全文搜索引擎 Elasticsearch研究手册
es使用原理
倒排索引基本原理
- 文档收集(Document Collection):
- 首先,搜索引擎需要收集并存储所有要搜索的文档。
- 分词和标记化(Tokenization):
- 对每个文档执行分词操作,将文本划分为单词或标记(Tokens)。
- 分词过程通常包括去除空格、标点符号、停用词等,将文本转化为小写,并执行词干提取或词形还原等操作。
- 构建倒排索引(Inverted Index):
- 倒排索引是一种数据结构,它将每个词汇或标记映射到包含该词汇的文档列表。
- 对于每个不同的词汇,都会创建一个倒排索引项(Inverted Index Entry),其中包括该词汇出现的文档列表和出现次数等信息。
- 倒排索引项包括以下信息:
- 词汇(Token):即标记化后的词汇。
- 文档ID列表:包含包含该词汇的文档ID的列表。
- 词汇出现次数:记录了该词汇在每个文档中出现的次数。
- 可能的其他信息,如位置信息,用于支持短语搜索。
- 倒排索引是一个数据结构,通常存储在内存中,用于加速搜索。
- 搜索过程(Search Process):
- 当用户发起搜索请求时,搜索引擎会首先分析查询,将查询分词并执行相同的标记化和词干处理。
- 然后会查找每个查询词汇对应的倒排索引项,以获得包含这些词汇的文档列表。
- 交并集操作(Intersection and Union):
- 一旦获得了每个查询词汇的文档列表,搜索引擎会执行交集(AND)或并集(OR)等操作,以确定最终的搜索结果。
- 交集操只返回包含所有查询词汇的文档。
- 并集操返回包含任何查询词汇的文档。
- 排序(Ranking):
- 可能会根据相关性对搜索结果进行排序,以便将最相关的文档排在前面。
倒排索引的优势在于它允许快速查找包含特定词汇的文档,而不必扫描整个文档集合。这使得全文搜索变得非常高效,适用于大规模的文本数据集合。
Analyzer分词
Analysis:文本分析,就是将文本转换为单词(term或者token)的过程,其中Analyzer就是通过Analysis实现的。
分词涉及到以下几个步骤:
- 文本标记化(Tokenization):
- 分词的第一步是将文本划分成标记或词元,这些标记通常是单词、数字、符号或其他有意义的文本单元。
- 标记化过程通常包括去除空格、标点符号、停用词等无关紧要的信息,并将文本转换为小写。
- 词干提取(Stemming):
- 词干提取是将单词转换为其基本形式的过程。例如,将 “running” 转换为 “run”。
- 这有助于将相关单词归并到同一个词根下,从而提高搜索的召回率。
- 词汇分析(Lexical Analysis):
- 词汇分析是分词的核心过程,它使用分析器(Analyzer)来将文本分成一系列词元。
- Elasticsearch提供了多种内置的分析器,例如标准分析器(Standard Analyzer)、分词器(Tokenizer)和过滤器(Filter)。
- 分析器可以根据不同的需求执行分词、词干提取、小写转换和其他文本处理操作。
- 停用词过滤(Stop Word Filtering):
- 停用词是在搜索索引中通常被忽略的常见词语,例如 “a”、”an”、”the”。
- 停用词过滤器用于从文本中移除这些常见词语,以减小索引的大小并提高搜索效率。
- 字符过滤(Character Filtering):
- 字符过滤器用于处理特殊字符,例如去除标点符号或进行字符映射。
- 它可以确保文本在分词之前被清理和标准化。
- 位置信息(Positional Information):
- 分词器还会为每个词元维护位置信息,以便在查询中支持短语匹配和近似匹配等高级搜索操作。
- 自定义分词器(Custom Analyzers):
- Elasticsearch允许用户定义自己的分析器,以满足特定应用程序的需求。用户可以配置标记化、词干提取、字符过滤等步骤。
分词器
Elasticsearch给我们内置例很多分词器。
Standard Analyzer:默认的分词器,按照词切分,并作大写转小写处理Simple Analyzer:按照非字母切分(符号被过滤),并作大写转小写处理Stop Anayzer:停用词(the、is)切分,并作大写转小写处理Whitespace Anayzer:空格切分,不做大写转小写处理IK:中文分词器,需要插件安装ICU:国际化的分词器,需要插件安装jieba:时下流行的一个中文分词器。
