存储系统性能量化分析
存储器越靠近CPU,则CPU对它的访问频度越高,但是容量也越低,单位存储容量价格越高。
存储容量S:一般来说,整个存储系统的容量即是第二级存储器M2 ,即S=S2
命中率H:CPU访问存储系统时,在M1 中找到所需信息的概率$H=\frac{N_1}{N_1+N_2}$
平均访问时间TA :
当命中时,访问时间即是T
1(命中时间)当没命中时,$T_2+T_1+T_B=T_1+T_M\T_m=T_2+T_B\传递一个信息块所需的时间为T_B\不命中开销T_M:从向M_2发出访问请求到整个数据块调入M_1中所需的时间$
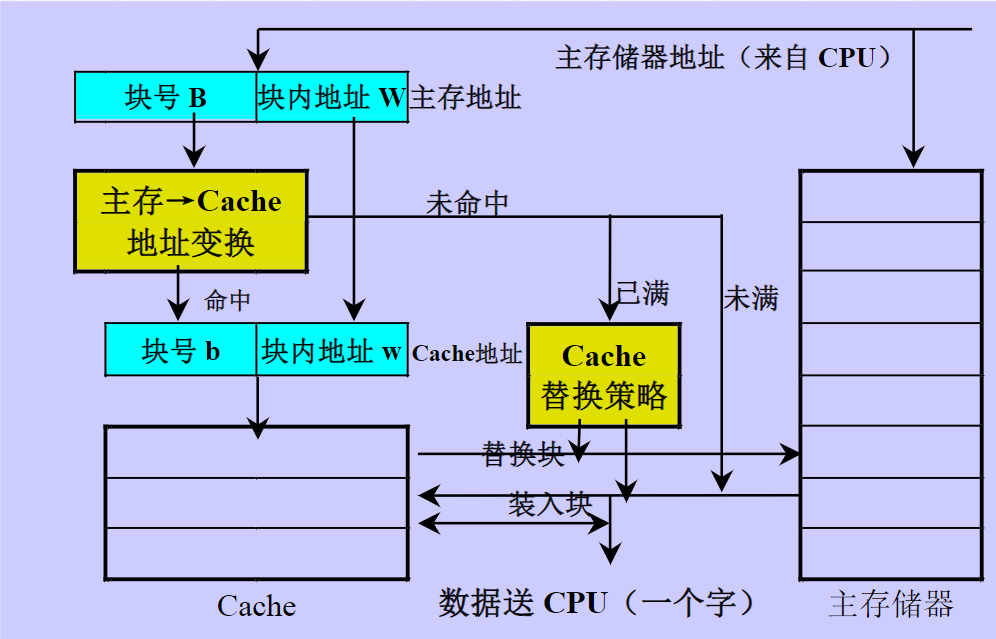
Cache基本知识
Cache-利用局部性原理,加快经常性事件原理,将程序和数据放到与CPU速度匹配的高速存储器中。
cache关注的四个问题:
如何放
- 全相联映象
- 直接映象
- 组相联映象
如何找
如何写
- 写穿:写cache的同时也在写内存
- 写回:只写cache,只有被替换时才写回内存
如何换
- 轮换法
- LRU算法
具体见《组原原理》
映象规则及其变换
见《组成原理》
降低cache不命中率
三种类型的不命中
- 强制性不命中:当第一次访问一个块时,该块不在cache中,需从下一级存储器中调入cache。(冷启动不命中,首次访问不命中。)
- 容量不命中:如果程序执行时所需的块不能全部调入cache中,则当某些块被替换后,若重新被访问,就会发生不命中。
- 冲突不命中:在组相联或者直接映象cache中,如果太多的块映象到同一组(块)中,则该组中某个块被别的块替换(即使别的组或块有空闲位置),然后又被重新访问的情况。(碰撞不命中,干扰不命中)
特点
- 相联度越高,冲突不命中就越少;
- 强制性不命中和容量不命中不受相联度的影响
- 强制性不命中不受cache容量的影响,但是容量不命中却随着容量的增加而减少
减少三种不命中的方法
- 强制性不命中:增加块大小,预取
- 容量不命中:增加容量
- 冲突不命中:提高相关度
许多降低不命中率的方法会增加命中时间或不命中开销
增加cache块的大小
对于给定的cache容量,当块大小增加时,不命中率开始是下降的,但是后来就上升了。
- 一方面它减少了强制性不命中;
- 另一方面,由于增加块大小会减少Cache中块的数目,可能会增加冲突不命中
增加块的大小会增加不命中开销
增加cache的容量
缺点:
- 增加成本
- 增加命中时间
提高相联度
采取相联度超过8的方案实际意义不大
容量为N的直接映象cache的不命中率和容量为N/2的两路组相联cache的不命率差不多相同
提高相联度是以增加命中时间为代价的
伪相联cache和列相联cache
基本思想:在逻辑上把直接映象cache分为上下两个区。对于任何一次访问,伪相联cache先按直接映象cache的方式去处理:如果命中,则其访问过程和直接映象cache的情况一样;如果不命中,则再对另一区相应的位置去查找。如果找到了,则发生了伪命中,否则只好访问下一级存储器。

硬件预取
- 指令和数据都可以预取
- 预取内容即可放入cache中,也可放在外缓冲器中
