要求的异常处理方式有所不同。
由于运行时异常及其子类的不可查性,为了更合理、更容易地实现应用程序,Java规定,运行时异常将由Java运行时系统自动抛出,允许应用程序忽略运行时异常 。
对于方法运行中可能出现的Error,当运行方法不欲捕捉时,Java允许该方法不做任何抛出声明。因为,大多数Error异常属于永远不能被允许发生的状况,也属于合理的应用程序不该捕捉的异常。
对于所有的检查异常,Java规定:一个方法必须捕捉,或者声明抛出方法之外。也就是说,当一个方法选择不捕捉检查异常时,它必须声明将抛出异常。
4.3.4 异常关键字
try – 用于监听。将要被监听的代码(可能抛出异常的代码)放在try语句块之内,当try语句块内发生异常时,异常就被抛出。
catch – 用于捕获异常。catch用来捕获try语句块中发生的异常。
finally – finally语句块总是会被执行 。它主要用于回收在try块里打开的物力资源(如数据库连接、网络连接和磁盘文件)。只有finally块,执行完成之后,才会回来执行try或者catch块中的return或者throw语句,如果finally中使用了return或者throw等终止方法的语句,则就不会跳回执行,直接停止。
如果抛出异常,即使没有catch子句匹配,finally也会执行 。一个方法将从一个try/catch块返回到调用程序的任何时候,经过一个未捕获的异常或者是一个明确的返回语句,finally子句在方法返回之前仍将执行。这在关闭文件句柄和释放任何在方法开始时被分配的其他资源是很有用。
finally子句是可选项,可以有也可以无,但是每个try语句至少需要一个catch或者finally子句。
如果finally块与一个try联合使用,finally块将在try结束之前执行
throw – 用于抛出异常。
throws – 用在方法签名中,用于声明该方法可能抛出的异常。
4.3.5 异常声明、抛出和捕获 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class ThrowDeclaration1 { public void m1 () { try { } catch (Throwable e){ } } public void m2 () { m1(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class ThrowDeclaration2 { public void m1 () throws IOException { } public void m2 () { try { m1(); } catch (IOException e) { e.printStackTrace(); } } }
4.3.6 异常捕获顺序
每个catch根据自己的参数类型捕获相应的类型匹配的异常。
由于父类引用参数可接受子类对象,因此,若把Throwable作为第1个catch子句的参数,它将捕获任何类型的异常,导致后续catch没有捕获机会。
通常将继承链最底层的异常类型作为第1个catch子句参数,次底层异常类型作为第2个catch子句参数,以此类推。越在前面的catch子句其异常参数类型应该越具体。以便所有catch都有机会捕捉相应异常。
无论何时,throw以后的语句都不会执行。
无论同层catch子句是否捕获、处理 本层的异常(即使在catch块里抛出或转发异常),同层的finally总是都会执行。
一个catch捕获到异常后,同层其他catch都不会执行,然后执行同层finally。
4.4 泛型程序设计 java的泛型通过擦除法 实现。编译时会用类型实参 代替类型形参 进行严格的语法检查,然后擦除类型参数、生成所有实例类型 共享的唯一原始类型 。
泛型的一个优点就是在编译时而不是运行时检测出错误。运用泛型,指定集合中的对象类型,你可以在编译时发现类型不匹配的错误,并且取数据时不需要手动强转类型。
编程的时候,能在编译时发现并修改错误最好,等上线运行时报错才解决,则属于生产事故,且找到bug的位置需要花费更多的时间和精力。
所以泛型的优点有如下几点:
简单来说,泛型可以帮助我们在编译的时候就检查出错误【使得程序更加安全】
泛型可以省去类型强制转换。【加入泛型后,编译器会自动进行强制转换】
泛型的本质是参数化类型
1 2 3 public class Paly <T>{ T play () {} }
泛型将所操作的数据类型作为参数。其中T就是作为一个类型参数在Play被实例化的时候所传递来的参数
1 Play<Integer> playInteger=new Play <>();
4.4.1 泛型类 泛型类可看作是普通类的工厂。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class Generic <T>{ private T key; public Generic (T key) { this .key = key; } public T getKey () { return key; } }
具体实现:
1 2 3 4 5 6 7 8 9 10 11 12 Generic<Integer> genericInteger = new Generic <Integer>(123456 ); Generic<String> genericString = new Generic <String>("key_vlaue" ); Log.d("泛型测试" ,"key is " + genericInteger.getKey()); Log.d("泛型测试" ,"key is " + genericString.getKey());
注意:
泛型的类型参数只能是类类型,不能是简单类型。
不能对确切的泛型类型使用instanceof操作。如下面的操作是非法的,编译时会出错。
4.4.2 泛型接口 泛型接口常被用在各种类的生产器中。
1 2 3 4 5 6 7 8 9 10 11 class FruitGenerator <T> implements Generator <T>{ @Override public T next () { return null ; } }
4.4.3 泛型通配符 类型通配符一般是使用?代替具体的类型实参。此处’?’是类型实参,而不是类型形参。 此处的?和Number、String、Integer一样都是一种实际的类型,可以把?看成所有类型的父类。是一种真实的类型。
可以解决当具体类型不确定的时候,这个通配符就是 ? ;当操作类型时,不需要使用类型的具体功能时,只使用Object类中的功能。那么可以用 ? 通配符来表未知类型。
4.4.4 泛型方法 要注意泛型方法和普通的实例方法的区别:泛型方法的返回类型前面一定是一个泛型!!!与之对应的是函数的形参是一个泛型定义的。
在实际调用泛型方法的时候,调用泛型方法,将实际类型放于<>之中方法名之前;也可以不显式指定实际类型,而直接给实参调用,如