分出来的词的集合叫做Term Dictionary。这些文档ID保存在PostingList
中文分词器IK下载安装
下载中文分词器 github.com/medcl/elast…
1 | elasticsearch-analysis-ik-master.zip |
(2)解压elasticsearch-analysis-ik-master.zip
unzip elasticsearch-analysis-ik-master.zip
(3)进入elasticsearch-analysis-ik-master,编译源码
mvn clean install -Dmaven.test.skip=true
(4)在es的plugins文件夹下创建目录ik
(5)将编译后生成的elasticsearch-analysis-ik-版本.zip移动到ik下,并解压
(6)解压后的内容移动到ik目录下
es集群
集群cluster
- 集群是一组一个或多个Elasticsearch节点的集合,它们协同工作以存储和处理数据。
- 每个节点都有唯一的名称,并且可以加入到一个集群中。名字默认就是“elasticsearch”
- 集群有一个全局唯一的名称,用于标识整个Elasticsearch部署。
节点node
- 节点是Elasticsearch集群中的单个实例,它可以是物理服务器、虚拟机或容器。
- 每个节点都有自己的名称,以及自己的角色(如主节点、数据节点、协调节点等)。
- 不同类型的节点承担不同的责任,例如主节点
Master Node:它主要负责维护索引元数据、负责切换主分片和副本分片身份等工作(后面会讲到分片的概念),如果主节点挂了,会选举出一个新的主节点。 - 节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫 做“elasticsearch”的集群中。
分片机制
分片(shard)
Elasticsearch最外层的是Index(相当于数据库 表的概念);一个Index的数据我们可以分发到不同的Node上进行存储,这个操作就叫做分片。
Elasticsearch将索引分成多个分片,每个分片是一个独立的Lucene索引。
分片用于水平分割数据,以便可以将数据均匀分布在集群中的不同节点上。
分片的数量在索引创建时确定,通常可以根据数据量的增长进行动态调整。
主分片(Primary Shard):
- 主分片是一个索引的初始数据分片,它包含索引的部分数据。
- 当创建一个索引时,可以指定主分片的数量。主分片的数量在索引创建后不可更改。
- 主分片负责存储索引的原始数据。它是可读写的,因此可以处理索引的写入操作(例如,插入、更新和删除文档)。
- 主分片的数量直接影响了索引的水平扩展性,因此通常在索引创建时需要根据数据量和性能需求进行合理的配置。
复制分片(Replica Shard):
- 复制分片是主分片的副本,它用于提供高可用性和查询性能的负载均衡。
- 复制分片的数量是可配置的,通常每个主分片都会有一个或多个复制分片。
- 复制分片是只读的,它们与其对应的主分片保持同步。这意味着它们可以处理读取请求,但不能处理写入请求。
- 如果主分片不可用(例如,由于节点故障),复制分片可以升级为主分片,确保数据仍然可用。
数据写入的时候是写到主分片,副本分片会复制主分片的数据,读取的时候主分片和副本分片都可以读。
Index需要分为多少个分片和副本分片都是可以通过配置设置的
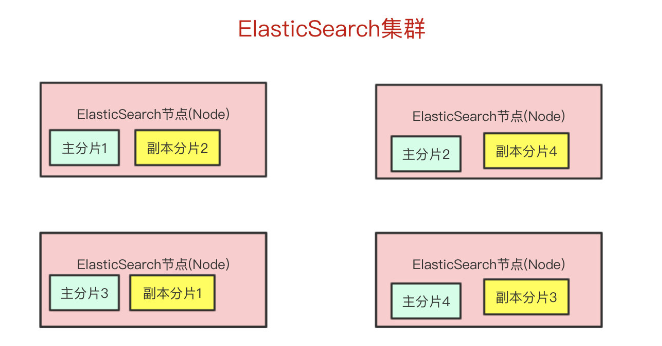
如果某个节点挂了,前面所提高的Master Node就会把对应的副本分片提拔为主分片,这样即便节点挂了,数据就不会丢。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。
文档的核心元数据
Index:Elasticsearch的Index相当于数据库的Table。可类比mysql中的数据库
Type:这个在新的Elasticsearch版本已经废除(在以前的Elasticsearch版本,一个Index下支持多个Type–有点类似于消息队列一个topic下多个group的概念)。 可类比mysql中的表
Document: 插入索引库以文档为单位,类比与数据库中的一行数据
