编译原理概述
编译程序
编译程序是现代计算机系统的基本组成部分。
- 功能上:一个编译程序就是一个语言翻译程序。把源语言翻译成目标语言。
- 目的:让程序员不需要考虑机器的细节。
需要处理的源程序—(预处理器)—源程序—(编译程序)—-目标汇编程序—(汇编程序)—可再装配的机器代码—(装配连接编辑)—绝对机器码
编译过程

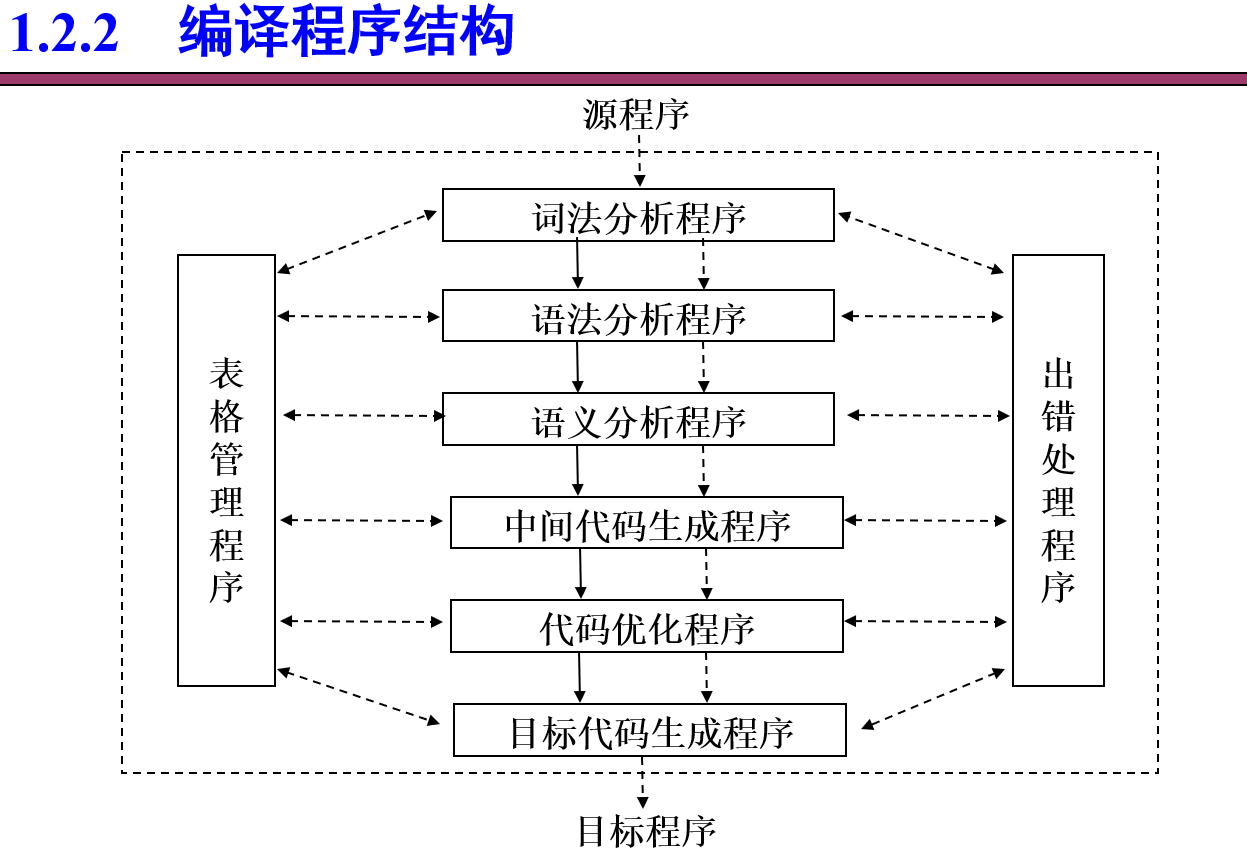
编译过程的阶段是一种逻辑上的划分:
- 划分“前端/后端”。 将与仅依赖于源程序而与目标机器(硬件)无关的阶段组合成前端,将与目标机器(硬件)相关的阶段组合成后端。
- 前端:语法分析程序、语义分析程序
- 后端:中间代码生成程序、代码优化程序、目标代码生成程序
- 划分“遍”。从头到尾扫描一遍输入串称谓遍。每遍可以完成编译的若干阶段的编译任务。
词法分析(扫描)
语法分析器读入组成源程序的字符流,并且将它们组织成为有意义的词素的序列。<token-name,attribute-value>
token-name是一个由语法分析步骤使用的抽象符号;attribute-value指向符号表中关于这个词法单元的条目。符号表条目的信息会被语义分析和代码生成步骤使用。
单词符号:
- 常数
- 保留字
- 标识符
- 运算符
- 界符等类型(例如:空格、括号···)
语法分析(解析)
语法分析器使用由词法分析器生成的各个词法单元的第一个分量来创建树形的中间表示。该中间表示给出了词法分析产生的词法单元流的语法结构。
功能:层次分析,依据源程序的语法规则把源程序的单词序列组成语法短语(表示成语法树)
语法树中的每个内部结点表示一个运算,而该结点的子结点表示该运算的分量。
语义分析
语义分析器使用语法树和符号表中的信息来检查源程序是否和语言定义的语义一致。同时收集类型信息,并且将这些信息存放在语法树或符号表中,方便在随后的中间代码生成过程中使用。
类型检查:检查每个运算符是否具有匹配的运算分量(例如:要求的数组是一个整数,但是给定的是一个浮点数,编译器就会报错)
中间代码生成
