语法制导的语义计算
编译原理的几个核心阶段:词法分析、语法分析和语义分析,其实编译的本质便是翻译,其各个阶段便是承担不同的翻译任务,词法分析阶段的任务是将程序输入的字符串流翻译成语言认可的字符流(剔除空格和注释等部分);语法分析便是将程序按照语言文法的规则构建成语法树;语义分析便是在语法树构建的基础上完成语言规则的语义动作(类型检查、作用域和可视性检查、一致性检查等)。
属性文法(属性翻译文法)
对于语言而言,无论变量、函数、过程在程序中都是用一个标识符来代替,但如果给定了一个标识符,我们如何确定这个标识符的意义呢?其实这便引导出属性文法的概念(其实语义分析的公式化有多种方式,比如操作语义学、公理语义学、属性文法等,其中属性文法最为直观,也是当前绝大多数编译器采用的编译方式),比如变量有int\float\double之类的区别,那显然给定一个变量标识符,必须要指明该标识符的“数据类型属性”,所以必须给所有标识符配备一系列的属性。利用标识符的这些属性,便可以用来配合此前构建的语法树进行一系列的语义动作(类型检查、可见性是否合法等)。
语义分析一般是和语法分析组合在一起执行的,语法分析完成前一步语法树分析的构建(调用某个产生式完成一步规约,形成当前的树节点),然后语义分析便接着调用相应产生式配备的语义动作或子程序,完成属性文法所要求的语义动作(比如类型转换或生成中间代码)。所以对于属性文法而言,属性的加工和使用过程便是语义处理的意义。
形式上讲,一个属性文法是一个三元组,A=(G,V,F),一个上下文无关文法G;一个属性的有穷集V和关于属性的谓词函数的有穷集F。每个断言与文法的某产生式相联。如果对G中的某一输入串而言(句子),A中的所有断言对该输入串的语法树结点的属性全为真,则该串也是A语言中的句子。
以上下文无关文法为基础:
- 它为每个文法符号(终结符或者非终结符)配备若干相关的“值”(称为属性),代表与文法符号相关信息,如类型、值、代码序列、符号表内容等
- 对于文法的每个产生式都配备了一组属性的语义规则,对属性进行计算和传递。【凡是能够用程序实现的信息处理都可以称为语义规则】
S-属性文法
只含有综合属性的属性文法
- 如果一个SDD是
S属性的,可以按照语法分析树节点的任何自底向上顺序来计算它的各个属性值 - S-属性定义可以在自底向上的语法分析过程中实现
L-属性文法
直观含义:在一个产生式所关联的各属性之间,依赖图的边可以从左到右,但不能从右到左。【 产生式右边符号的继承属性不能依赖他右边的符号的属性】
正式定义:一个SDD是L-属性定义,当且仅当它的每个属性要么是一个综合属性,要么是满足如下条件的继承属性:假设存在一个产生式$A\rightarrow{X_1X_2…X_n}$其右部符号$X_i$的继承属性仅依赖于下列属性:
