kafka高级机制
Rebalance机制
消费组有多个消费者,消费组在消费一个Topic的时候,kafka为了保证消息消费不重不漏,kafka将每个partition唯一性地分配给了消费者。但是如果某个消费组在消费的途中有消费者宕机或者有新的消费者加入的时候那么partition分配就是不公平的,可能导致某些消费者负载特别重,某些消费者又没有负载的情况。Kafka有一种专门的机制处理这种情况,这种机制称为Rebalance机制。
rebalance触发的条件有以下3个。
- 组成员发生变更,比如新consumer加入组,或已有consumer主动离开组,再或是已有consumer崩溃时则触发rebalance。
- 组订阅topic数发生变更,比如使用基于正则表达式的订阅,当匹配正则表达式的新topic被创建时则会触发rebalance。
- 组订阅topic的分区数发生变更,比如使用命令脚本增加了订阅topic的分区数。
真实应用场景中引发rebalance最常见的原因就是违背了第一个条件,特别是consumer崩溃的情况。
这里的崩溃不一定就是指consumer进程“挂掉”或consumer进程所在的机器宕机。
当consumer无法在指定的时间内完成消息的处理,那么coordinator就认为该consumer已经崩溃,从而引发新一轮rebalance。
重平衡的场景流程图如下:
阶段一按时序关系细分了几个步骤:
- 步骤一 Consumer 0 发起入组请求
- 步骤二因为没有成员 ID 入组请求被 Coordinator 拒绝并返回了一个有效的成员 ID
- 步骤三 Consumer 0 带入步骤二返回的成员 ID 再次入组并成功,Consumer 0 入组成功之后,其他成员陆续发起入组请求
- 步骤四 Coordinator 直接赋予其领导者身份,因为是第一个入组成功的成员
这一阶段整个消费者组状态从 Empty → PreparingRebalance,触发原因是步骤三有消费者申请入组成功(步骤一、二未触发原因是没有成员 ID 导致入组失败)
阶段二按照时序关系分这么几个步骤:
- 步骤一入组等待时间结束,向所有消费者发送入组成功结果
- 步骤二所有消费者向 Coordinator 发送组同步请求,领导者 Consumer 0 发送的同步请求中携带了基于入组成功结果计算的整个消费者组的分区消费方案
- 因为步骤二收到了消费者组的分区消费方案,所以步骤三 Coordinator 向组成员广播了这个方案
这一阶段消费者组状态从 PreparingRebalance → CompletingRebalance → Stable,触发原因分别是:
- 入组等待时间结束
- 领导者发起了组同步请求
除了新建的消费者组之外,已有的消费者组因为很多事件也会触发重平衡机制,而且整个平衡的过程和这里的案例会有所区别
这里举了个例子只是为了帮助读者对整个重平衡过程有个大体的印象,了解整个过程中发生的主要流程,其他场景下的重平衡过程就不一一举例铺开叙述了
Rebalance分区分配
Kafka新版本consumer默认提供了3种分配策略,分别是range策略、round-robin策略和sticky策略。
所谓的分配策略决定了订阅topic的每个分区会被分配给那个consumer。
range策略主要是基于范围的思想。
它将单个topic的所有分区按照顺序排列,然后把这些分区划分成固定大小的分区段并依次分配给每个consumer。
round-robin策略则会把所有topic的所有分区顺序摆开,然后轮询式地分配给各个consumer。
sticky策略有效地避免了上述两种策略完全无视历史分配方案的缺陷,采用了“有黏性”的策略对所有consumer实例进行分配,可以规避极端情况下的数据倾斜并且在两次rebalance间最大限度地维持了之前的分配方案。
通常意义上认为,如果group下所有consumer实例的订阅是相同的,那么使用round-robin会带来更公平的分配方案,否则使用range策略的效果更好。
用户可以根据consumer参数partition.assignment.strategy来进行设置。
另外Kafka支持自定义的分配策略,用户可以创建自己的consumer分配器(assignor)。
假设目前某个consumer group下有两个consumer:A和B。
当第3个成员C加入时,满足了前面谈到的第一个触发条件。
因此coordinator会执行rebalance,并根据range分配策略重新为A、B和C分配分区,如图:
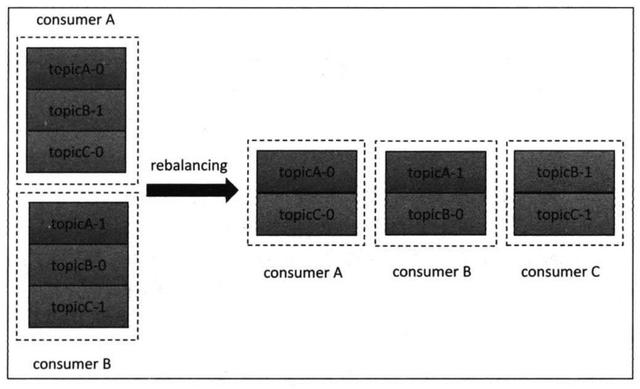
原先A和B分别处理3个分区的数据,rebalance之后A、B、C各自承担2个分区的消费,可以说这个分配方案非常公平,每个consumer上的负载是相同的。
Rebalance Generation
每个consumer group可以执行任意次rebalance。