在源程序的语法分析和语义分析完成后,很多编译器生成一个明确的低级的或类机器语言的中间表示。可以把这个表示看作是某个抽象机器的程序(应具有两个性质:易于生成、易于翻译成目标机器的语言。)
代码优化
机器无关的代码优化步骤试图改进中间代码,以便生成更好的目标代码。
符号表管理
记录源程序中使用的各种符号名称
收集每个符号的各种名称的属性信息
类型、作用域、分配存储信息
符号表管理()
- 登录:扫描到说明语句就将标识符登记在符号表中
- 查找:在执行语句查找标识符的属性,判断语义是否正确
错误检查
报告出错信息
排错
恢复编译工作
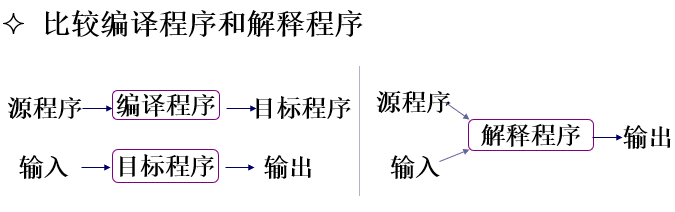
编译方式和解释方式
采用编译方式的编译程序称为编译型的编译程序,简称编译程序;采用解释方式的编译程序称为解释型的编译程序,简称解释程序。
编译方式是先翻译后执行,即将整个源程序翻译完毕,再执行目标程序,只需要保存完整的目标程序而无需保存源程序。一次翻译后无需再翻译,可多次执行。
解释方式是边翻译边执行,即翻译一句就执行一句,翻译完毕也执行完毕,只保存源程序无需保存完整的目标程序。执行一次需要翻译一次。**
解释程序
- 不产生目标程序文件
- 不区别翻译阶段和执行阶段
- 翻译源程序的每条语句后直接执行
- 程序执行期间一直有解释程序守候
- 常用于实现虚拟机
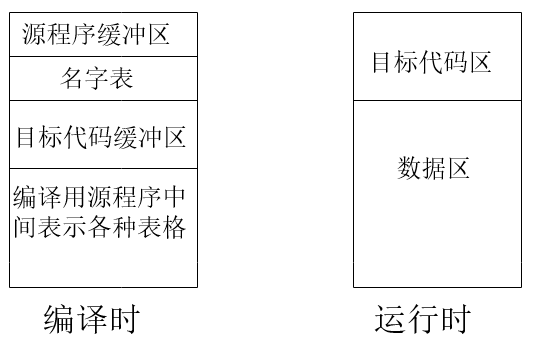
存储组织不同
编译程序处理时,在源语言程序被编译阶段,存储区中要为源程序(中间形式)和目标代码开辟空间,要存放编译用的各种各样表格,比如符号表.在目标代码运行阶段,存储区中主要是目标代码和数据,编译所用的任何信息都不再需要.
解释程序一般是把源程序一条语句一条语句的进行语法分析,转换为一种内部表示形式,存放在源程序区,比如BASIC解释程序,将LET和GOTO这样的关键字表示为一个字节的操作码,标识符用其在符号表的入口位置表示.因为解释程序允许在执行用户程序时修改用户程序,这就要求源程序,符号表等内容始终存放在存储区中,并且存放格式要设计的易于使用和修改.