- A的继承属性
- 产生式中$X_i$左边的符号$X_1,X_2,…,X_{i-1}$的属性
$X_i$本身的属性,但$X_i$的全部属性不能在依赖图中形成环路 - 注:每个S-属性定义都是L-属性定义
综合属性
自下而上传递信息
语法规则:根据右部候选式中的符号的属性计算左部被定义符号的综合属性
语法树:根据子结点的属性和父结点自身的属性计算父结点的综合属性
由此可知,综合属性是自下而上传递的。
继承属性
主要是用来自上而下传递信息。
语法规则:根据右部候选式中的符号的属性和左部被定义符号的属性计算右部候选式中的符号的继承属性
语法树:根据父结点的属性和兄弟结点自身的属性计算子结点的继承属性
属性依赖
对应每个产生式A -> α都有一套与之相关联的语义规则,每条规则的形式为:
b:f(c1,c2····ck);f是一个函数,c1,c2····ck是某些属性,b是需要计算的属性。
我们称b依赖属性c1,c2····ck:
- b是A的一个综合属性并且c
1,c2····ck是产生式右边符号的属性 - b是产生式右边某个文法符号的一个继承属性并且c
1,c2····ck是A或产生式右边任何文法符号的属性
注意:
(1)终结符只有综合属性,它由词法分析器提供
(2)非终结符既可以有综合属性也可以有继承属性,文法开始符号的所有继承属性作为属性计算前的初始值。
(3) 产生式右边符号的继承属性和产生式左边符号的综合属性都必须提供一个计算规则
(4) 产生式左边符号的继承属性和产生式右边符号的综合属性不由所给的产生式的属性计算规则进行计算,它们由其它产生式的属性规则计算
所以在对属性计算的过程即是对语义处理的过程,对于文法的每一个产生式配备一组属性的计算规则,则称为语义规则。
语义规则
语义规则也是属性文法,对上下文无关文法做的一个扩充。每个产生式应该配备的语义规则,要说明该产生式中出现的语法符号的对应的属性的计算方法,以表达这个产生式所对应的语法结构的意义。
语义规则是描述该产生式中出现的语法符号的属性之间的相互关系,是以函数计算的方式体现。
注意:
(1)语义规则可能产生副作用(如产生代码),
(2)也可能是过程,不是严格的函数(即不一定有返回值)
带注释的语法树
在语法树中:
- 一个结点的综合属性的值由其子结点和它本身的属性值确定
- 一个结点的继承属性由其父结点、其兄弟结点和其本身的某些属性确定
- 用继承属性来表示程序涉及语言结构中的上下文依赖关系很方便
使用自底向上的方法在每一个结点处使用语义规则计算综合属性的值
属性计算
语义规则的计算:
- 产生代码
- 在符号表中存放信息
- 给出错误信息
- 执行任何其它动作