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 public class GenericTest { public class Generic <T>{ private T key; public Generic (T key) { this .key = key; } public T getKey () { return key; } } public <T> T showKeyName (Generic<T> container) { System.out.println("container key :" + container.getKey()); T test = container.getKey(); return test; } public void showKeyValue1 (Generic<Number> obj) { Log.d("泛型测试" ,"key value is " + obj.getKey()); } public void showKeyValue2 (Generic<?> obj) { Log.d("泛型测试" ,"key value is " + obj.getKey()); } public static void main (String[] args) { } }
4.4.5 静态方法和泛型 静态方法无法访问类上定义的泛型;如果静态方法操作的引用数据类型不确定的时候,必须要将泛型定义在方法上。
如果静态方法要使用泛型的话,必须将静态方法也定义成泛型方法 。
1 2 3 4 5 6 7 8 9 10 11 12 13 public class StaticGenerator <T> { .... .... public static <T> void show (T t) { } }
4.4.6 泛型变量的限定 定义泛型变量的上界:public class NumberGeneric< T extends Number>
泛型变量上界的说明:上述方式的声明规定了NumberGeneric类所能处理的类型变量其类型和Number有继承关系;
extends关键字所声明的上界既可以是一个类,也可以是一个接口;当泛型变量这样声明时,在实例化一个泛型类时,需要明确类型必须为指定上界类型或者子类。
表示T应该是绑定类型的子类型(subtype)。T和绑定类型可以是类,也可以是接口。选择关键字extends的原因是更接近子类的概念。一个类型变量或通配符可以有多个限定,限定类型用“&”分割 。例如:T extends Comparable & Serializable
但是至多一个类 【如果用一个类作为限定,它必须是限定列表中的第一个】
定义泛型变量的下界:List<? super CashCard> cards = newArrayList();
泛型变量下界的说明:通过使用super关键字可以固定泛型参数的类型为某种类型或者其超类。当程序希望为一个方法的参数限定类型时,通常可以使用下限通配符。
public static void sort(T[] a, Comparator<? super T> c){ … }
4.4.7 擦除机制 参考文章
Java中的泛型,只在编译阶段有效 。在编译过程中,正确检验泛型结果后 ,会将泛型的相关信息擦出 ,并且在对象进入和离开方法的边界处添加类型检查和类型转换 的方法。也就是说,成功编译过后的class文件中是不包含任何泛型信息的。
虚拟机没有泛型类型对象——所有对象都属于普通类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class Test { public static void main (String[] args) { ArrayList<String> list1 = new ArrayList <String>(); list1.add("abc" ); ArrayList<Integer> list2 = new ArrayList <Integer>(); list2.add(123 ); System.out.println(list1.getClass() == list2.getClass()); } }
类型擦除: 无论何时定义一个泛型类型,都自动提供了一个相应的原始类型。原始类型的名字就是删去类型参数后的泛型类型名。
擦除类型变量,并替换为限定类型(无限定的变量用Object)
当编译泛型类、接口和方法时,会用Object代替非受限类型参数E。
如果一个泛型的参数类型是受限的,编译器会用该受限类型来替换它。
值得注意的是泛型变量类型的检查是在编译之前进行的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class Test { public static void main (String[] args) { ArrayList<String> list1 = new ArrayList (); list1.add("1" ); list1.add(1 ); String str1 = list1.get(0 ); ArrayList list2 = new ArrayList <String>(); list2.add("1" ); list2.add(1 ); Object object = list2.get(0 ); new ArrayList <String>().add("11" ); new ArrayList <String>().add(22 ); String str2 = new ArrayList <String>().get(0 ); } }
4.4.8 反射和泛型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Class clz ; clz= Manager.class; clz = int .class; Class<Person> genericClz; genericClz = Person.class; Class<? extends Person > clz2; clz2 = Person.class; clz2 = Employee.class; clz2 = Manager.class;
4.4.9 使用泛型的限制
使用泛型类型的限制:不能new泛型数组(数组元素是泛型),但可以声明【new是运行是发生的,因此new 后面一定不能出现类型形参E,运行时类型参数早没了】
不能使用new A[ ]的数组形式,因为E已经被擦除[ ] list = new ArrayList[10];//错误
E已经被擦除,只能用泛型的原始类型初始化数组, 必须改为new ArrayList[10] [ ] list = new ArrayList[10];
为什么这里不需要强制类型转换:参数化类型与原始类型的兼容性
参数化类型对象可以被赋值为原始类型的对象,原始类型对象也可以被赋值为参数化类型对象 a2 = a1; //参数化类型
异常类不能是泛型的。泛型类不能继承java.lang.Throwable。
1 public class MyException <T> extends Exception {}
因为如果这么做的话,需要为MyException添加一个catch语句
1 2 3 try {}catch (MyException<T> ex){ }
但是JVM需要检查这个try语句中抛出来的异常以确定与catch语句中的异常类型匹配。但是,运行时的类型信息是不可获取的
静态上下文中不允许使用泛型的类型参数。由于泛型类的所有实例类型都共享相同的运行时类,所以泛型类的静态变量和方法都被它的所有实例类型所共享。因此,在静态方法、数据域或者初始化语句中,使用泛型的参数类型是非法的。
1 2 3 public static void m (E o) public static E o;static {E o}
不能使用new E( );//只能想办法得到E的类型实参的Class信息,再newInstance(…)