贪心算法
贪心算法是这样一种方法:分步骤实施,它在每一步仅作出当时看起来最佳的选择,即局部最优的选择,并希望通过这样的选择最终能找到全局最优解。
贪心算法没有固定的算法框架,算法设计的关键是贪心策略的选择。必须注意的是,贪心算法不是对所有问题都能得到整体最优解,选择的贪心策略必须具备无后效性(即某个状态以后的过程不会影响以前的状态,只与当前状态有关。)
所以,对所采用的贪心策略一定要仔细分析其是否满足无后效性。
最优解问题大部分都可以拆分成一个个的子问题,把解空间的遍历视作对子问题树的遍历,则以某种形式对树整个的遍历一遍就可以求出最优解,大部分情况下这是不可行的。贪心算法和动态规划本质上是对子问题树的一种修剪,两种算法要求问题都具有的一个性质就是子问题最优性(组成最优解的每一个子问题的解,对于这个子问题本身肯定也是最优的)。动态规划方法代表了这一类问题的一般解法,我们自底向上构造子问题的解,对每一个子树的根,求出下面每一个叶子的值,并且以其中的最优值作为自身的值,其它的值舍弃。而贪心算法是动态规划方法的一个特例,可以证明每一个子树的根的值不取决于下面叶子的值,而只取决于当前问题的状况。换句话说,不需要知道一个节点所有子树的情况,就可以求出这个节点的值。由于贪心算法的这个特性,它对解空间树的遍历不需要自底向上,而只需要自根开始,选择最优的路,一直走到底就可以了。
对比动态规划方法:
在动态规划方法中,每个步骤也都要进行一次选择,但这种选择通常依赖于子问题的解,这导致我们要先求解较小的子问题,然后才能计算较大的子问题。
在贪心方法中,我们总是做出当前看来最佳的选择,然后求解剩下的唯一一个子问题。尽管贪心算法进行选择时可能依赖之前做出的选择,但不依赖任何将来的选择或子问题的解。
动态规划要先求解子问题才能进行选择,贪心算法在进行第一次选择之前不需要求解任何子问题。
动态规划算法通常采用自底向上的方式完成计算,而贪心算法通常是自顶向下的,每一次选择,将给定的问题转换成一个更小的问题,然后继续求解小问题
贪心算法的步骤
贪心算法通常采用自顶向下的设计,做出一个选择,然后求解剩下的子问题。每次选择将问题转化成一个更小规模的问题。
确定问题的最优子结构
将最优化问题转化为这样的形式:每次对其作出选择后,只剩下一个子问题需要求解;
证明作出贪心选择后,剩余的子问题满足:其最优子解与前面的贪心选择组合即可得到原问题的最优解(具有最优子结构)。
注:对应每个贪心算法,都有一个动态规划算法,但动态规划算法要繁琐的多。
贪心算法存在的问题
- 不能保证求得的最后解是最佳的
- 不能用来求最大值或最小值的问题
- 只能求满足某些约束条件的可行解的范围
贪心算法适用的问题
贪心策略适用的前提是:局部最优策略能导致产生全局最优解。
实际上,贪心算法适用的情况很少。一般对一个问题分析是否适用于贪心算法,可以先选择该问题下的几个实际数据进行分析,就可以做出判断。
活动选择问题
有n个需要在同一天使用同一个教室的活动a1,a2,…,an,教室同一时刻只能由一个活动使用。每个活动ai都有一个开始时间si和结束时间fi 。一旦被选择后,活动ai就占据半开时间区间[si,fi)。如果[si,fi]和[sj,fj]互不重叠,ai和aj两个活动就可以被安排在这一天。
活动选择问题:就是对给定的包含n个活动的集合S,在已知每个活动开始时间和结束时间的条件下,从中选出最多可兼容活动的子集合,称为最大兼容活动集合。不失一般性,设活动已经按照结束时间单调递增排序:
$$
f1<=f2<=f3<=f4<=…<=fn-1<=fn
$$
活动选择问题的最优子结构
令Sij表示在ai结束之后开始且在aj开始之前结束的那些活动的集合。
问题和子问题的形式定义如下:设Aij是Sij的一个最大兼容活动集,并设Aij包含活动ak,则有:Aik表示Aij中ak开始之前的活动子集,Akj表示Aij中ak结束之后的活动子集。并得到两个子问题:寻找Sik的最大兼容活动集合和寻找Skj的最大兼容活动集合。
活动选择问题具有最优子结构性,即:必有:Aik是Sik一个最大兼容活动子集,Akj是Skj一个最大兼容活动子集。而Aij= Aik∪{ak}∪Akj。——最优子结构性成立。