对输出串的翻译就是根据语义规则进行计算
在属性文法的基础上进行处理
输入串语法树->依赖图->语义规则计算次序->计算结果
这种由源程序的语法结构所驱动的处理办法就是语法制导翻译法。
基于属性文法的处理方法
依赖图
在一颗语法树中的结点的继承属性和综合属性之间的相互依赖关系可以用称作依赖图的一个有向图来描述。依赖图可以确定属性计算的先后顺序。
依赖图中为每一个属性设置一个结点,如果属性b依赖于属性c,则从属性c的结点有一条有向边连到属性b的结点。
良定义的属性文法
如果一属性文法不存在属性之间的循环依赖关系,那么该文法为良定义的。为了设计编译程序,我们只处理良定义的属性文法。
一个依赖图的任何拓扑排序都给出一个语法树中结点的语义规则计算的有效顺序。
属性的计算次序
一个有向非循环图的拓扑序是图中结点的任何顺序m1,m2, …mk,使得边必须是从序列中前面的结点指向后面的结点。也就是说,如果mimj是mi到mj的一条边,那么在序列中mi必须出现在mj之前。
一个依赖图的任何拓扑排序都给出一个语法树中结点的语义规则计算的有效顺序。这就是说,在拓扑排序中,在一个结点上,语义规则b:=f(c1,c2,…ck)中的属性c1,c2…ck在计算b以前都是可用的。
树遍历的属性计算方法
通过树遍历的方法计算属性的值
- 假设语法树已经建立,且树中带有开始符号的继承属性和终结符的综合属性
- 以某种次序遍历语法树,直至计算出所有属性
- 深度优先,从左到右进行遍历
- 基于递归
输入串->语法树->遍历语法树计算属性
一遍扫描的处理方法
与语法分析方法相关,将属性计算穿插在语法分析的过程中进行。
产生语法结构的顺序决定了属性计算的顺序。【语法制导的思想】
所谓的语法制导翻译法,直观上说就是为文法中每个产生式配上一组语义规则,并且在语法分析的同时执行这些语义规则。
- 在自上而下分析,一个产生式匹配输入串成功时,就执行相应的语义规则
- 在自下而上分析,一个产生式被归约时,就执行相应的语义规则
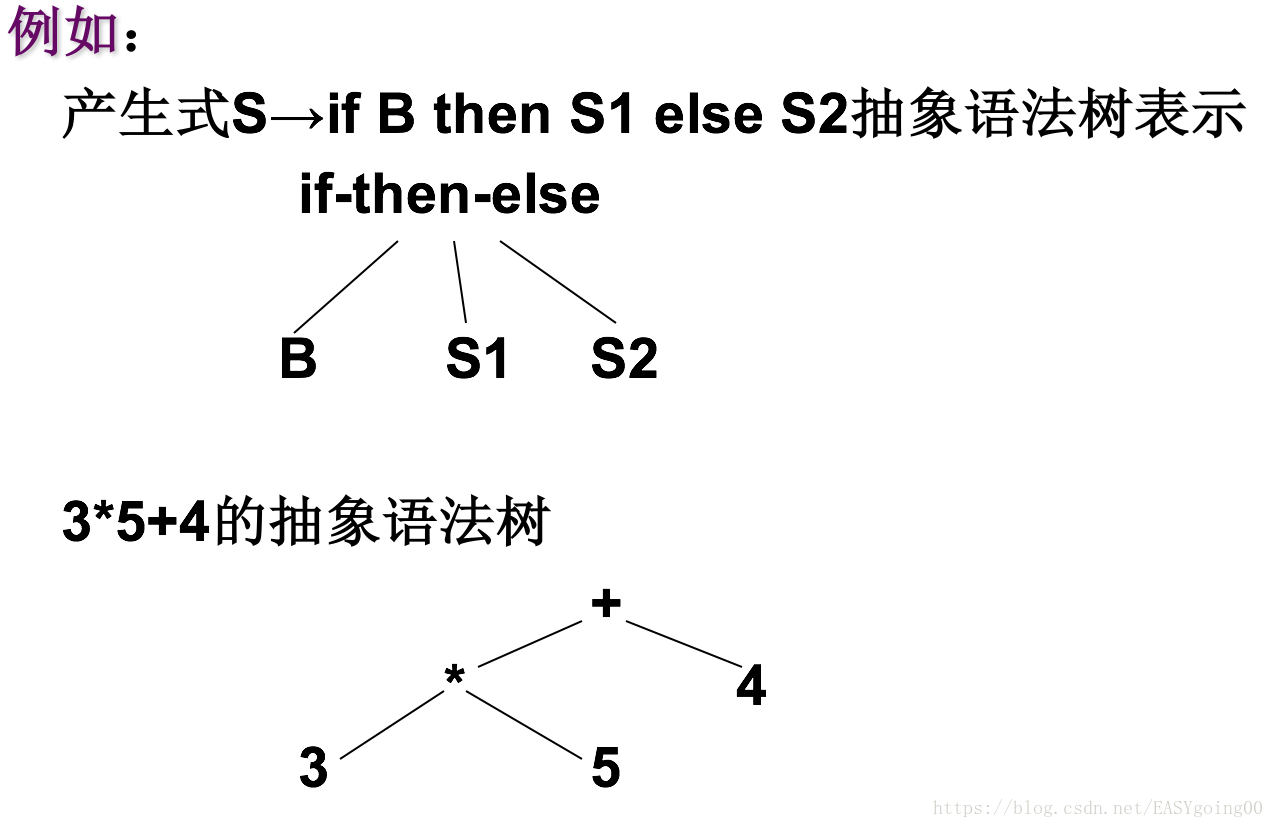
抽象语法树
从语法树中去掉对翻译不必要的信息,而获得更有效的源程序中间表示。
这种经变换后的语法树称之为抽象语法树(Abstract Syntax Tree)。
在抽象语法树中,操作符和关键字都不作为叶结点出现,而是把它们作为内部结点,即这些叶结点的父结点。
S-属性文法的自下而上计算
s-属性文法:只含有综合属性
在自下而上的分析器分析输入符号串的同时计算综合属性
- 分析栈中保存语法符号和有关的综合属性值
- 每当进行归约时,新的语法符号的属性值由栈中正在归约的产生式右边符号的属性值进行计算
实现
原来自下而上分析栈一般只保存状态和语法符号。