Field:相当于是数据表的字段,对文档数据根据不同属性进行的分类标识。
Mapping:相当于数据库的Schema的概念。相当于mysql中的创建表的过程,设置主键外键等等
Query DSL:类似于mysql的sql语句,只不过在es中是使用的json格式的查询语句(给我们读取Elasticsearch数据的API)
GET/PUT/POST/DELETE:分别类似与mysql中的select/update/delete……
文档curd原理
新增写入
客户端写入一条数据,到Elasticsearch集群里边就是由节点来处理这次请求
集群上的每个节点都是coordinating node(协调节点),协调节点表明这个节点可以做路由。比如节点1接收到了请求,但发现这个请求的数据应该是由节点2处理(因为主分片在节点2上),所以会把请求转发到节点2上。
- coodinate(协调)节点通过hash算法可以计算出是在哪个主分片上,然后路由到对应的节点
写内存缓冲区(定时去生成segement,生成translog),能够让数据能被索引、被持久化。最后通过commit完成一次的持久化。等主分片写完了以后,会将数据并行发送到副本集节点上,等到所有的节点写入成功就返回ack给协调节点,协调节点返回ack给客户端,完成一次的写入。
具体如下:
- Elasticsearch会把数据先写入内存缓冲区,然后每隔1s刷新到文件系统缓存区(当数据被刷新到文件系统缓冲区以后,数据才可以被检索到)。【Elasticsearch写入的数据需要1s才能查询到】。
- 为了防止节点宕机,内存中的数据丢失,Elasticsearch会另写一份数据到日志文件上,但最开始的还是写到内存缓冲区,每隔5s才会将缓冲区的刷到磁盘中。【Elasticsearch某个节点如果挂了,可能会造成有5s的数据丢失】。
- 等到磁盘上的translog文件大到一定程度或者超过了30分钟,会触发commit操作,将内存中的segement文件异步刷到磁盘中,完成持久化操作。
更新和删除
Elasticsearch的更新和删除操作流程:
- 给对应的
doc记录打上.del标识,如果是删除操作就打上delete状态,如果是更新操作就把原来的doc标志为delete,然后重新新写入一条数据
前面提到了,每隔1s会生成一个segement 文件,那segement文件会越来越多越来越多。Elasticsearch会有一个merge任务,会将多个segement文件合并成一个segement文件。
在合并的过程中,会把带有delete状态的doc给物理删除掉。
查询
查询我们最简单的方式可以分为两种:
- 根据ID查询doc————对应api(Get)
- 根据query(搜索词)去查询匹配的doc————对应api(Query)
根据ID去查询具体的doc的流程是:
- 检索内存的Translog文件
- 检索硬盘的Translog文件
- 检索硬盘的Segement文件
根据query去匹配doc的流程是:
- 同时去查询内存和硬盘的Segement文件
查询阶段
第一步:查询请求发给任意一个节点,该节点就成了coordinating node,该节点使用路由算法算出文档所在的主分片
第二步:协调节点把请求转发给主分片也可以转发给复制分片(使用轮询调度算法(Round-Robin Scheduling,把请求平均分配至主分片和复制分片)
第三步:处理请求的节点把结果返回给协调节点,协调节点再返回给应用程序
Elasticsearch查询又分可以为三个阶段:
- QUERY_AND_FETCH(查询完就返回整个Doc内容)
- QUERY_THEN_FETCH(先查询出对应的Doc id ,然后再根据Doc id 匹配去对应的文档)
- DFS_QUERY_THEN_FETCH(先算分,再查询)
一般我们用得最多的就是QUERY_THEN_FETCH,第一种查询完就返回整个Doc内容(QUERY_AND_FETCH)只适合于只需要查一个分片的请求。
QUERY_THEN_FETCH总体的流程流程大概是:
- 客户端请求发送到集群的某个节点上。集群上的每个节点都是coordinate node(协调节点)
- 然后协调节点将搜索的请求转发到所有分片上(主分片和副本分片都行)
- 每个分片将自己搜索出的结果
(doc id)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。 - 接着由协调节点根据