- 指令预取通常由cache之外的硬件完成
预取应利用存储器的空闲带宽,不能影响对正常不命中的处理,否则会降低性能。
编译器控制的预取
在编译的时候加入预取指令,在数据被用到之前发出预取请求。
- 按照预取数据所放的位置,可把预取分为两种类型:
- 寄存器预取:把数据放在寄存器中
- cache预取:只将数据放在cache中
- 按照预取的处理方式不同,分为:
- 故障性预取:在预取时,如果出现虚地址故障或违反保护权限,就会发生异常
- 非故障性预取:不会发生异常,编译器会放弃预取,转为空操作
- 在预取数据的同时,处理器应能继续执行
- 编译器控制预取的目的:使得执行指令和读取数据能重叠执行
- 每次预取需要花费一条指令的开销
- 保证开销低于收益
- 编译器可以通过把重点放在那些可能会导致不命中的访问上,使得程序避免不必要的预取
编译器优化
通过对软件进行优化来降低不命中率
- 程序代码和数据重组
- 重新组织程序而不影响程序的正确性
- 把一个程序的过程重新排序,减少冲突不命中,降低指令不命中率
- 把基本块对齐,提高大cache块的效率
- 假设编译器知道分支指令会成功转移:
- 将转移目标处的基本块和紧跟着该分支指令后的基本块进行对调
- 把该分支指令转为操作语义相反的分支指令(?)
- 重新组织程序而不影响程序的正确性
牺牲cache
在cache和它的下一级存储器之间设置一个全相联的小cache;用来存放被替换出去的块(牺牲者),以备重新使用
对于减小冲突不命中很有效,特别是对于小容量的直接映象数据cache,作用尤其明显。
采取两级cache
第一级cache小且快;第二级cache容量大。
全部不命中率和局部不命中率:$全局不命中率=不命中率_{L1} X 不命中率_{L2}$
评价第二级Cache需要使用全局不命中率;
第二级cache不会影响CPU的时钟频率;
$平均访存时间=命中时间L_1+不命中率L_1X()$
参数
- 容量:第二级cache的容量一般比第一级cache的大很多
- 相联度:第二级cache可以采用较高的相联度或伪相联方法
- 块大小:第二级cache可以采用较大的块
让读不命中优先于写
- cache中的写缓冲器导致对存储器访问的复杂化:在读不命中时,所读单元的最新值可能还在写缓冲器中,还没有进入主存。
- 读不命中的处理:
- 推迟对读不命中的处理,直到写缓冲器清空
- 检查写缓冲器的内容
- 在写回法cache中,可采取写缓冲器
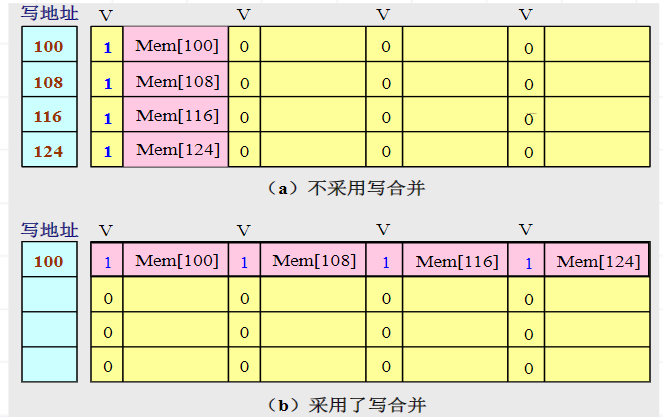
写缓冲合并
写直达cache:
依靠写缓冲来减少对下一级存储器写操作的时间。
如果写缓冲器为空,就把数据和相应地址写入该缓冲器【从CPU的角度来看,该写操作就算完成了】
如果写缓冲器中已经有了待写入数据,就要把这次写入地址与写缓冲器中已有的所有地址进行比较,看看是否有匹配的项。如果有地址匹配而对应的位置又空闲,就把这次要写入的数据与该项合并。【这就是写缓冲合并】
如果写缓冲器满并且没有能进行写合并的项,就等待。
请求字处理技术
请求字:从下一级存储器调入cache块中,只有一个字是立即需要的,该字就是请求字。