现在,我们在分析栈中增加附加域存放综合属性值。
L-属性文法的自顶向下翻译
按照深度优先遍历语法树,计算所有属性值
与LL(1)自上而下分析方法结合
- 深度优先建立语法树
- 按照语义规则计算属性
翻译模式
语义规则:给出了属性计算的定义,没有属性计算的次序等实现细节。所以,我们得通过依赖图、树遍历等方法确定属性计算的顺序。
翻译模式:给出使用语义规则进行计算的次序,把实现细节表现出来
(1)在翻译模式中,和文法符号相关的属性和语义规则用花括号括起来,插入到产生式右部的合适位置上,可被插入到产生式右部的任何合适的位置上。
(2)这是一种语法分析和语义动作交错的表示法,他表达在按深度优先遍历分析树的过程中何时执行语义动作。
(3)翻译模式给出了使用语义规则进行计算的顺序。可看成是分析过程中翻译的注释。
设计翻译模式(根据语法制导定义)
条件:语法制导定义是L-属性定义
保证语义动作不会引用还没有计算的属性值。【必须保证当某个动作引用一个属性时它必须是有定义的】
只需要综合属性的情况
为每一个语义规则建立一个包含赋值的动作,并把这个动作放在相应的产生式右边的末尾。
例如:
产生式:T->T1*F
语义规则:T.val:=T1.valxF.val
翻译模式:T->T1*F {T.val:=T1.valxF.val}
因为父节点的综合属性的值只依赖于子节点,把综合属性的值计算放在最右边,它的子节点已经扩展完毕了。我们也就得到子节点的属性值
既有综合属性又有继承属性的情况
要求:
①产生式右边的符号的继承属性必须在这个符号以前的动作中计算出来。
②一个动作不能引用这个动作右边符号的综合属性。
③产生式左边非终结符号的综合属性只有在它所引用的所有属性都计算出来以后才能计算。计算这种属性的动作通常可放在产生式右端的未尾。
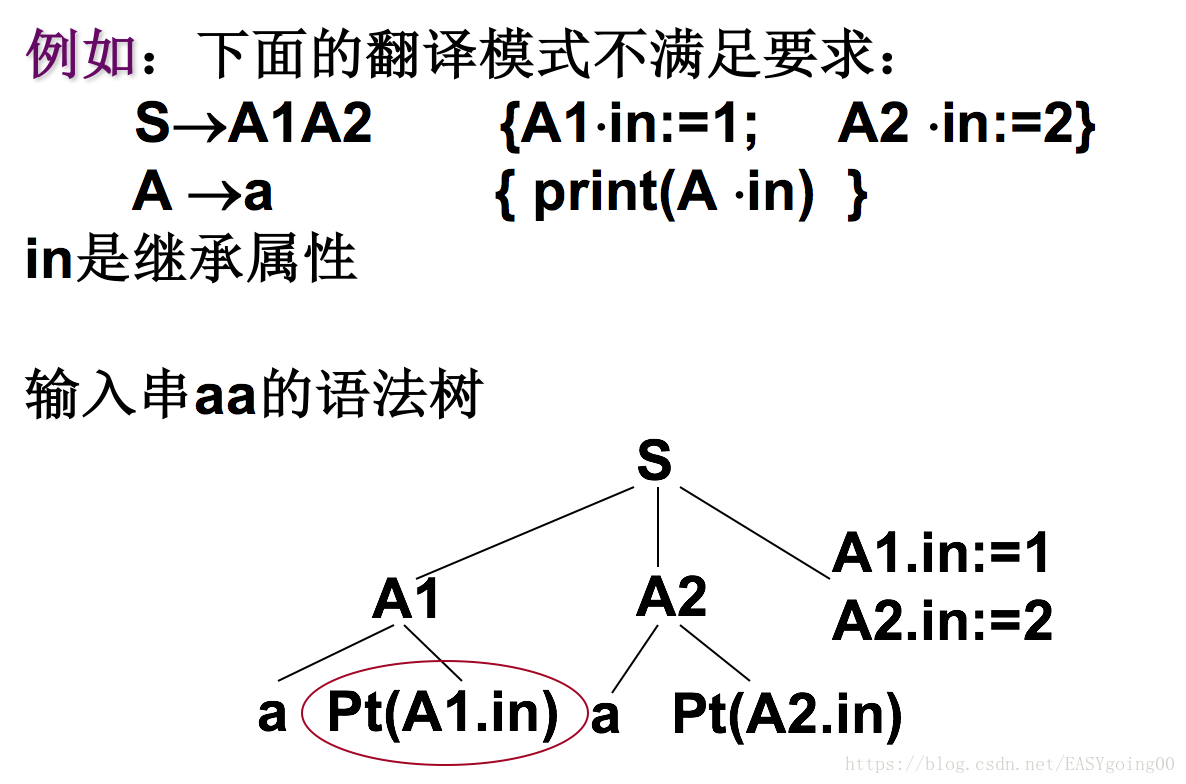
此时Pt(A1.in)是不好的,这个翻译模式不对。因为A1.in还没有出来(在最右边)
改进翻译模式:
S->{A1.in:=1}A1{A2.in:=2}A2 A->a{print(A.in)}
语义动作执行时机统一
把所有的语义动作都放在产生式的末尾
语义动作的执行时机统一
转换方法
- 加入新产生式M->ε
- 把嵌入在产生式中的每个语义动作用不同的非终结符M代替,并把这个动作放在产生式M->ε的末尾
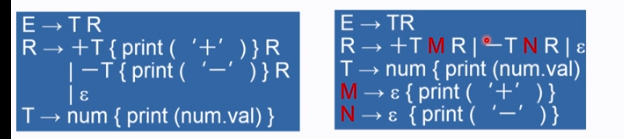
消除翻译模式的左递归
语义动作是在相同位置上的符号被展开(匹配成功)时执行的。为了构造不带回溯的自顶向下语法分析,必须消除文法中的左递归
当消除一个翻译模式的基本文法的左递归时同时考虑属性计算
- 适合带综合属性的翻译模式