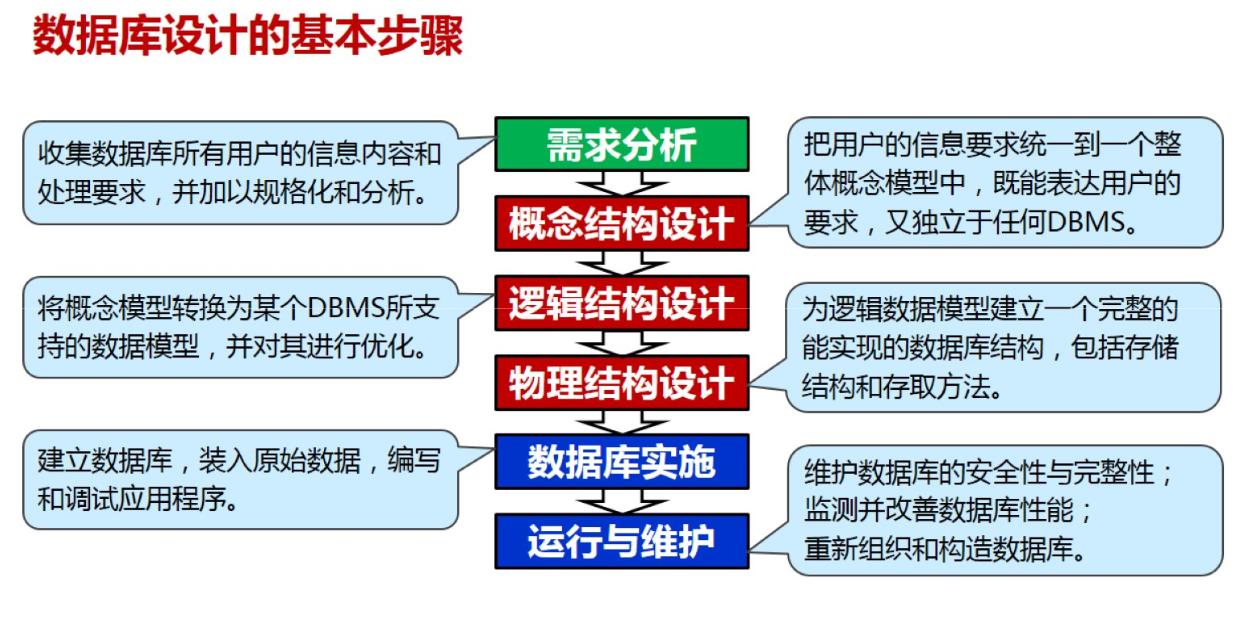
数据库设计概述
特点
- 反复性:反复设计、逐步求精
- 多解性:设计结果不唯一,多种方案并存
- 分步进行:数据库设计分为多个阶段
- 结构设计与行为设计相结合
- 面向数据的设计方法(以信息需求为主)
- 面向过程的设计方法(以处理需求为主)
数据库设计方法
- 直观设计法(手工试凑法)
- 规范设计法
- 新奥尔良法:运用软件工程的思想和方法进行数据库设计
- 基于E-R模型的设计法:先用E-R图构造企业模式,然后转换为特的那个数据库模式
- 基于3NF的设计法:确定数据库模式中的全部属性和属性间的依赖关系,将它们组织在一个单一的关系模式中,然后再分解成若干个3NF关系模式的集合
- 基于视图的设计法:先为每个应用建立视图,再将这些视图合并为全局概念模式
- 计算机辅助设计法:
- 以人的知识或经验为主导,通过人机交互方式实现设计中的某些部分
E-R模型
概念模型
1、语义表达能力丰富
2、易于理解和交流
3、易于修改和扩充
4、易于向各种数据模型转换
可以使用E-R模型、UML、ODL
E-R模型的基本观点:现实世界是由实体和实体间的联系构成的。
实体:客观存在并且可以相互区分的物体。
实体集:具有相同类型、相同属性的实体集合 。
属性:实体集中每个成员具有的描述性性质。
- 原子属性——不可再分的属性
- 复合属性——由多个原子属性构成,如:生日(年、月、日)
- 多值属性——多个同类原子/复合属性值,如:买家有多个收货地址
域:属性的取值范围。
码:能唯一标识实体集的属性或属性组,称为超码。而最小的超码(就是任意真子集都不能称为超码的超码)称为候选码。从候选码中选出一个来区别同一实体集中的不同实体称为主码(比如学生实体集中的学号)。主码在E-R图中用_____表示。
联系:实体之间相互的关联,如学生和老师的授课关系,同类联系的集合称为联系集。
元或度:参与联系的实体集的个数称为元。参与联系的实体集的主码的集合形成了联系集的超码。
参与:实体集之间的关联称为参与,实体参与联系。如学生选修课程,学生和课程参与了联系选修。
E中所有实体均参与R称为E全部参与R(用实体集合联系间的双线表示),否则称为E部分参与R。
映射基数:实体之间的联系数量,即一个实体通过一份联系集能与另一实体集相关联的实体数目。
一对一
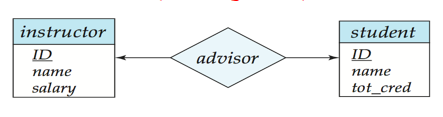
注意箭头:带箭头的表示1
一对多
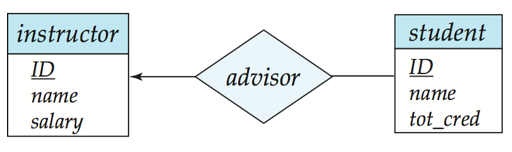
不带箭头的线段表示n
多对多
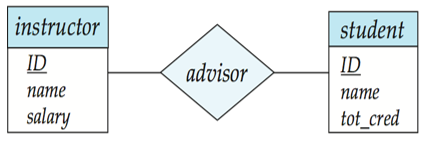
E-R模型的表示方法
总结来说,E-R图的四个组成的部分
1、矩形框:表示实体,在矩形框中写上实体的名字
2、椭圆形框:表示实体或联系的属性
3、菱形框:表示联系,在框中记入联系名