应尽早把请求字发送给CPU
- 尽早重启动:调块时,从块的起始位置开始读起。一旦请求字到达了,就立即发送给CPU,让CPU继续执行。【请求字优先】
非阻塞cache技术
cache不命中时依旧允许CPU进行其他的命中访问。
减少命中时间
命中时间直接影响处理器的时钟频率。
Cache的访问时间限制了处理器的时钟频率。
容量小、结构简单的Cache
硬件越简单,速度就越快。
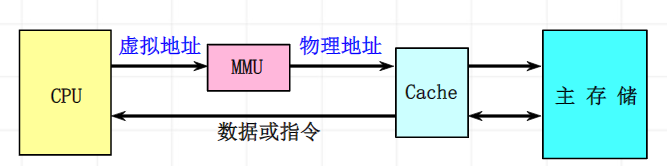
虚拟cache
物理cache
使用物理地址进行访问的传统cache。
标识存储器中存放的是物理地址,进行地址检测越是用物理地址。
缺点就是:地址转换和访问cache串行进行,访问速度慢。
虚拟cache
直接使用虚拟地址进行访问的cache。标识存储器存放的是虚拟地址,进行地址检测用的也是虚拟地址
优点:在命中时不需要进行地址转换,省去了地址转换的时间。就算是不命中,地址转换和访问cache也是并行进行的,速度比物理cache快。
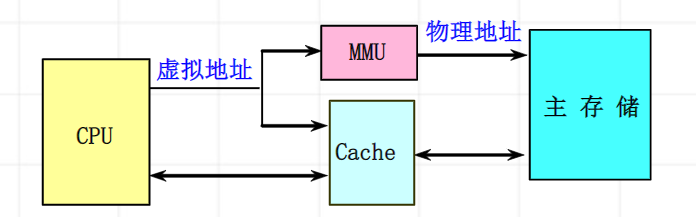
虚拟地址和进程相关。
虚拟地址=虚拟索引+物理标识
用虚地址中页内位移作为cache的索引,标识用物理地址;

Cache访问流水化
对第一级cache访问按流水线方式组织
访问cache需要多个时钟周期才能完成
不能够真正减少cache命中时间,但是可以提高时钟频率,提高cache的带宽。
踪迹Cache
存放CPU所执行的动态指令序列:包含了由分支预测展开的指令,该分支预测是否需要在取到该指令时进行确认。
- 地址映象机制复杂
- 相同的指令序列有可能被当作条件分支的不同选择而重复存放
- 能够提高指令cache的空间利用率
并行主存系统
主存的主要性能指标:延迟和带宽
定义:是在一个访存周期内能并行访问多个存储字的存储器
在单体单字宽的存储器中:存储器的访问周期为TM ,字长为W位,则
带宽为$B_M=\frac{W}{T_M}$
单体多字存储器
存储器能够每个存储周期读出m个CPU字
$B_M=\frac{mW}{T_M}$
单体多字存储器的实际带宽比最大带宽小
缺点:访存效率不高
- 如果一次去读的m个指令字中有分支指令,而且分支成功,则该分支指令之后的指令是无用的。
- 一次取出的m个数据不一定都是有用的。此外,当前执行指令所需要的多个操作数也不一定正好都存放在同一个长存储字中
- 写入可能变得复杂
- 当要读出的数据字和要写入的数据字处于同一个长存储字内时,读和写的操作就无法在同一个存储周期内完成
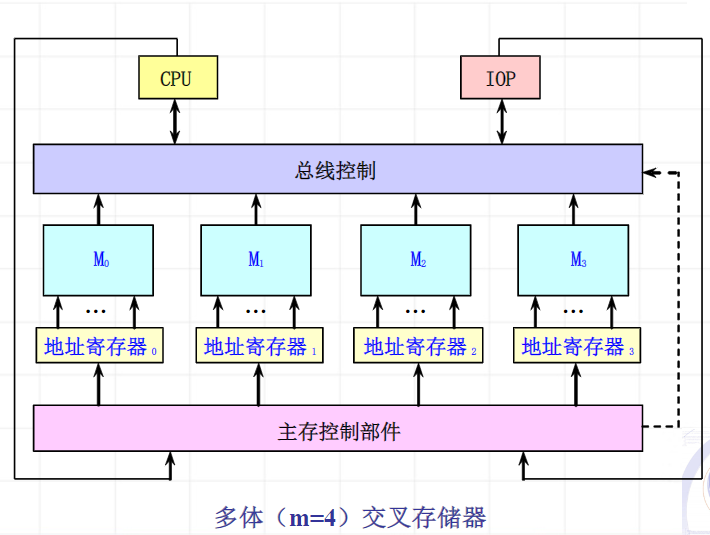
多体交叉存储器
由多个单字存储体构成,每个体都有自己的地址寄存器以及地址译码和读/写驱动等电路。
编址方式:
- 高位交叉编址
- 低位交叉编址
高位交叉编址
对存储单元矩阵按列优先的方式进行编址
低位交叉编址
对存储单元矩阵按行优先进行编址
虚拟存储器
进程保护:
- 界地址寄存器:基地址、上界地址;检测条件:(基地址+地址)<=上界地址
- 虚拟存储器:给每个页面增加访问权限标识
- 环形保护
- 加锁和解锁