kafka应用教程
kafka的本质是一个数据存储平台,流平台,只是他在做消息发布,消息消费的时候我们可以把他当做消息中间件来用。
kafka消息发送的时候,考虑到性能可以采用打包方式发送,也就是说传统的消息是一条一条发送,现在可以先把需要发送的消息缓存在客户端,等到达一定数值时,再一起打包发送,而且还可以对发送的数据进行压缩处理,减少在数据传输时的开销
Spring Cloud Stream
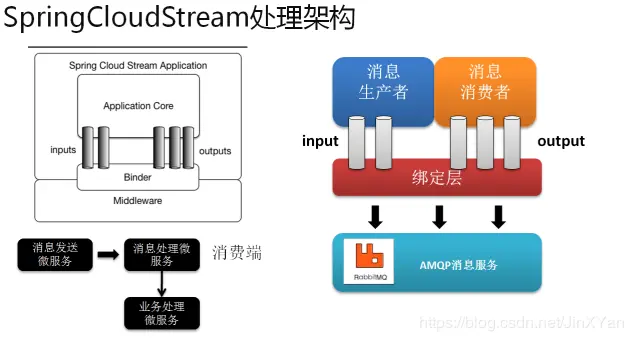
Spring Cloud Stream本质上就是整合了Spring Boot和Spring Integration,实现了一套轻量级的消息驱动的微服务框架。通过使用Spring Cloud Stream,可以有效地简化开发人员对消息中间件的使用复杂度,让系统开发人员可以有更多的精力关注于核心业务逻辑的处理。
应用程序通过Spring Cloud Stream注入到输入和输出通道与外界进行通信。根据此规则我们很容易的实现消息传递,订阅消息与消息中转。并且当需要切换消息中间件时,几乎不需要修改代码,只需要变更配置就行了。
Source(发射器): 一个接口类,内部定义了一个输出管道,例如定义一个输出管道 @output(”XXOO”)。说明这个发射器将会向这个管道发射数据。
**Sink(接收器):**一个接口类,内部定义了一个输入管道,例如定义一个输入管道 @input(”XXOO”)。说明这个接收器将会从这个管道接收数据。
**Binder(绑定器):**用于与管道进行绑定。Binder将于消息中间件进行关联。@EnableBinding (Source.class/Sink.class)。@EnableBinding()里面是可以定义多个发射器/接收器
@StreamListener:这个注解可以监听输入通道里的消息内容,注解里面的属性指定我们刚才定义的输入通道名称,而MessageChannel则可以通过输出通道发送消息。使用@Resource注入时需要指定我们刚才定义的输出通道名称
kafka
配置文件
1 | cloud: |
fetch.min.bytes
该属性指定了消费者从服务器获取记录的最小字节数。broker 在收到消费者的数据请求时,如果可用的数据量小于 fetch.min.bytes 指定的大小,那么它会等到有足够的可用数据时才把它返回给消费者。这样可以降低消费者和 broker 的工作负载,因为它们在主题不是很活跃的时候(或者一天里的低谷时段)就不需要来来回回地处理消息。如果没有很多可用数据,但消费者的 CPU 使用率却很高,那么就需要把该属性的值设得比默认值大。如果消费者的数量比较多,把该属性的值设置得大一点可以降低 broker 的工作负载。
fetch.max.wait.ms
我们通过 fetch.min.bytes 告诉 Kafka,等到有足够的数据时才把它返回给消费者。而 feth.max.wait.ms 则用于指定 broker 的等待时间,默认是 500ms。
如果没有足够的数据流入 Kafka,消费者获取最小数据量的要求就得不到满足,最终导致 500ms 的延迟。如果要降低潜在的延迟(为了满足 SLA),可以把该参数值设置得小一些。如果 fetch.max.wait.ms 被设为 100ms,并且 fetch.min.bytes 被设为 1MB,那么 Kafka 在收到消费者的请求后,要么返回 1MB 数据,要么在 100ms 后返回所有可用的数据,就看哪个条件先得到满足。
max.poll.interval.ms
这个参数定义了两次poll()之间的最大间隔,默认值为5分钟。如果超过这个间隔同样会触发rebalance。在多数情况下这个参数是导致rebalance消息重复的关键,即业务处理消息耗时太长。有人可能会疑惑,如果5分钟都没处理完消息那肯定时出了问题,其实不然。能否在5min内处理完还取决于你每次拉取了多少条消息,如果一次拿到了成千上万条的话,5min就够呛了。
max.poll.records
这个参数定义了poll()方法最多可以返回多少条消息,默认值为500。注意这里的用词是”最多”,也就是说如果在拉取消息的时候新消息不足500条,那有多少返回多少;如果超过500条,就只返回500。这个默认值是比较坑人的,如果你的消息处理逻辑比较重,比如需要查数据库,调用接口,甚至是复杂计算,那么你很难保证能够在5min内处理完500条消息,也就是说,如果上游真的突然大爆发生产了成千上万条消息,而平摊到每个消费者身上的消息达到了500的又无法按时消费完成的话就会触发rebalance, 然后这批消息会被分配到另一个消费者中,还是会处理不完,又会触发rebalance, 这样这批消息就永远也处理不完,而且一直在重复处理。