活动选择问题的动态规划方法
$$
c[i,j]表示集合s_{ij}的最优解大小,递归式如下:\
c[i,j]=c[i,k]+c[k,j]+1\
c[i,j]=\begin{cases}
0,\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ if\quad S_{ij}=\Phi\
\max\limits_{a_k\in S_{ij}}(c[i,k]+c[k,j]+1)\ \ if\quad S_{ij}\not=\Phi
\end{cases}
$$
活动选择问题的贪心算法
活动选择问题的贪心选择:每次总选择具有最早结束时间的兼容活动加入到集合A中。
直观上,按这种方法选择兼容活动可以为未安排的活动留下尽可能多的时间。也就是说,该算法的贪心选择的意义是使剩余的可安排时间段最大化,以便安排尽可能多的兼容活动。
贪心算法的正确性
假设Aij是Sij的某个最大兼容活动集,假设Aij中,最早结束的活动是an,分两种情况:
1、如果an=ai ,得证
2、如果an!= ai ,则an的结束时间一定会晚于a1的结束时间,我们用ai去替换Aij中的an,于是得到A^1^,由于ai比an结束的早,而Aij中的其他活动都比an的结束时间开始 的要晚,所以A^1^中的其他活动 都与ai不想交,所以A^1^中的所有活动是兼容的,所以A^1^也是Sij的一个最大兼容活动集。
贪心算法的递归实现
自顶向下的设计
1 | //s、f数组分别表示n个活动的开始时间和结束时间,假设n个活动已经按照结束时间单调递增排列好了 |
贪心算法的迭代实现
1 | public static List<Integer> GREEDY_ACTIVITY+SELECTOR(List<Integer> list,int[] s ,int[] f,int n) |
分数背包问题
已知n种物品,各具有重量(w1,w2,…,wn)和效益值(p1,p2,…,pn),及一个可容纳M重量的背包。
问:怎样装包才能使在不超过背包容量的前提下,装入背包的物品的总效益最大?
这里:
1)所有的wi>0, pi>0,1≤i≤n;
2)问题的解用向量(x1,x2,…,xn)表示,每个xi表示物品i被放入背包的比例,0≤xi≤1。当物品i的一部分xi放入背包,可得到pixi的效益,同时会占用xiwi的重量。
问题分析:
装入背包的总重量小于等于M,即:
$$
\sum_{1<=i<=n}W_iX_i<=M
$$$$
求\sum_{1<=i<=n}P_iX_i的最大值
$$可行解:满足上述约束条件的任一(x
1,x2,…,xn) 都是问题的一个可行解。可行解可能有多个(甚至是无穷多个)。最优解:能够使目标函数取最大值的可行解是问题的最优解。最优解也可能有多个。
贪心策略
这里我们需要思考:
1、策略一:以每装入一件物品,就使背包获得最大可能的效益增量作为策略
2、策略二:让背包容量尽可能慢地被消耗,从而可以尽可能多地装入一些物品。
3、如下的贪心策略
我们要设计一个贪心策略来使得装入背包物品的价值最大。我们的第一直觉肯定是要选择单位重量价格最高的。
然后再选择物品里面第二高的,一次类推直到装满背包为止!
证明
可以利用反证法求证策略一和策略二都不是最优解。
策略三:
需要注意的是Xi 的值是小于等于1的
我们首先假设我们有一个最优解A1,那么我们首先找到A1里面单位价值最高的物品am
- 情况一:a
m=商品里面单位价值最高的物品a1。那么问题得证(因为只要不断拿掉单位价值最高的即可) - 情况二:a
m<a1。运用剪枝技巧,讲am剪掉,补上a1(a1将am进行全部替换或者部分替换)- 如果a
m的重量比a1的重量小,a1全部替换am, - 如果a
m的重量比a1的重量大,a1部分替换am,其余部分保留
- 如果a
Huffman编码
其中变长编码表是通过一种评估来源符号出现机率的方法得到的,出现机率高的字母使用较短的编码,反之出现机率低的则使用较长的编码,这便使编码之后的字符串的平均长度、期望值降低,从而达到无损压缩数据的目的。
前缀码(Prefix code):任何码字都不是其它码字的前缀。
问题是:如何设计前缀码?