doc id去各个节点上拉取实际的document数据,最终返回给客户端。
Query Phase阶段时节点做的事:
- 协调节点向目标分片发送查询的命令(转发请求到主分片或者副本分片上)
- 数据节点(在每个分片内做过滤、排序等等操作),返回
doc id给协调节点
Fetch Phase阶段时节点做的是:
- 协调节点得到数据节点返回的
doc id,对这些doc id做聚合,然后将目标数据分片发送抓取命令(希望拿到整个Doc记录) - 数据节点按协调节点发送的
doc id,拉取实际需要的数据返回给协调节点
总结:由于Elasticsearch是分布式的,所以需要从各个节点都拉取对应的数据,然后最终统一合成给客户端
java查询语法
1. 简单全文搜索查询:
1 | javaCopy codeimport org.elasticsearch.index.query.QueryBuilders; |
2. 多字段查询:
1 | javaCopy codeimport org.elasticsearch.index.query.QueryBuilders; |
3. 布尔查询(AND、OR、NOT):
1 | javaCopy codeimport org.elasticsearch.index.query.QueryBuilders; |
4. 范围查询:
1 | javaCopy codeimport org.elasticsearch.index.query.QueryBuilders; |
5. 前缀查询:
1 | javaCopy codeimport org.elasticsearch.index.query.QueryBuilders; |
6. 通配符查询:
1 | javaCopy codeimport org.elasticsearch.index.query.QueryBuilders; |
7. 正则表达式查询:
1 | javaCopy codeimport org.elasticsearch.index.query.QueryBuilders; |
8. 模糊查询:
1 | javaCopy codeimport org.elasticsearch.index.query.QueryBuilders; |
9. 嵌套查询:
1 | javaCopy codeimport org.elasticsearch.index.query.QueryBuilders; |
10. 地理位置查询(Geo Queries):
1 | javaCopy codeimport org.elasticsearch.index.query.QueryBuilders; |
es——搜索查询方式
Elasticsearch支持两种主要的客户端方式来与Elasticsearch集群进行交互:
- RESTful API客户端:
- RESTful API客户端是通过HTTP协议直接与Elasticsearch集群进行通信的方式。
- 这种方式允许使用HTTP请求(GET、POST、PUT、DELETE等)与Elasticsearch进行交互。
- RESTful API客户端可以使用任何支持HTTP请求的编程语言,包括但不限于Java、Python、Node.js、C#等。
- 通常,通过HTTP请求发送JSON格式的数据来执行索引、搜索、更新、删除等操作。
- Java客户端:
- Elasticsearch提供了官方的Java客户端库,用于与Elasticsearch集群进行高级别的Java编程交互。
- Java客户端提供了更高级别的API和抽象,使Java开发人员更容易地与Elasticsearch进行交互。
- 它允许以面向对象的方式执行索引、搜索、分析等操作,而无需直接构建HTTP请求。
es——RESTful API客户端
默认情况下,ElasticSearch使用两个端口来监听外部TCP流量。
- 9200端口:用于所有通过HTTP协议进行的API调用。包括搜索、聚合、监控、以及其他任何使用HTTP协议的请求。所有的客户端库都会使用该端口与ElasticSearch进行交互。
- 9300端口:是一个自定义的二进制协议,用于集群中各节点之间的通信。用于诸如集群变更、主节点选举、节点加入/离开、分片分配等事项。
java 客户端介绍