为了更好地隔离每次rebalance上的数据,新版本consumer设计了rebalance generation用于标识某次rebalance。
generation这个词类似于JVM分代垃圾收集器中“分代”(严格来说,JVM GC使用的是generational)的概念。
这里把它翻译成“届”,表示rebalance之后的一届成员,在consumer中它是一个整数,通常从0开始。
Kafka引入consumer generation主要是为了某些原因延迟提交了offset,但rebalance之后该group产生了新一届的group成员,而这次延迟的offset提交携带的是旧的generation信息,因此这次提交会被consumer group拒绝。
很多Kafka用户在使用consumer时经常碰到的ILLEGAL_GENERATION异常就是这个原因导致的。
事实上,每个group进行rebalance之后,generation号都会加1,表示group进入了一个新的版本。
如图:
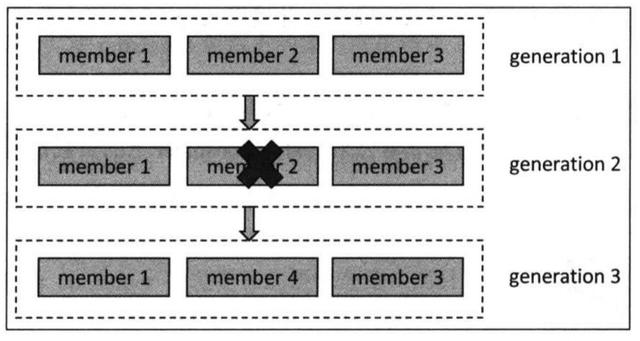
Generation 1 时 group有3个成员,随后成员2退出组,coordinator触发rebalance,consumer group进入到Generation 2时代,之后成员4加入,再次触发rebalance,group进入到Generation 3 时代。
Rebalance协议
rebalance本质上是一组协议。group与coordinator共同使用这组协议完成 group的rebalance。
最新版本Kafka中提供了下面5个协议来处理rebalance相关事宜。
- JoinGroup请求:consumer请求加入组。
- SyncGroup请求:group leader把分配方案同步更新到组内所有成员中。
- Heartbeat请求:consumer定期向coordinator汇报心跳表明自己依然存活。
- LeaveGroup请求:consumer主动通知coordinator该consumer即将离组。
- DescribeGroup请求:查看组的所有信息,包括成员信息、协议信息、分配方案以及订阅信息等。该请求类型主要供管理员使用。coordinator不使用该请求执行rebalance。
在rebalance过程中,coordinator主要处理consumer发过来的JoinGroup和SyncGroup请求,当consumer主动离组时会发送LeaveGroup请求给coordinator。
在成功rebalance之后,组内所有consumer都需要定期地向coordinator发送Hearbeat请求。
而每个consumer也是根据Hearbeat请求的响应中是否包含REBALANCE_IN_PROGRESS来判断当前group是否开启了新一轮rebalance。
Rebalance流程
consumer group在执行rebalance之前必须首先确认coordinator所在的broker,并创建与该broker相互通信的Socket连接。
确定coordinator的算法与确定offset被提交到_consumer_offsets目标分区的算法是相同的。
算法如下:
- 计算Math.abs(groupID.hashCode)%offsets.topic.num.partitions参数值(默认是50),假设是10.
- 寻找_consumer_offsets分区10的leader副本所在的broker,该broker即为这个group的coordinator。
成功连接coordinator之后便可以执行rebalance操作。
目前rebalance主要分为两步:加入组和同步更新分配方案。
加入组:这一步中组内所有consumer(即group.id相同的所有consumer实例)向coordinator发生JoinGroup请求。
当收集全JoinGroup请求后,coordinator从中选择一个consumer担任group的leader,并把所有成员信息以及它们的订阅信息发送给leader。
特别需要注意的是,group的leader和coordinator不是一个概念。
leader是某个consumer实例,coordinator通常是Kafka集群中的一个broker。另外leader而非coordinator负责整个group的所有成员制定分配方案。
同步更新分配方案:这一步中leader开始制定分配方案,即根据前面提到的分配策略决定每个consumer都负责哪些topic的哪些分区。
一旦分配完成,leader会把这个分配方案封装进SyncGroup请求并发送给coordinator。比较有意思的是,组内所有成员都会发送SyncGroup请求,不过只有leader发送的SyncGroup请求中包含了分配方案。
coordinator接收到分配方案后把属于每个consumer的方案单独抽取出来作为SyncGroup请求的response返还给各自的consumer。