编码树
一种为表示字符二进制编码而构造的二叉树。
叶子结点:对应给定的字符,每个字符对应一个叶子结点。
编码构造:字符的二进制码字由根结点到该字符叶子结点的简单路径表示:0代表转向左孩子,1代表转向右孩子。
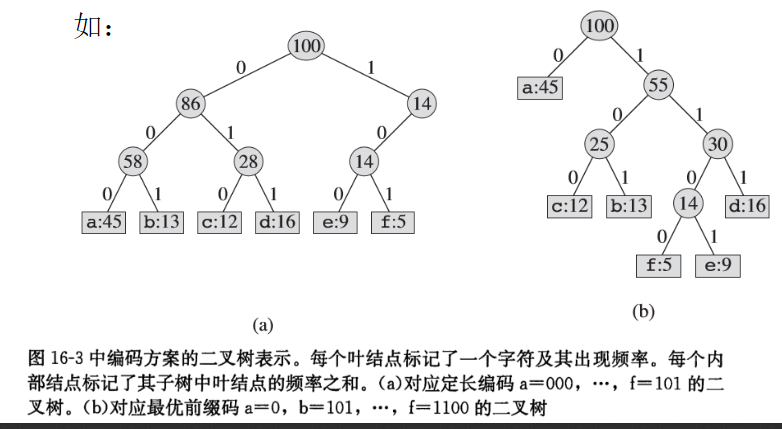
一个文件的最优字符编码方案总对应一棵满(full)二叉树,即每个非叶子结点都有两个孩子结点。
最优编码方案
文件的最优编码方案对应一棵满二叉树。
设C为字母表
- 对字母表C中的任意字符c,令属性c.freq表示字符c在文件中出现的频率(设所有字符的出现频率均为正数)。
- 最优前缀码对应的树中恰好有|C|个叶子结点,每个叶子结点对应字母表中的一个字符,且恰有|C|-1个内部结点。
令T表示一棵前缀编码树;
令d
T(c)表示c的叶子结点在树T中的深度(根到叶子结点的路径长度)。- d
T(c)也是字符c对应的码字的长度。
- d
令B(T)表示采用编码方案T时文件的编码长度,则:
$$
B(T)=\sum_{c\in C}c.freq*d_T(c)
$$
即文件要用B(T)个二进制位表示.
- 称B(T)为T的代价。
- 最优编码:对给定的字符集和文件,使文件的编码长度最小的编码称为最优编码。
- Huffman编码是一种最优编码。
Huffman编码的贪心算法
自底向上法
1 | HUFFMAN(C)//C表示字母表 |
时间分析
Q是使用最小二叉堆实现的。
首先,Q的初始化花费O(n)的时间。
其次,循环的总代价是O(nlgn)。
- for循环共执行了n-1次,每次从堆中找出当前频率最小的两个结点及把合并得到的新结点插入到堆中均花费O(lgn),所以循环的总代价是O(nlgn).
所以,HUFFMAN的总运行时间O(nlgn)
HUFFMAN算法的正确性
1、第一点:令C为一个字母表,其中每个字符c∈C都有一个频率c.freq。令x和y是C中频率最低的两个字符。那么存在C的一个最优前缀码,x和y的码字长度相同,且只有最后一个二进制位不同。
二叉树T表示字符集C的一个最优前缀码,证明可以对T作适当修改后得到一棵新的二叉树T”,在T”中x和y是最深叶子且为兄弟,同时T”表示的前缀码也是C的最优前缀码。设b和c是二叉树T的最深叶子,且为兄弟。设f(b)<=f(c),f(x)<=f(y)。由于x和y是C中具有最小频率的两个字符,有f(x)<=f(b),f(y)<=f(c)。首先,在树T中交换叶子b和x的位置得到T’,然后再树T’中交换叶子c和y的位置,得到树T’’。如图所示: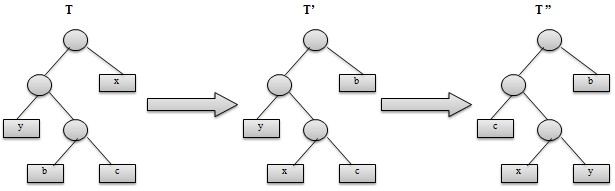
由此可知,树T和T’的前缀码的平均码长之差为:
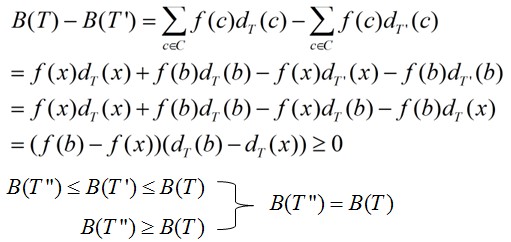
因此,T’’表示的前缀码也是最优前缀码,且x,y具有相同的码长,同时,仅最优一位编码不同。
2、第二点:令C为一个给定的字母表,其中每个字符c∈C都有一个频率c.freq。
令x和y是C中频率最低的两个字符。
令C’为C去掉字符x和y,并加入一个新字符z后得到的字母表,即C’= C -{x, y}∪{z}。
类似C,也为C’定义freq,且z.freq= x.freq+ y.freq。
令T’为字母表C’的任意一个最优前缀码对应的编码树。则有:可以将T’中叶子结点z替换为一个以x和y为孩子的内部结点,得到树T,而T表示字母表C的一个最优前缀码。
最优子结构性质
贪心选择性:
- 1、第一点说明首次选择频率最低的两个字符和选择其它可能的字符一样,都可以构造相应的最优编码树。
- 2、第二点说明首次贪心选择,选择出频率最低的两个字符x和y,合并后将z加入元素集合,可以构造包含z的最优编码树,而还原x和y,一样还是最优编码树。
- 所以贪心选择性成立。