RestHighLevelClient的API作为ElasticSearch备受推荐的客户端组件,其封装系统操作ES的方法,包括索引结构管理,数据增删改查管理,常用查询方法,并且可以结合原生ES查询原生语法,功能十分强大。
| 客户端 | 优点 | 缺点 | 说明 |
|---|---|---|---|
| Java Low Level Rest Client | 与ES版本之间没有关系,适用于作为所有版本ES的客户端 | ||
| Java High Level Rest Client | 使用最多 | 使用需与ES版本保持一致 | 基于Low Level Rest Client,它提供了更多的接口。注意:7.15版本之后将被弃用 |
| TransportClient | 使用Transport 接口进行通信,能够使用ES集群中的一些特性,性能最好 | JAR包版本需与ES集群版本一致,ES集群升级,客户端也跟着升级到相同版本 | 过时产品,7版本之后不再支持 |
| Elasticsearch Java API Client | 最新的es客户端 | 文档少 |
JavaREST客户端有两种模式:
- Java Low Level REST Client:ES官方的低级客户端。低级别的客户端通过http与Elasticearch集群通信。
- Java High Level REST Client:ES官方的高级客户端。基于上面的低级客户端,也是通过HTTP与ES集群进行通信。它提供了更多的接口。
注意事项:
客户端(Client) Jar包的版本尽量不要大于Elasticsearch本体的版本,否则可能出现客户端中使用的某些API在Elasticsearch中不支持。
使用步骤
RestHighLevelClient依赖
使用RestHighLevelClient需要依赖rest-high-level-client包,和ES相关基础依赖。
1 | <dependency> |
创建客户端
1 |
|
RestClient.builder 的参数是个可变参数,集群模式下,增加节点配置即可(多个new HttpHost)
使用客户端的时候注入即可,下文中所有
esClient都来自这个类
索引操作
特点:和请求体查询高度相似,灵活度高,方便控制每个字段的属性,但是写法比较繁琐
1 | public void createIndexM2() { |
文档操作——curd
插入文档
1 | public void insertDoc() { |
获取文档
1 | public void getDoc() { |
删除文档
1 | public void deleteDoc() { |
修改文档
1 | public void updateDoc() { |
文档搜索
分页搜索
1 | public void pageSearch() { |
简单搜索
1 | public void simpleSearch() { |
常用的条件构造器:
QueryBuilders.termQuery(“key”, obj) 完全匹配
QueryBuilders.termsQuery(“key”, obj1, obj2…) 一次匹配多个值
QueryBuilders.matchQuery(“key”, Obj) 单个匹配, field不支持通配符, 前缀具高级特性
QueryBuilders.multiMatchQuery(“text”, “field1”, “field2”…) 匹配多个字段, field有通配符忒行
QueryBuilders.matchAllQuery() 匹配所有文件复合条件构造器:
QueryBuilders.boolQuery()
.must(termQuery(“content”, “test1”)) 相当于 与 & =
.mustNot(termQuery(“content”, “test2”)) 相当于 非 ~ !=
.should(termQuery(“content”, “test3”)) 相当于 或 | or
.filter(termQuery(“content”, “test5”)); 过滤
高亮搜索
1 | public void highLightSearch() { |
rest api
ES为开发者提供了非常丰富的基于HTTP协议的Rest API,只需要向ES服务端发送简单的Rest请求,就可以实现非常强大的功能。