4、连线:实体与属性之间;实体与联系之间;联系与属性之间用直线相连,(对于一对一联系,要在两个实体连线方向各写1; 对于一对多联系,要在一的一方写1,多的一方写N;对于多对多关系,则要在两个实体连线方向各写N,M。)。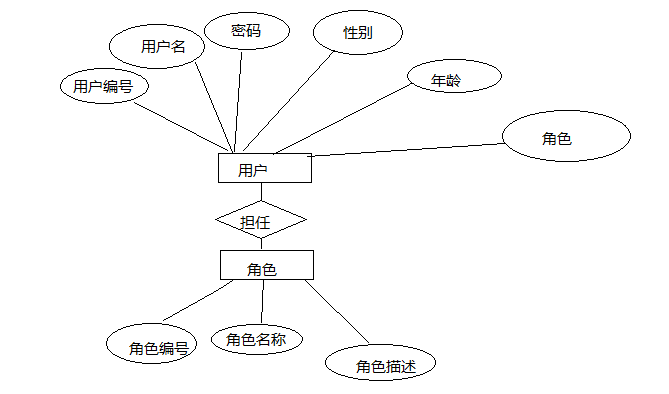
E-R模型的设计原则
- 避免冗余,避免浪费空间和操作异常。
- 一般情况下,凡是可以作为属性对待的,应该尽量作为属性
- 作为实体对待,应该满足如下条件中的一个:
- 该实体具有除码以为的其他属性
- 该实体是某个一对多或多对多联系的”多“端
概念结构设计
概念结构设计的方法与步骤
设计概念结构的E-R模型可采用四种方法
- 自顶向下
- 自底向上
- 逐步扩张
- 混合策略
最常用的方法是自底向上设计法,包含两个步骤:
- 设计局部E-R模型,即设计用户视图
- 集成各局部E-R模型,形成全局E-R模型
步骤一
设计局部E-R模型
步骤二
1、合并局部E-R图,消除冲突,生成初步E-R图
属性冲突
- 属性域冲突——属性值的类型、取值范围或是取值集合不同
- 属性取值单位冲突
属性冲突属于用户业务上的约定,必须与用户协商后解决
命名冲突
- 同名异义
- 异名同义
命名冲突的解决方式同属性冲突
结构冲突
- 同一对象在不同应用中有不同的抽象
- 同一实体在不同应用中属性组成不同
- 同一联系在不同应用中呈现不同的类型
2、消除不必要的冗余,生成基本的E-R图
冗余包括冗余的数据和冗余的联系
- 冗余的数据是指可由基本数据导出的数据
- 冗余的联系是指可由其他联系导出的联系
通常采用分析的方法消除冗余。依据为数据字典和数据流图。
逻辑结构设计
任务和步骤
- 数据库逻辑设计的任务是将概念结构转换成特定DBMS所支持的数据模型
- 步骤
- 初始化关系模式设计
- 关系模式优化
- 设计子模式
步骤一:初始关系模式设计
1、E-R图向关系模型转换
- 实体的转换
- 一个实体转换为一个关系
- 关系的属性就是该实体的属性
- 关系的码就是该实体的码
- 联系的转换
- 一个联系转换为一个关系
- 关系的属性:与该联系相连的各实体的码和该联系自身的属性
- 关系的码
- 一对一的二元联系:两端实体的码都是候选码
- 一对多的二元联系:”多“端实体的码
- 多对多的二元联系:至少包含两端实体的码的并集
- 存在”一“端的多元联系:除了一端以外的其他实体的码的并集
- 不存在一端的多元联系:至少包含所有相关尸体的码的并集
- 关系的外码:对于每个与联系相连的实体,建立与该实体关系的外码约束
1对多或者多对1的联系可以被合并到1端实体对应的关系中
步骤二:关系模式优化
- 进行规范化,消除关系模式中存在的各种异常,改善完整性、一致性和存储效率
- 进行反规范化设计,是为了提高查询效率
垂直分解
把关系模式的属性分解为若干个子集

水平分解
把关系中的元组分解为若干个子集

步骤三:设计子模式
制导思想:注重局部用户的要求
具体方法:
- 使用更符合用户习惯的别名、计量单位等
- 从安全性出发,对不同级别的用户定义不同的视图
- 从易用性触发,将复杂查询语句定义为视图
物理结构设计
任务
对于给定的逻辑模型,设计一个最合适应用要求的物理结构
约束条件:
- 应用需求(响应时间、吞吐率、存储空间利用率、安全)
- 应用特征(数据量、事务频率、涉及的关系和属性)
- 具体DBMS产品的特点(存取方法,存储结构,参数)
- 存储设备特性
设计内容:
- 设计存取方法
- 设计存储方案
- 确定系统配置参数
设计存取方法
- 索引
- 聚簇
聚簇索引的叶子节点就是数据节点,而非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针。
索引
是与基表的属性组相关的数据对象,能够提供对基表数据的快速访问。
同一个基表上可键多个索引,执行查询语句,DBMS自动选择合适的索引访问数据
当表中的数据更新时,DBMS自动更新索引
数据越多,索引的优势越明显
索引可以提高查询效率,但是增加了空间开销以及维护的代价
B+树索引
B-Tree介绍
B-Tree是一种多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
8.所有叶子结点位于同一层;
如:(M=3)
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
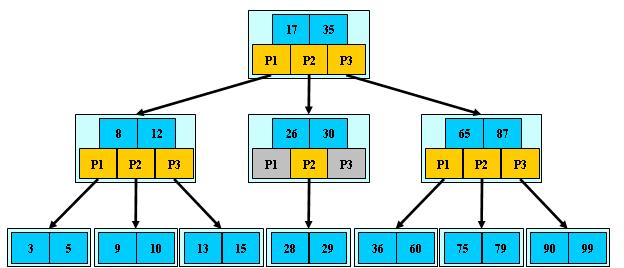
B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
如:(M=3)
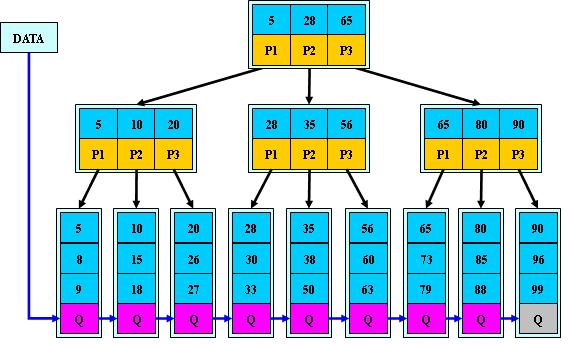
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
4.更适合文件索引系统;
适用范围广:
- 等值查询
- 范围查询
- 聚集函数计算
- 排序
- 遍历
hash索引
适用于:
- 等值查询
- 等值连接
不适用于:
- 范围查询
- 排序
- 模糊
聚簇
为了提高查询速度,把在某个属性组上具有相同值的元组集中地存放在相邻的物理块中。该属性组称为聚簇码。
- 单表聚簇:将单个表的数据按聚簇码分组有序的存储
- 多表聚簇:把多个表的数据按聚簇码集中存储在一起
设计原则
- 一个表最多只能属于一个聚簇
- 聚簇维护的开销很大
- 频繁更新的属性不适合作为聚簇码
- 单表聚簇:最常用于等值比较的属性,且该属性上的重复取值较多
- 多表聚簇:经常进行连接操作的表可以建立聚簇
设计存储方案
- 确定数据的存放位置:
- 将表和索引分别存放在不同的磁盘上
- 将日志文件和数据库对象放在不同的磁盘上
- 将数据库的备份文件存放在磁盘上
- 对空间效率要求较高的应用,考虑压缩存储
- 对安全需求较高的应用,考虑加密存储
确定系统配置参数
根据应用特点和运行环境重新配置系统配置参数:
- 最大连接数
- 内存配置参数(查询缓存、日志缓存、数据缓存······)受总的物理内存大小的约束,参数之间相关制约
- 存储配置参数(数据文件的大小、日志文件的大小、物理块大小、物理块装填因子)
- 其他